 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoMo: A Large-Scale, Richly Organized Dataset and Semantic Taxonomy for Human Motion Generation
May 25, 2026Success in generative modeling across language, image, and video demonstrates that large, well-curated datasets are the key driver for building capable models. 3D Human motion, however, has lagged behind, constrained by an unsatisfying choice between small, high-fidelity motion capture datasets and large-scale in-the-wild collections dominated by static or low-quality sequences. We introduce RoMo, a rich, large-scale, carefully curated dataset of in-the-wild human motions that resolves these tradeoffs. To ensure quality, we introduce a taxonomy-aware filtering pipeline that aggressively removes static and artifact-prone sequences. Every sequence is annotated with detailed captions and organized by a novel three-level semantic taxonomy. This hierarchical structure enables fine-grained, per-category evaluation, that reveals model strengths and weaknesses obscured by global metrics. We demonstrate that models trained on RoMo achieve state-of-the-art fidelity and diversity while gaining a superior understanding of complex, subtle text prompts. Finally, we release the Motion Toolbox to standardize metrics, data conversion, and visualization, establishing a foundation for reproducible and interpretable motion generation research.
Minimalist Compliance Control
Mar 01, 2026Compliance control is essential for safe physical interaction, yet its adoption is limited by hardware requirements such as force torque sensors. While recent reinforcement learning approaches aim to bypass these constraints, they often suffer from sim-to-real gaps, lack safety guarantees, and add system complexity. We propose Minimalist Compliance Control, which enables compliant behavior using only motor current or voltage signals readily available in modern servos and quasi-direct-drive motors, without force sensors, current control, or learning. External wrenches are estimated from actuator signals and Jacobians and incorporated into a task-space admittance controller, preserving sufficient force measurement accuracy for stable and responsive compliance control. Our method is embodiment-agnostic and plug-and-play with diverse high-level planners. We validate our approach on a robot arm, a dexterous hand, and two humanoid robots across multiple contact-rich tasks, using vision-language models, imitation learning, and model-based planning. The results demonstrate robust, safe, and compliant interaction across embodiments and planning paradigms.
RPL: Learning Robust Humanoid Perceptive Locomotion on Challenging Terrains
Feb 03, 2026Humanoid perceptive locomotion has made significant progress and shows great promise, yet achieving robust multi-directional locomotion on complex terrains remains underexplored. To tackle this challenge, we propose RPL, a two-stage training framework that enables multi-directional locomotion on challenging terrains, and remains robust with payloads. RPL first trains terrain-specific expert policies with privileged height map observations to master decoupled locomotion and manipulation skills across different terrains, and then distills them into a transformer policy that leverages multiple depth cameras to cover a wide range of views. During distillation, we introduce two techniques to robustify multi-directional locomotion, depth feature scaling based on velocity commands and random side masking, which are critical for asymmetric depth observations and unseen widths of terrains. For scalable depth distillation, we develop an efficient multi-depth system that ray-casts against both dynamic robot meshes and static terrain meshes in massively parallel environments, achieving a 5-times speedup over the depth rendering pipelines in existing simulators while modeling realistic sensor latency, noise, and dropout. Extensive real-world experiments demonstrate robust multi-directional locomotion with payloads (2kg) across challenging terrains, including 20° slopes, staircases with different step lengths (22 cm, 25 cm, 30 cm), and 25 cm by 25 cm stepping stones separated by 60 cm gaps.
Flow Policy Gradients for Robot Control
Feb 02, 2026Likelihood-based policy gradient methods are the dominant approach for training robot control policies from rewards. These methods rely on differentiable action likelihoods, which constrain policy outputs to simple distributions like Gaussians. In this work, we show how flow matching policy gradients -- a recent framework that bypasses likelihood computation -- can be made effective for training and fine-tuning more expressive policies in challenging robot control settings. We introduce an improved objective that enables success in legged locomotion, humanoid motion tracking, and manipulation tasks, as well as robust sim-to-real transfer on two humanoid robots. We then present ablations and analysis on training dynamics. Results show how policies can exploit the flow representation for exploration when training from scratch, as well as improved fine-tuning robustness over baselines.
Motion Diffusion-Guided 3D Global HMR from a Dynamic Camera
Nov 15, 2024



Motion capture technologies have transformed numerous fields, from the film and gaming industries to sports science and healthcare, by providing a tool to capture and analyze human movement in great detail. The holy grail in the topic of monocular global human mesh and motion reconstruction (GHMR) is to achieve accuracy on par with traditional multi-view capture on any monocular videos captured with a dynamic camera, in-the-wild. This is a challenging task as the monocular input has inherent depth ambiguity, and the moving camera adds additional complexity as the rendered human motion is now a product of both human and camera movement. Not accounting for this confusion, existing GHMR methods often output motions that are unrealistic, e.g. unaccounted root translation of the human causes foot sliding. We present DiffOpt, a novel 3D global HMR method using Diffusion Optimization. Our key insight is that recent advances in human motion generation, such as the motion diffusion model (MDM), contain a strong prior of coherent human motion. The core of our method is to optimize the initial motion reconstruction using the MDM prior. This step can lead to more globally coherent human motion. Our optimization jointly optimizes the motion prior loss and reprojection loss to correctly disentangle the human and camera motions. We validate DiffOpt with video sequences from the Electromagnetic Database of Global 3D Human Pose and Shape in the Wild (EMDB) and Egobody, and demonstrate superior global human motion recovery capability over other state-of-the-art global HMR methods most prominently in long video settings.
GIMO: Gaze-Informed Human Motion Prediction in Context
Apr 20, 2022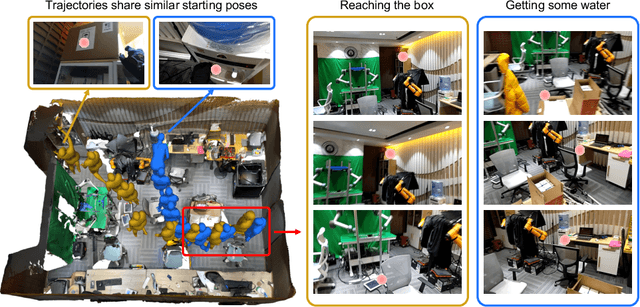
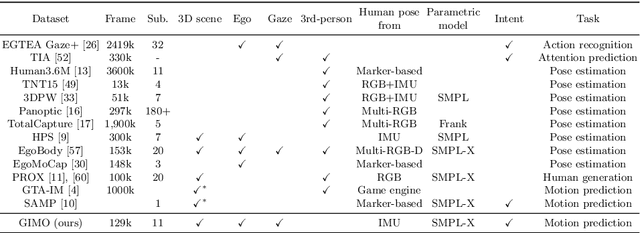
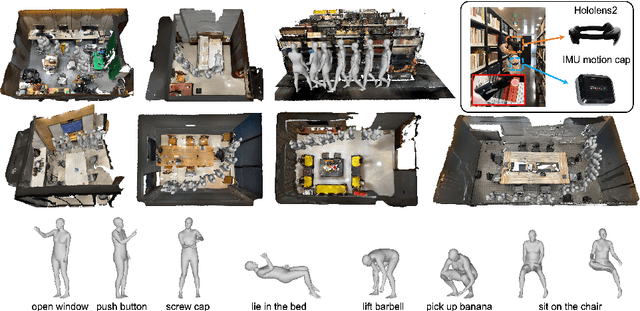
Predicting human motion is critical for assistive robots and AR/VR applications, where the interaction with humans needs to be safe and comfortable. Meanwhile, an accurate prediction depends on understanding both the scene context and human intentions. Even though many works study scene-aware human motion prediction, the latter is largely underexplored due to the lack of ego-centric views that disclose human intent and the limited diversity in motion and scenes. To reduce the gap, we propose a large-scale human motion dataset that delivers high-quality body pose sequences, scene scans, as well as ego-centric views with eye gaze that serves as a surrogate for inferring human intent. By employing inertial sensors for motion capture, our data collection is not tied to specific scenes, which further boosts the motion dynamics observed from our subjects. We perform an extensive study of the benefits of leveraging eye gaze for ego-centric human motion prediction with various state-of-the-art architectures. Moreover, to realize the full potential of gaze, we propose a novel network architecture that enables bidirectional communication between the gaze and motion branches. Our network achieves the top performance in human motion prediction on the proposed dataset, thanks to the intent information from the gaze and the denoised gaze feature modulated by the motion. The proposed dataset and our network implementation will be publicly available.