 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Evaluation of Large Vision-Language Models for Surgical Artificial Intelligence
Apr 03, 2025Large Vision-Language Models offer a new paradigm for AI-driven image understanding, enabling models to perform tasks without task-specific training. This flexibility holds particular promise across medicine, where expert-annotated data is scarce. Yet, VLMs' practical utility in intervention-focused domains--especially surgery, where decision-making is subjective and clinical scenarios are variable--remains uncertain. Here, we present a comprehensive analysis of 11 state-of-the-art VLMs across 17 key visual understanding tasks in surgical AI--from anatomy recognition to skill assessment--using 13 datasets spanning laparoscopic, robotic, and open procedures. In our experiments, VLMs demonstrate promising generalizability, at times outperforming supervised models when deployed outside their training setting. In-context learning, incorporating examples during testing, boosted performance up to three-fold, suggesting adaptability as a key strength. Still, tasks requiring spatial or temporal reasoning remained difficult. Beyond surgery, our findings offer insights into VLMs' potential for tackling complex and dynamic scenarios in clinical and broader real-world applications.
Depth-guided NeRF Training via Earth Mover's Distance
Mar 19, 2024



Neural Radiance Fields (NeRFs) are trained to minimize the rendering loss of predicted viewpoints. However, the photometric loss often does not provide enough information to disambiguate between different possible geometries yielding the same image. Previous work has thus incorporated depth supervision during NeRF training, leveraging dense predictions from pre-trained depth networks as pseudo-ground truth. While these depth priors are assumed to be perfect once filtered for noise, in practice, their accuracy is more challenging to capture. This work proposes a novel approach to uncertainty in depth priors for NeRF supervision. Instead of using custom-trained depth or uncertainty priors, we use off-the-shelf pretrained diffusion models to predict depth and capture uncertainty during the denoising process. Because we know that depth priors are prone to errors, we propose to supervise the ray termination distance distribution with Earth Mover's Distance instead of enforcing the rendered depth to replicate the depth prior exactly through L2-loss. Our depth-guided NeRF outperforms all baselines on standard depth metrics by a large margin while maintaining performance on photometric measures.
FlowVOS: Weakly-Supervised Visual Warping for Detail-Preserving and Temporally Consistent Single-Shot Video Object Segmentation
Nov 20, 2021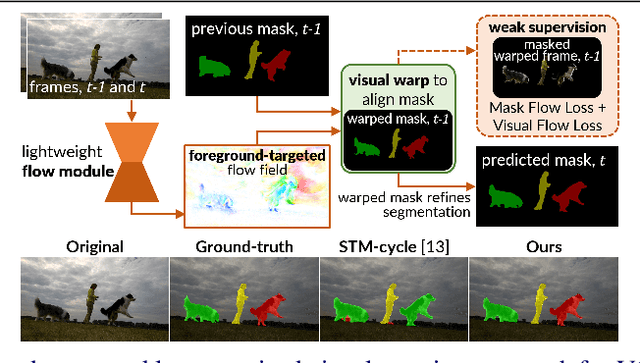
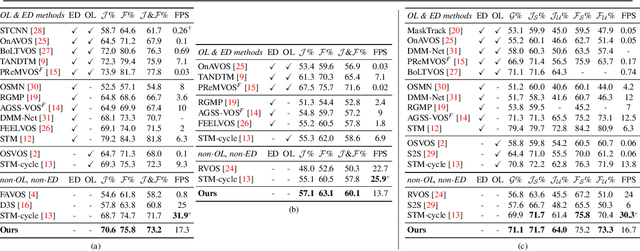
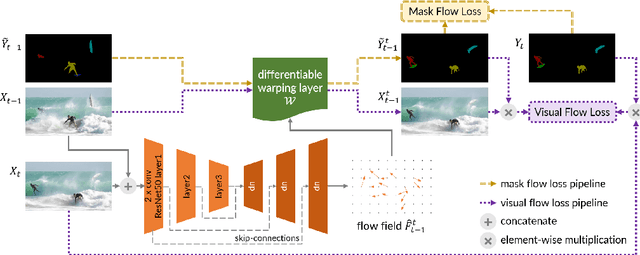
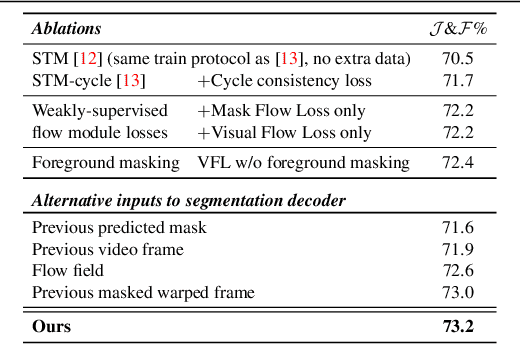
We consider the task of semi-supervised video object segmentation (VOS). Our approach mitigates shortcomings in previous VOS work by addressing detail preservation and temporal consistency using visual warping. In contrast to prior work that uses full optical flow, we introduce a new foreground-targeted visual warping approach that learns flow fields from VOS data. We train a flow module to capture detailed motion between frames using two weakly-supervised losses. Our object-focused approach of warping previous foreground object masks to their positions in the target frame enables detailed mask refinement with fast runtimes without using extra flow supervision. It can also be integrated directly into state-of-the-art segmentation networks. On the DAVIS17 and YouTubeVOS benchmarks, we outperform state-of-the-art offline methods that do not use extra data, as well as many online methods that use extra data. Qualitatively, we also show our approach produces segmentations with high detail and temporal consistency.