 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Evaluation of Large Vision-Language Models for Surgical Artificial Intelligence
Apr 03, 2025Large Vision-Language Models offer a new paradigm for AI-driven image understanding, enabling models to perform tasks without task-specific training. This flexibility holds particular promise across medicine, where expert-annotated data is scarce. Yet, VLMs' practical utility in intervention-focused domains--especially surgery, where decision-making is subjective and clinical scenarios are variable--remains uncertain. Here, we present a comprehensive analysis of 11 state-of-the-art VLMs across 17 key visual understanding tasks in surgical AI--from anatomy recognition to skill assessment--using 13 datasets spanning laparoscopic, robotic, and open procedures. In our experiments, VLMs demonstrate promising generalizability, at times outperforming supervised models when deployed outside their training setting. In-context learning, incorporating examples during testing, boosted performance up to three-fold, suggesting adaptability as a key strength. Still, tasks requiring spatial or temporal reasoning remained difficult. Beyond surgery, our findings offer insights into VLMs' potential for tackling complex and dynamic scenarios in clinical and broader real-world applications.
DeforHMR: Vision Transformer with Deformable Cross-Attention for 3D Human Mesh Recovery
Nov 18, 2024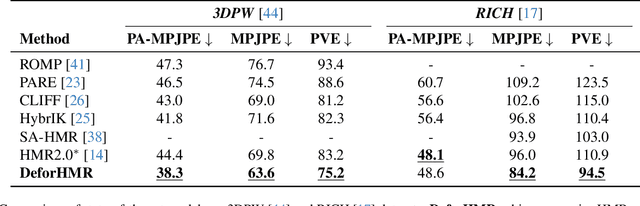
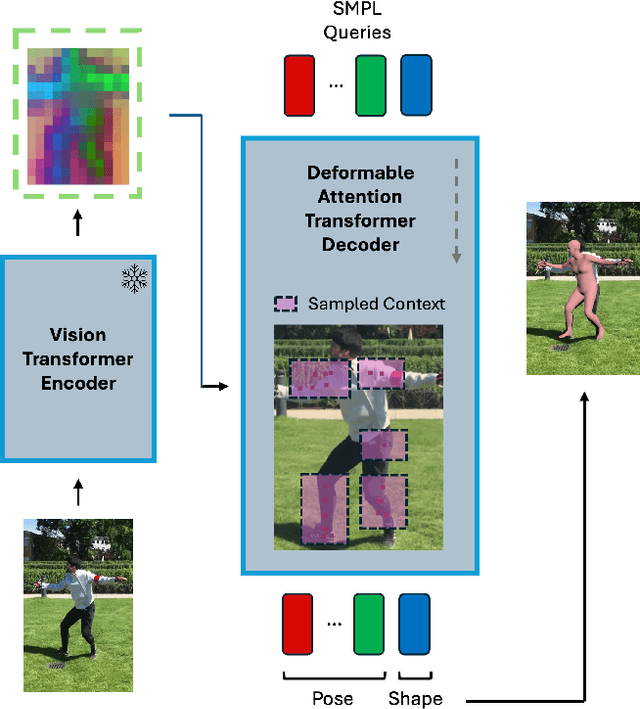

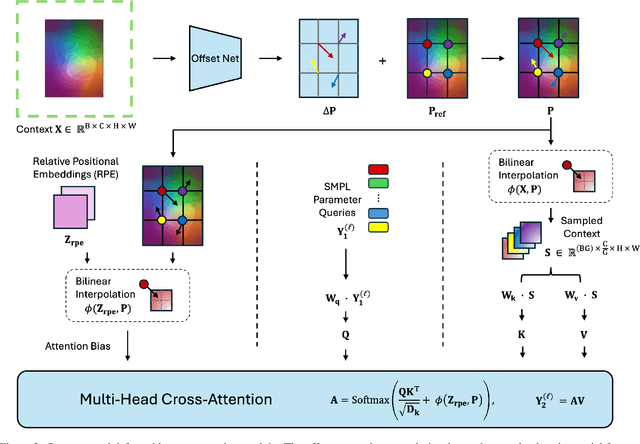
Human Mesh Recovery (HMR) is an important yet challenging problem with applications across various domains including motion capture, augmented reality, and biomechanics. Accurately predicting human pose parameters from a single image remains a challenging 3D computer vision task. In this work, we introduce DeforHMR, a novel regression-based monocular HMR framework designed to enhance the prediction of human pose parameters using deformable attention transformers. DeforHMR leverages a novel query-agnostic deformable cross-attention mechanism within the transformer decoder to effectively regress the visual features extracted from a frozen pretrained vision transformer (ViT) encoder. The proposed deformable cross-attention mechanism allows the model to attend to relevant spatial features more flexibly and in a data-dependent manner. Equipped with a transformer decoder capable of spatially-nuanced attention, DeforHMR achieves state-of-the-art performance for single-frame regression-based methods on the widely used 3D HMR benchmarks 3DPW and RICH. By pushing the boundary on the field of 3D human mesh recovery through deformable attention, we introduce an new, effective paradigm for decoding local spatial information from large pretrained vision encoders in computer vision.
Motion Diffusion-Guided 3D Global HMR from a Dynamic Camera
Nov 15, 2024



Motion capture technologies have transformed numerous fields, from the film and gaming industries to sports science and healthcare, by providing a tool to capture and analyze human movement in great detail. The holy grail in the topic of monocular global human mesh and motion reconstruction (GHMR) is to achieve accuracy on par with traditional multi-view capture on any monocular videos captured with a dynamic camera, in-the-wild. This is a challenging task as the monocular input has inherent depth ambiguity, and the moving camera adds additional complexity as the rendered human motion is now a product of both human and camera movement. Not accounting for this confusion, existing GHMR methods often output motions that are unrealistic, e.g. unaccounted root translation of the human causes foot sliding. We present DiffOpt, a novel 3D global HMR method using Diffusion Optimization. Our key insight is that recent advances in human motion generation, such as the motion diffusion model (MDM), contain a strong prior of coherent human motion. The core of our method is to optimize the initial motion reconstruction using the MDM prior. This step can lead to more globally coherent human motion. Our optimization jointly optimizes the motion prior loss and reprojection loss to correctly disentangle the human and camera motions. We validate DiffOpt with video sequences from the Electromagnetic Database of Global 3D Human Pose and Shape in the Wild (EMDB) and Egobody, and demonstrate superior global human motion recovery capability over other state-of-the-art global HMR methods most prominently in long video settings.