 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrchestrating Specialized Agents for Trustworthy Enterprise RAG
Jan 26, 2026Retrieval-Augmented Generation (RAG) shows promise for enterprise knowledge work, yet it often underperforms in high-stakes decision settings that require deep synthesis, strict traceability, and recovery from underspecified prompts. One-pass retrieval-and-write pipelines frequently yield shallow summaries, inconsistent grounding, and weak mechanisms for completeness verification. We introduce ADORE (Adaptive Deep Orchestration for Research in Enterprise), an agentic framework that replaces linear retrieval with iterative, user-steered investigation coordinated by a central orchestrator and a set of specialized agents. ADORE's key insight is that a structured Memory Bank (a curated evidence store with explicit claim-evidence linkage and section-level admissible evidence) enables traceable report generation and systematic checks for evidence completeness. Our contributions are threefold: (1) Memory-locked synthesis - report generation is constrained to a structured Memory Bank (Claim-Evidence Graph) with section-level admissible evidence, enabling traceable claims and grounded citations; (2) Evidence-coverage-guided execution - a retrieval-reflection loop audits section-level evidence coverage to trigger targeted follow-up retrieval and terminates via an evidence-driven stopping criterion; (3) Section-packed long-context grounding - section-level packing, pruning, and citation-preserving compression make long-form synthesis feasible under context limits. Across our evaluation suite, ADORE ranks first on DeepResearch Bench (52.65) and achieves the highest head-to-head preference win rate on DeepConsult (77.2%) against commercial systems.
Diversify, Don't Fine-Tune: Scaling Up Visual Recognition Training with Synthetic Images
Dec 04, 2023

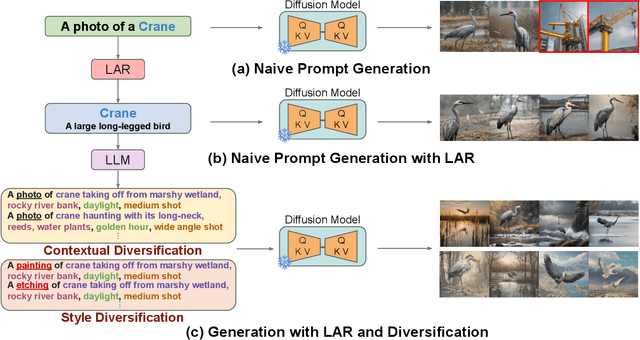

Recent advances in generative deep learning have enabled the creation of high-quality synthetic images in text-to-image generation. Prior work shows that fine-tuning a pretrained diffusion model on ImageNet and generating synthetic training images from the finetuned model can enhance an ImageNet classifier's performance. However, performance degrades as synthetic images outnumber real ones. In this paper, we explore whether generative fine-tuning is essential for this improvement and whether it is possible to further scale up training using more synthetic data. We present a new framework leveraging off-the-shelf generative models to generate synthetic training images, addressing multiple challenges: class name ambiguity, lack of diversity in naive prompts, and domain shifts. Specifically, we leverage large language models (LLMs) and CLIP to resolve class name ambiguity. To diversify images, we propose contextualized diversification (CD) and stylized diversification (SD) methods, also prompted by LLMs. Finally, to mitigate domain shifts, we leverage domain adaptation techniques with auxiliary batch normalization for synthetic images. Our framework consistently enhances recognition model performance with more synthetic data, up to 6x of original ImageNet size showcasing the potential of synthetic data for improved recognition models and strong out-of-domain generalization.
Similarity Search for Efficient Active Learning and Search of Rare Concepts
Jun 30, 2020
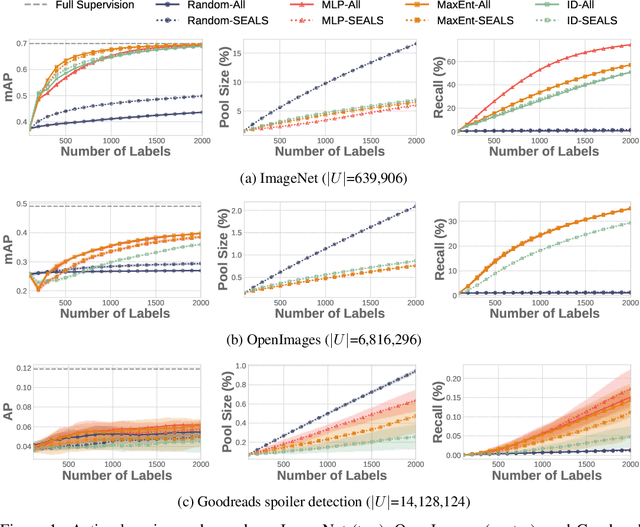

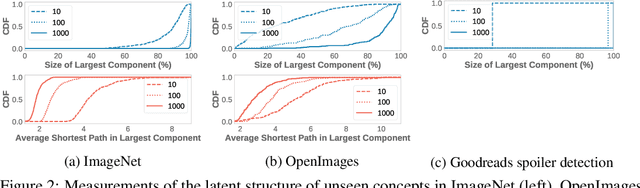
Many active learning and search approaches are intractable for industrial settings with billions of unlabeled examples. Existing approaches, such as uncertainty sampling or information density, search globally for the optimal examples to label, scaling linearly or even quadratically with the unlabeled data. However, in practice, data is often heavily skewed; only a small fraction of collected data will be relevant for a given learning task. For example, when identifying rare classes, detecting malicious content, or debugging model performance, the ratio of positive to negative examples can be 1 to 1,000 or more. In this work, we exploit this skew in large training datasets to reduce the number of unlabeled examples considered in each selection round by only looking at the nearest neighbors to the labeled examples. Empirically, we observe that learned representations effectively cluster unseen concepts, making active learning very effective and substantially reducing the number of viable unlabeled examples. We evaluate several active learning and search techniques in this setting on three large-scale datasets: ImageNet, Goodreads spoiler detection, and OpenImages. For rare classes, active learning methods need as little as 0.31% of the labeled data to match the average precision of full supervision. By limiting active learning methods to only consider the immediate neighbors of the labeled data as candidates for labeling, we need only process as little as 1% of the unlabeled data while achieving similar reductions in labeling costs as the traditional global approach. This process of expanding the candidate pool with the nearest neighbors of the labeled set can be done efficiently and reduces the computational complexity of selection by orders of magnitude.