 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAIRA-2: Grounded Radiology Report Generation
Jun 06, 2024



Radiology reporting is a complex task that requires detailed image understanding, integration of multiple inputs, including comparison with prior imaging, and precise language generation. This makes it ideal for the development and use of generative multimodal models. Here, we extend report generation to include the localisation of individual findings on the image - a task we call grounded report generation. Prior work indicates that grounding is important for clarifying image understanding and interpreting AI-generated text. Therefore, grounded reporting stands to improve the utility and transparency of automated report drafting. To enable evaluation of grounded reporting, we propose a novel evaluation framework - RadFact - leveraging the reasoning capabilities of large language models (LLMs). RadFact assesses the factuality of individual generated sentences, as well as correctness of generated spatial localisations when present. We introduce MAIRA-2, a large multimodal model combining a radiology-specific image encoder with a LLM, and trained for the new task of grounded report generation on chest X-rays. MAIRA-2 uses more comprehensive inputs than explored previously: the current frontal image, the current lateral image, the prior frontal image and prior report, as well as the Indication, Technique and Comparison sections of the current report. We demonstrate that these additions significantly improve report quality and reduce hallucinations, establishing a new state of the art on findings generation (without grounding) on MIMIC-CXR while demonstrating the feasibility of grounded reporting as a novel and richer task.
Training Small Multimodal Models to Bridge Biomedical Competency Gap: A Case Study in Radiology Imaging
Mar 20, 2024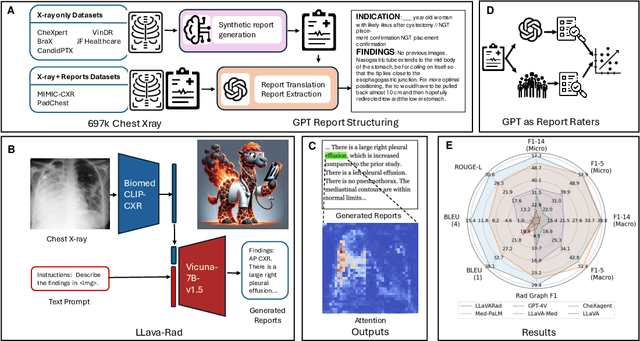
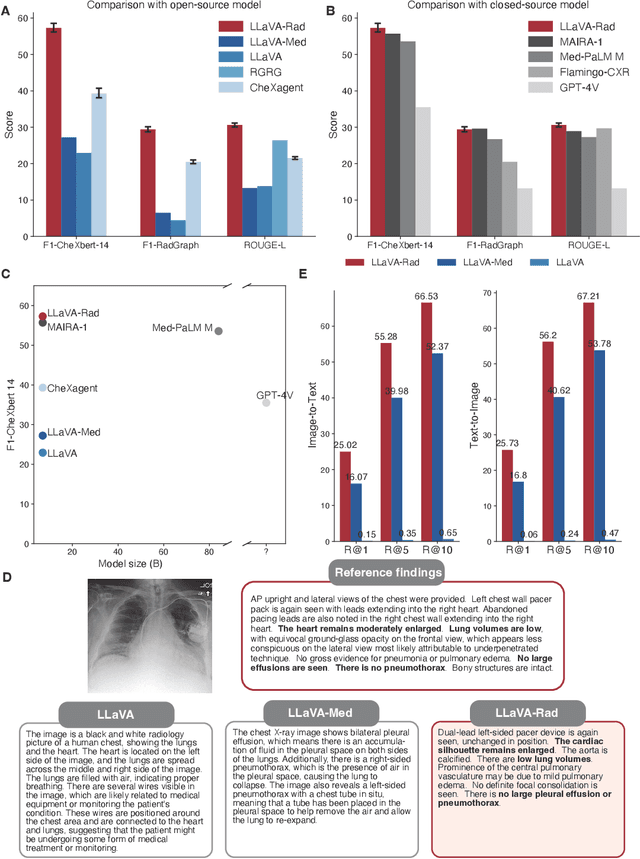
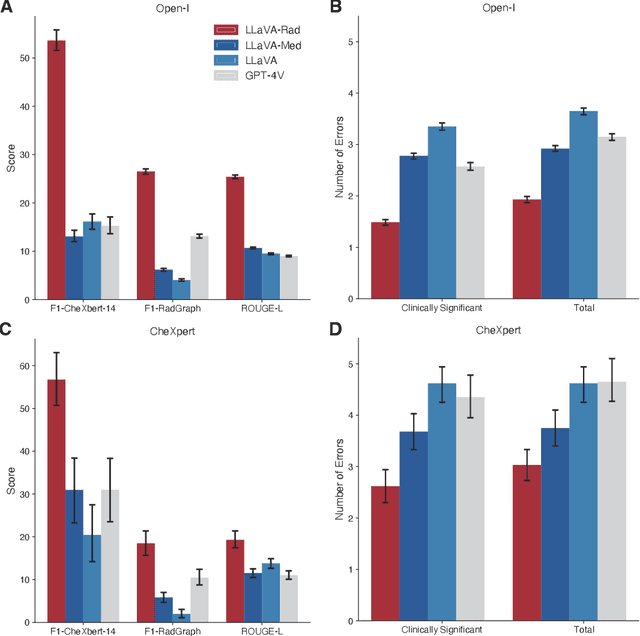
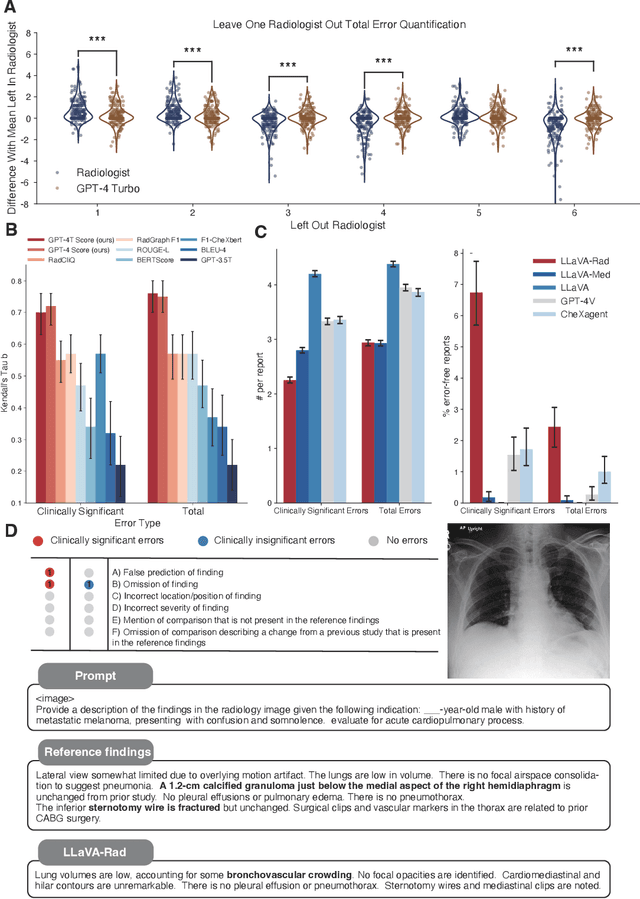
The scaling laws and extraordinary performance of large foundation models motivate the development and utilization of such large models in biomedicine. However, despite early promising results on some biomedical benchmarks, there are still major challenges that need to be addressed before these models can be used in real-world applications. Frontier models such as GPT-4V still have major competency gaps in multimodal capabilities for biomedical applications. Moreover, pragmatic issues such as access, cost, latency, and compliance make it hard for clinicians to use privately-hosted state-of-the-art large models directly on private patient data. In this paper, we explore training open-source small multimodal models (SMMs) to bridge biomedical competency gaps for unmet clinical needs. To maximize data efficiency, we adopt a modular approach by incorporating state-of-the-art pre-trained models for image and text modalities, and focusing on training a lightweight adapter to ground each modality to the text embedding space. We conduct a comprehensive study of this approach on radiology imaging. For training, we assemble a large dataset with over 1 million image-text pairs. For evaluation, we propose a clinically driven novel approach using GPT-4 and demonstrate its parity with expert evaluation. We also study grounding qualitatively using attention. For best practice, we conduct a systematic ablation study on various choices in data engineering and multimodal training. The resulting LLaVA-Rad (7B) model attains state-of-the-art results on radiology tasks such as report generation and cross-modal retrieval, even outperforming much larger models such as GPT-4V and Med-PaLM M (84B). LLaVA-Rad is fast and can be run on a single V100 GPU in private settings, offering a promising state-of-the-art tool for real-world clinical applications.
3D-MIR: A Benchmark and Empirical Study on 3D Medical Image Retrieval in Radiology
Nov 23, 2023



The increasing use of medical imaging in healthcare settings presents a significant challenge due to the increasing workload for radiologists, yet it also offers opportunity for enhancing healthcare outcomes if effectively leveraged. 3D image retrieval holds potential to reduce radiologist workloads by enabling clinicians to efficiently search through diagnostically similar or otherwise relevant cases, resulting in faster and more precise diagnoses. However, the field of 3D medical image retrieval is still emerging, lacking established evaluation benchmarks, comprehensive datasets, and thorough studies. This paper attempts to bridge this gap by introducing a novel benchmark for 3D Medical Image Retrieval (3D-MIR) that encompasses four different anatomies imaged with computed tomography. Using this benchmark, we explore a diverse set of search strategies that use aggregated 2D slices, 3D volumes, and multi-modal embeddings from popular multi-modal foundation models as queries. Quantitative and qualitative assessments of each approach are provided alongside an in-depth discussion that offers insight for future research. To promote the advancement of this field, our benchmark, dataset, and code are made publicly available.
FlowVOS: Weakly-Supervised Visual Warping for Detail-Preserving and Temporally Consistent Single-Shot Video Object Segmentation
Nov 20, 2021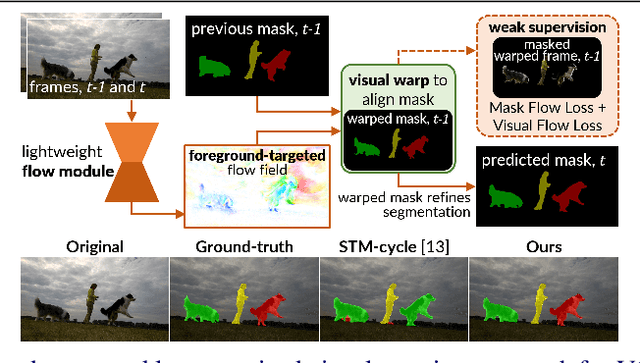
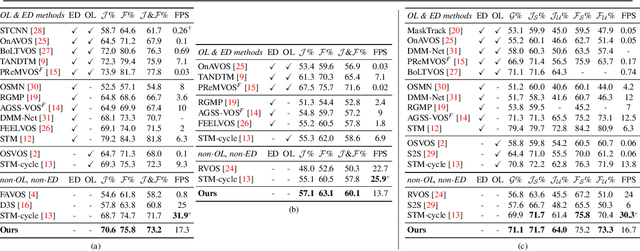
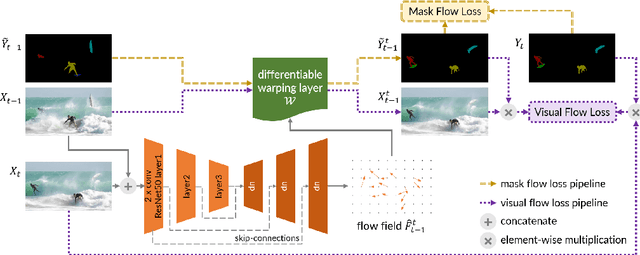
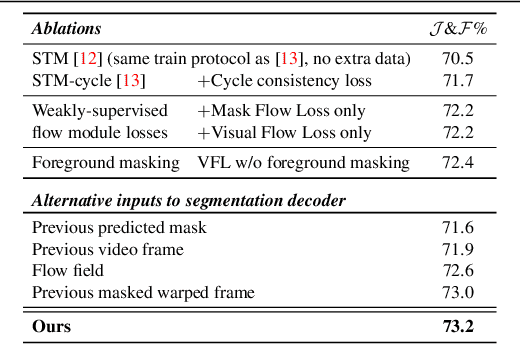
We consider the task of semi-supervised video object segmentation (VOS). Our approach mitigates shortcomings in previous VOS work by addressing detail preservation and temporal consistency using visual warping. In contrast to prior work that uses full optical flow, we introduce a new foreground-targeted visual warping approach that learns flow fields from VOS data. We train a flow module to capture detailed motion between frames using two weakly-supervised losses. Our object-focused approach of warping previous foreground object masks to their positions in the target frame enables detailed mask refinement with fast runtimes without using extra flow supervision. It can also be integrated directly into state-of-the-art segmentation networks. On the DAVIS17 and YouTubeVOS benchmarks, we outperform state-of-the-art offline methods that do not use extra data, as well as many online methods that use extra data. Qualitatively, we also show our approach produces segmentations with high detail and temporal consistency.
Refining Targeted Syntactic Evaluation of Language Models
Apr 19, 2021
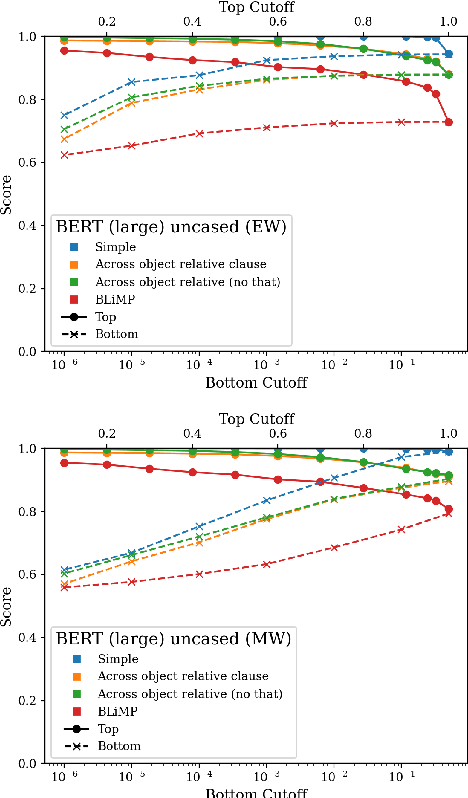
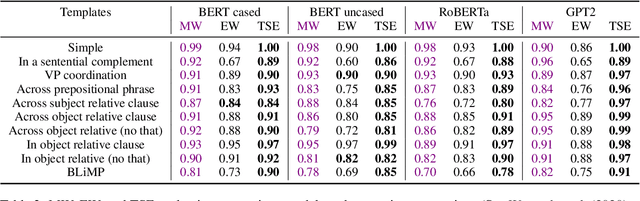
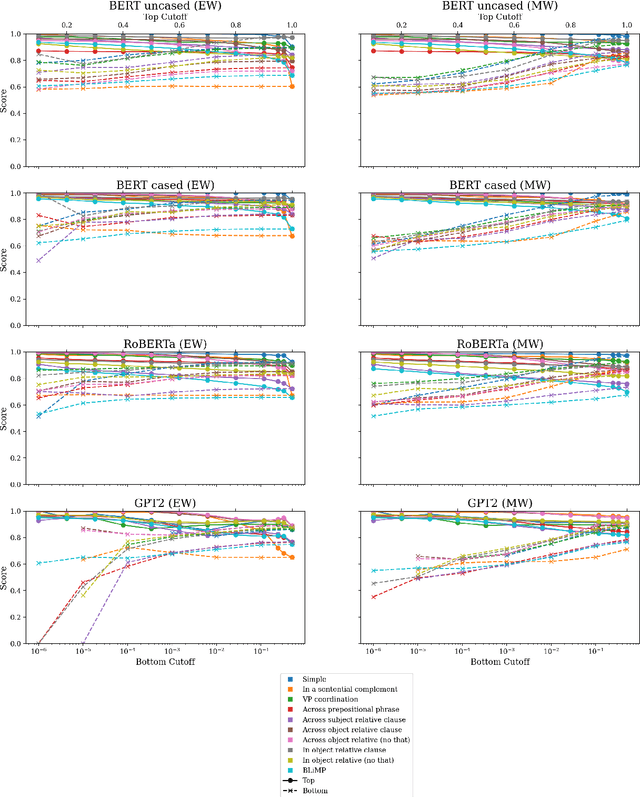
Targeted syntactic evaluation of subject-verb number agreement in English (TSE) evaluates language models' syntactic knowledge using hand-crafted minimal pairs of sentences that differ only in the main verb's conjugation. The method evaluates whether language models rate each grammatical sentence as more likely than its ungrammatical counterpart. We identify two distinct goals for TSE. First, evaluating the systematicity of a language model's syntactic knowledge: given a sentence, can it conjugate arbitrary verbs correctly? Second, evaluating a model's likely behavior: given a sentence, does the model concentrate its probability mass on correctly conjugated verbs, even if only on a subset of the possible verbs? We argue that current implementations of TSE do not directly capture either of these goals, and propose new metrics to capture each goal separately. Under our metrics, we find that TSE overestimates systematicity of language models, but that models score up to 40% better on verbs that they predict are likely in context.
AutoToon: Automatic Geometric Warping for Face Cartoon Generation
Apr 06, 2020
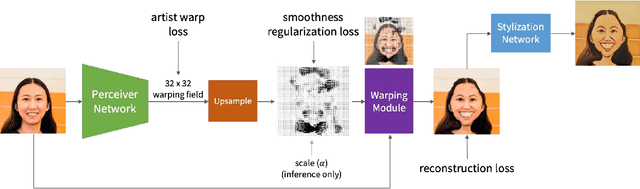


Caricature, a type of exaggerated artistic portrait, amplifies the distinctive, yet nuanced traits of human faces. This task is typically left to artists, as it has proven difficult to capture subjects' unique characteristics well using automated methods. Recent development of deep end-to-end methods has achieved promising results in capturing style and higher-level exaggerations. However, a key part of caricatures, face warping, has remained challenging for these systems. In this work, we propose AutoToon, the first supervised deep learning method that yields high-quality warps for the warping component of caricatures. Completely disentangled from style, it can be paired with any stylization method to create diverse caricatures. In contrast to prior art, we leverage an SENet and spatial transformer module and train directly on artist warping fields, applying losses both prior to and after warping. As shown by our user studies, we achieve appealing exaggerations that amplify distinguishing features of the face while preserving facial detail.