 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesh-Based Solutions for Nonparametric Penalized Regression
Dec 07, 2021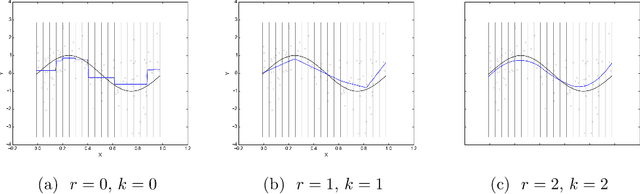
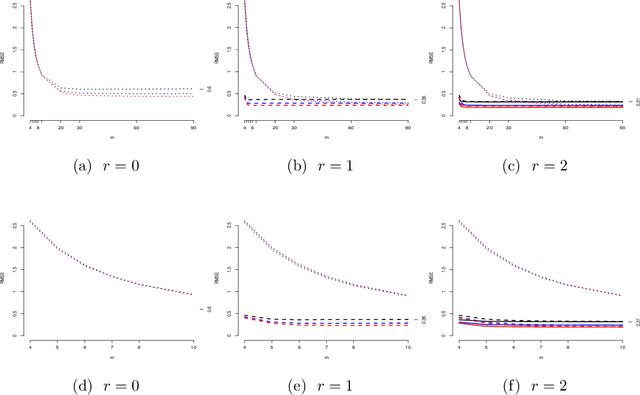
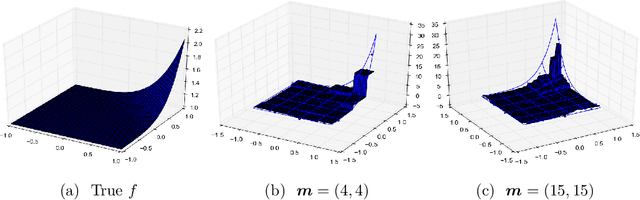
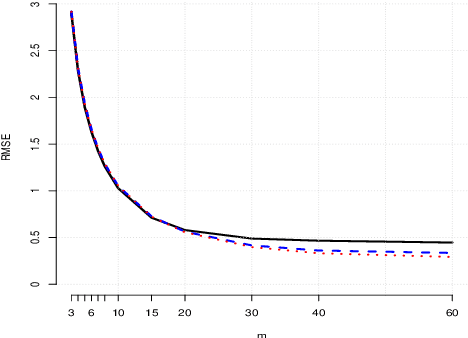
It is often of interest to estimate regression functions non-parametrically. Penalized regression (PR) is one statistically-effective, well-studied solution to this problem. Unfortunately, in many cases, finding exact solutions to PR problems is computationally intractable. In this manuscript, we propose a mesh-based approximate solution (MBS) for those scenarios. MBS transforms the complicated functional minimization of NPR, to a finite parameter, discrete convex minimization; and allows us to leverage the tools of modern convex optimization. We show applications of MBS in a number of explicit examples (including both uni- and multi-variate regression), and explore how the number of parameters must increase with our sample-size in order for MBS to maintain the rate-optimality of NPR. We also give an efficient algorithm to minimize the MBS objective while effectively leveraging the sparsity inherent in MBS.
The Future will be Different than Today: Model Evaluation Considerations when Developing Translational Clinical Biomarker
Jul 13, 2021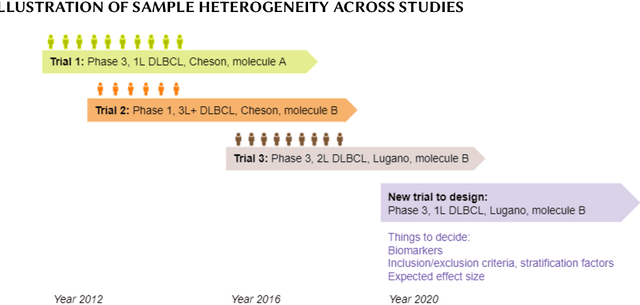


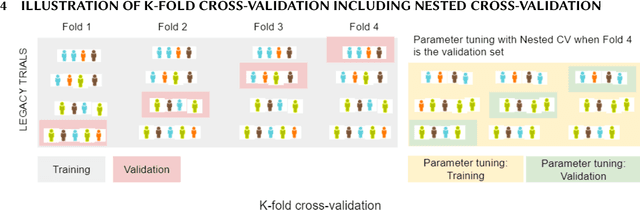
Finding translational biomarkers stands center stage of the future of personalized medicine in healthcare. We observed notable challenges in identifying robust biomarkers as some with great performance in one scenario often fail to perform well in new trials (e.g. different population, indications). With rapid development in the clinical trial world (e.g. assay, disease definition), new trials very likely differ from legacy ones in many perspectives and in development of biomarkers this heterogeneity should be considered. In response, we recommend considering building in the heterogeneity when evaluating biomarkers. In this paper, we present one evaluation strategy by using leave-one-study-out (LOSO) in place of conventional cross-validation (cv) methods to account for the potential heterogeneity across trials used for building and testing the biomarkers. To demonstrate the performance of K-fold vs LOSO cv in estimating the effect size of biomarkers, we leveraged data from clinical trials and simulation studies. In our assessment, LOSO cv provided a more objective estimate of the future performance. This conclusion remained true across different evaluation metrics and different statistical methods.
On the Optimality of Nuclear-norm-based Matrix Completion for Problems with Smooth Non-linear Structure
May 05, 2021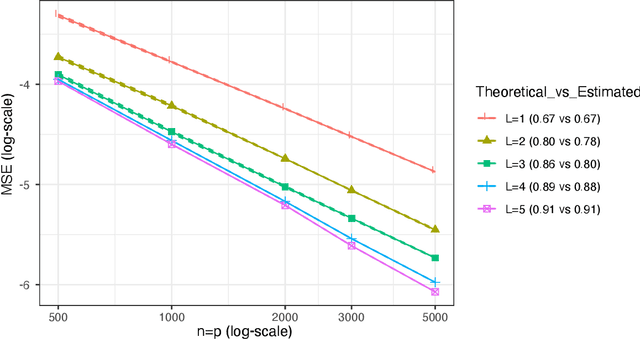
Originally developed for imputing missing entries in low rank, or approximately low rank matrices, matrix completion has proven widely effective in many problems where there is no reason to assume low-dimensional linear structure in the underlying matrix, as would be imposed by rank constraints. In this manuscript, we build some theoretical intuition for this behavior. We consider matrices which are not necessarily low-rank, but lie in a low-dimensional non-linear manifold. We show that nuclear-norm penalization is still effective for recovering these matrices when observations are missing completely at random. In particular, we give upper bounds on the rate of convergence as a function of the number of rows, columns, and observed entries in the matrix, as well as the smoothness and dimension of the non-linear embedding. We additionally give a minimax lower bound: This lower bound agrees with our upper bound (up to a logarithmic factor), which shows that nuclear-norm penalization is (up to log terms) minimax rate optimal for these problems.
Ensembled sparse-input hierarchical networks for high-dimensional datasets
May 11, 2020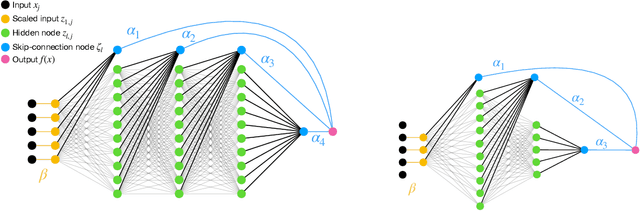


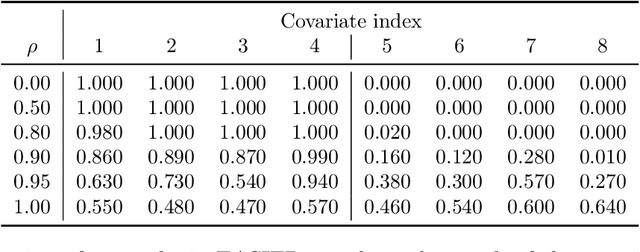
Neural networks have seen limited use in prediction for high-dimensional data with small sample sizes, because they tend to overfit and require tuning many more hyperparameters than existing off-the-shelf machine learning methods. With small modifications to the network architecture and training procedure, we show that dense neural networks can be a practical data analysis tool in these settings. The proposed method, Ensemble by Averaging Sparse-Input Hierarchical networks (EASIER-net), appropriately prunes the network structure by tuning only two L1-penalty parameters, one that controls the input sparsity and another that controls the number of hidden layers and nodes. The method selects variables from the true support if the irrelevant covariates are only weakly correlated with the response; otherwise, it exhibits a grouping effect, where strongly correlated covariates are selected at similar rates. On a collection of real-world datasets with different sizes, EASIER-net selected network architectures in a data-adaptive manner and achieved higher prediction accuracy than off-the-shelf methods on average.
Approval policies for modifications to Machine Learning-Based Software as a Medical Device: A study of bio-creep
Dec 28, 2019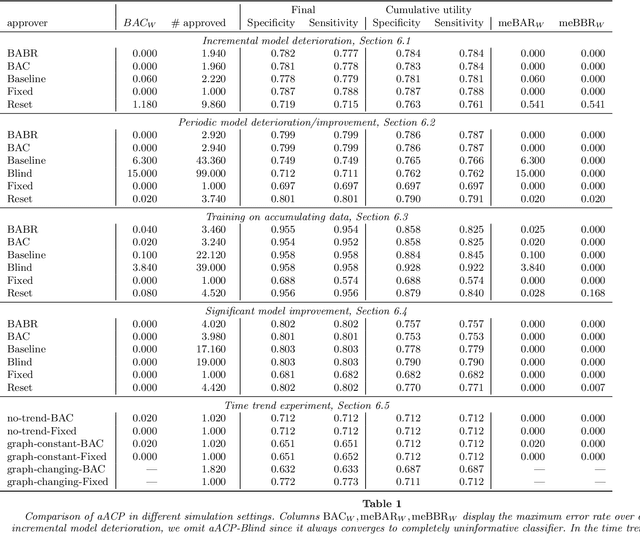


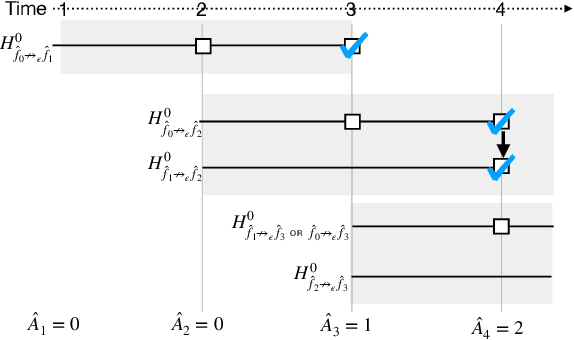
Successful deployment of machine learning algorithms in healthcare requires careful assessments of their performance and safety. To date, the FDA approves locked algorithms prior to marketing and requires future updates to undergo separate premarket reviews. However, this negates a key feature of machine learning--the ability to learn from a growing dataset and improve over time. This paper frames the design of an approval policy, which we refer to as an automatic algorithmic change protocol (aACP), as an online hypothesis testing problem. As this process has obvious analogy with noninferiority testing of new drugs, we investigate how repeated testing and adoption of modifications might lead to gradual deterioration in prediction accuracy, also known as ``biocreep'' in the drug development literature. We consider simple policies that one might consider but do not necessarily offer any error-rate guarantees, as well as policies that do provide error-rate control. For the latter, we define two online error-rates appropriate for this context: Bad Approval Count (BAC) and Bad Approval and Benchmark Ratios (BABR). We control these rates in the simple setting of a constant population and data source using policies aACP-BAC and aACP-BABR, which combine alpha-investing, group-sequential, and gate-keeping methods. In simulation studies, bio-creep regularly occurred when using policies with no error-rate guarantees, whereas aACP-BAC and -BABR controlled the rate of bio-creep without substantially impacting our ability to approve beneficial modifications.
Selective prediction-set models with coverage guarantees
Jun 13, 2019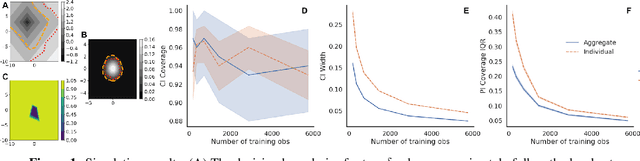
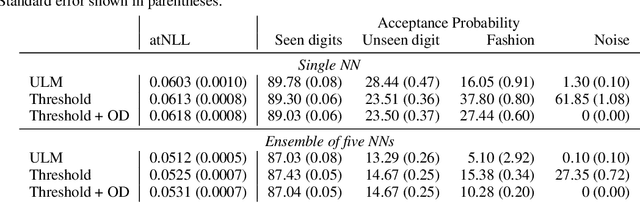
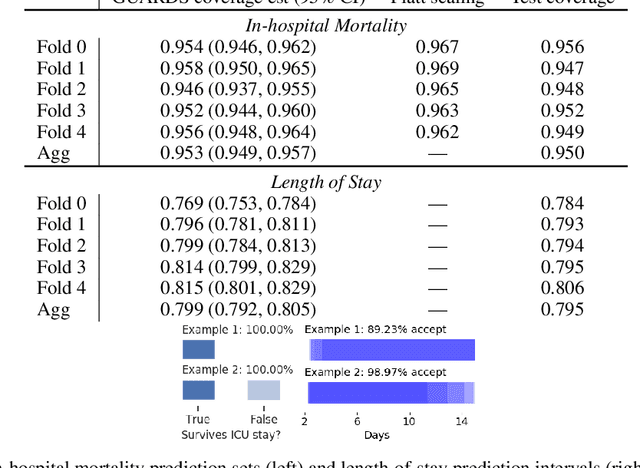

Though black-box predictors are state-of-the-art for many complex tasks, they often fail to properly quantify predictive uncertainty and may provide inappropriate predictions for unfamiliar data. Instead, we can learn more reliable models by letting them either output a prediction set or abstain when the uncertainty is high. We propose training these selective prediction-set models using an uncertainty-aware loss minimization framework, which unifies ideas from decision theory and robust maximum likelihood. Moreover, since black-box methods are not guaranteed to output well-calibrated prediction sets, we show how to calculate point estimates and confidence intervals for the true coverage of any selective prediction-set model, as well as a uniform mixture of K set models obtained from K-fold sample-splitting. When applied to predicting in-hospital mortality and length-of-stay for ICU patients, our model outperforms existing approaches on both in-sample and out-of-sample age groups, and our recalibration method provides accurate inference for prediction set coverage.
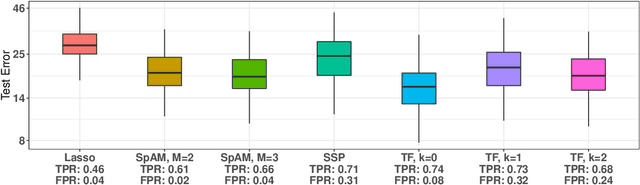
An analysis of the cost of hyper-parameter selection via split-sample validation, with applications to penalized regression
Mar 28, 2019
In the regression setting, given a set of hyper-parameters, a model-estimation procedure constructs a model from training data. The optimal hyper-parameters that minimize generalization error of the model are usually unknown. In practice they are often estimated using split-sample validation. Up to now, there is an open question regarding how the generalization error of the selected model grows with the number of hyper-parameters to be estimated. To answer this question, we establish finite-sample oracle inequalities for selection based on a single training/test split and based on cross-validation. We show that if the model-estimation procedures are smoothly parameterized by the hyper-parameters, the error incurred from tuning hyper-parameters shrinks at nearly a parametric rate. Hence for semi- and non-parametric model-estimation procedures with a fixed number of hyper-parameters, this additional error is negligible. For parametric model-estimation procedures, adding a hyper-parameter is roughly equivalent to adding a parameter to the model itself. In addition, we specialize these ideas for penalized regression problems with multiple penalty parameters. We establish that the fitted models are Lipschitz in the penalty parameters and thus our oracle inequalities apply. This result encourages development of regularization methods with many penalty parameters.
Generalized Sparse Additive Models
Mar 11, 2019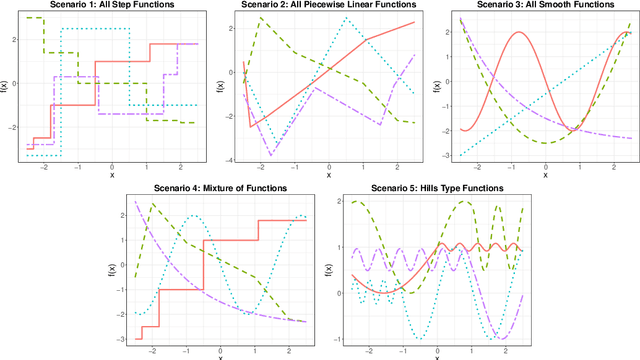
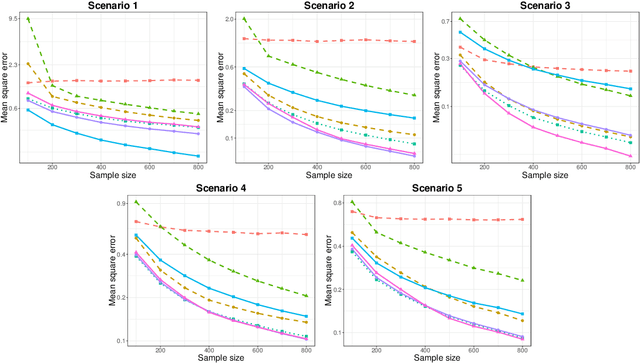
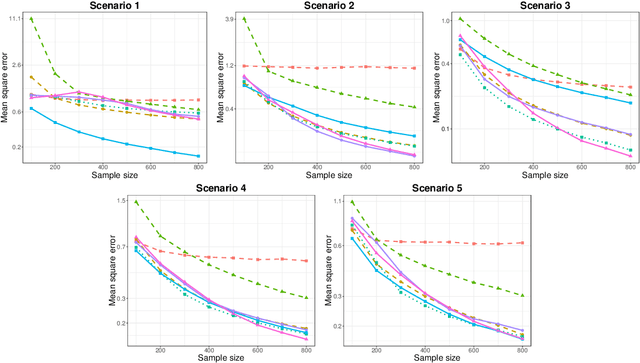
We present a unified framework for estimation and analysis of generalized additive models in high dimensions. The framework defines a large class of penalized regression estimators, encompassing many existing methods. An efficient computational algorithm for this class is presented that easily scales to thousands of observations and features. We prove minimax optimal convergence bounds for this class under a weak compatibility condition. In addition, we characterize the rate of convergence when this compatibility condition is not met. Finally, we also show that the optimal penalty parameters for structure and sparsity penalties in our framework are linked, allowing cross-validation to be conducted over only a single tuning parameter. We complement our theoretical results with empirical studies comparing some existing methods within this framework.
Wavelet regression and additive models for irregularly spaced data
Mar 11, 2019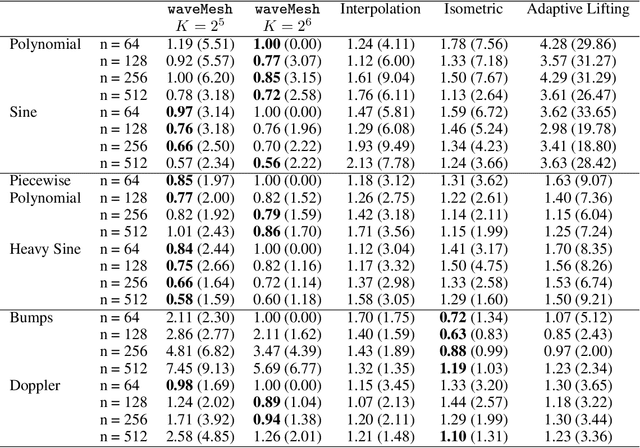


We present a novel approach for nonparametric regression using wavelet basis functions. Our proposal, $\texttt{waveMesh}$, can be applied to non-equispaced data with sample size not necessarily a power of 2. We develop an efficient proximal gradient descent algorithm for computing the estimator and establish adaptive minimax convergence rates. The main appeal of our approach is that it naturally extends to additive and sparse additive models for a potentially large number of covariates. We prove minimax optimal convergence rates under a weak compatibility condition for sparse additive models. The compatibility condition holds when we have a small number of covariates. Additionally, we establish convergence rates for when the condition is not met. We complement our theoretical results with empirical studies comparing $\texttt{waveMesh}$ to existing methods.
Sparse-Input Neural Networks for High-dimensional Nonparametric Regression and Classification
Nov 21, 2017



Neural networks are usually not the tool of choice for nonparametric high-dimensional problems where the number of input features is much larger than the number of observations. Though neural networks can approximate complex multivariate functions, they generally require a large number of training observations to obtain reasonable fits, unless one can learn the appropriate network structure. In this manuscript, we show that neural networks can be applied successfully to high-dimensional settings if the true function falls in a low dimensional subspace, and proper regularization is used. We propose fitting a neural network with a sparse group lasso penalty on the first-layer input weights, which results in a neural net that only uses a small subset of the original features. In addition, we characterize the statistical convergence of the penalized empirical risk minimizer to the optimal neural network: we show that the excess risk of this penalized estimator only grows with the logarithm of the number of input features; and we show that the weights of irrelevant features converge to zero. Via simulation studies and data analyses, we show that these sparse-input neural networks outperform existing nonparametric high-dimensional estimation methods when the data has complex higher-order interactions.