 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanced Off-Policy Evaluation in General Action Spaces
Jun 13, 2019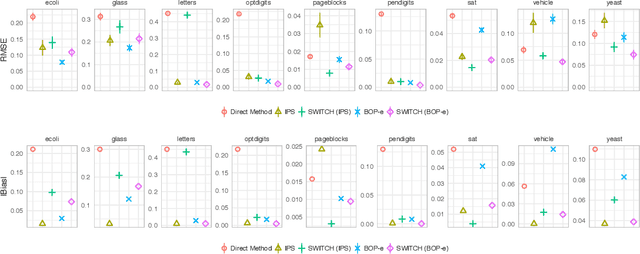

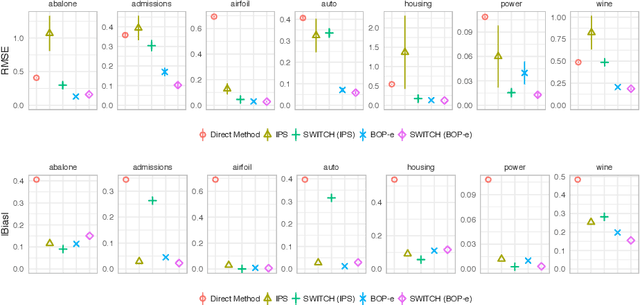
In many practical applications of contextual bandits, online learning is infeasible and practitioners must rely on off-policy evaluation (OPE) of logged data collected from prior policies. OPE generally consists of a combination of two components: (i) directly estimating a model of the reward given state and action and (ii) importance sampling. While recent work has made significant advances adaptively combining these two components, less attention has been paid to improving the quality of the importance weights themselves. In this work we present balancing off-policy evaluation (BOP-e), an importance sampling procedure that directly optimizes for balance and can be plugged into any OPE estimator that uses importance sampling. BOP-e directly estimates the importance sampling ratio via a classifier which attempts to distinguish state-action pairs from an observed versus a proposed policy. BOP-e can be applied to continuous, mixed, and multi-valued action spaces without modification and is easily scalable to many observations. Further, we show that minimization of regret in the constructed binary classification problem translates directly into minimizing regret in the off-policy evaluation task. Finally, we provide experimental evidence that BOP-e outperforms inverse propensity weighting-based approaches for offline evaluation of policies in the contextual bandit setting under both discrete and continuous action spaces.
Selective prediction-set models with coverage guarantees
Jun 13, 2019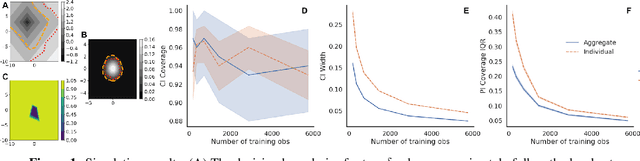
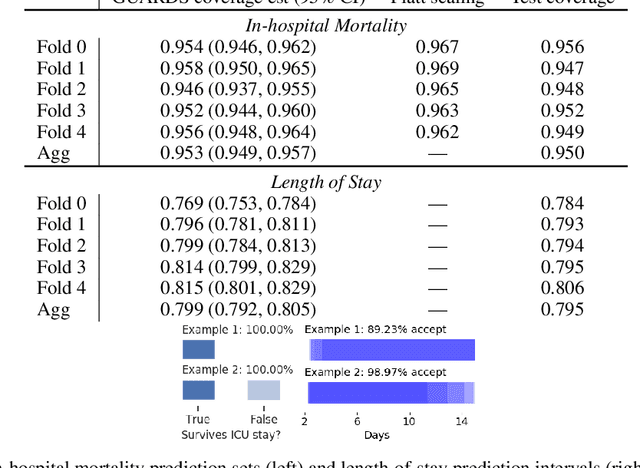

Though black-box predictors are state-of-the-art for many complex tasks, they often fail to properly quantify predictive uncertainty and may provide inappropriate predictions for unfamiliar data. Instead, we can learn more reliable models by letting them either output a prediction set or abstain when the uncertainty is high. We propose training these selective prediction-set models using an uncertainty-aware loss minimization framework, which unifies ideas from decision theory and robust maximum likelihood. Moreover, since black-box methods are not guaranteed to output well-calibrated prediction sets, we show how to calculate point estimates and confidence intervals for the true coverage of any selective prediction-set model, as well as a uniform mixture of K set models obtained from K-fold sample-splitting. When applied to predicting in-hospital mortality and length-of-stay for ICU patients, our model outperforms existing approaches on both in-sample and out-of-sample age groups, and our recalibration method provides accurate inference for prediction set coverage.
The Reduced PC-Algorithm: Improved Causal Structure Learning in Large Random Networks
Jun 16, 2018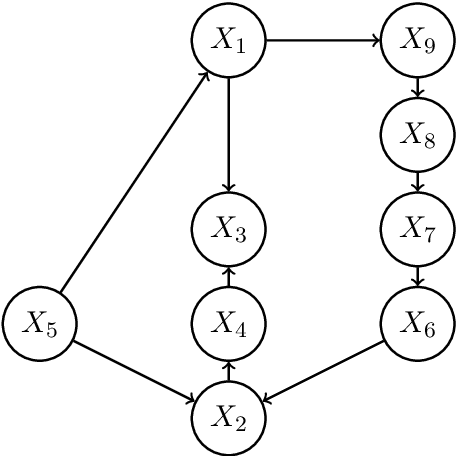
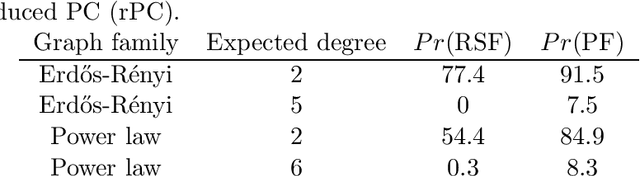


We consider the task of estimating a high-dimensional directed acyclic graph, given observations from a linear structural equation model with arbitrary noise distribution. By exploiting properties of common random graphs, we develop a new algorithm that requires conditioning only on small sets of variables. The proposed algorithm, which is essentially a modified version of the PC-Algorithm, offers significant gains in both computational complexity and estimation accuracy. In particular, it results in more efficient and accurate estimation in large networks containing hub nodes, which are common in biological systems. We prove the consistency of the proposed algorithm, and show that it also requires a less stringent faithfulness assumption than the PC-Algorithm. Simulations in low and high-dimensional settings are used to illustrate these findings. An application to gene expression data suggests that the proposed algorithm can identify a greater number of clinically relevant genes than current methods.