 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePETAR: Localized Findings Generation with Mask-Aware Vision-Language Modeling for PET Automated Reporting
Oct 31, 2025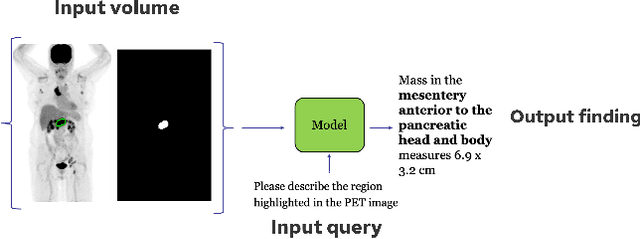


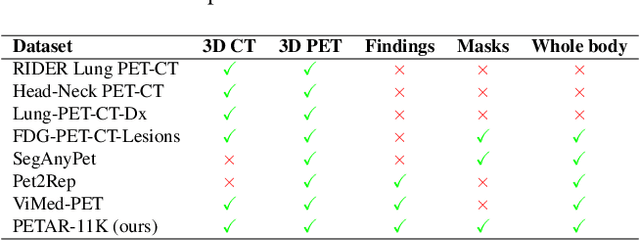
Recent advances in vision-language models (VLMs) have enabled impressive multimodal reasoning, yet most medical applications remain limited to 2D imaging. In this work, we extend VLMs to 3D positron emission tomography and computed tomography (PET/CT), a domain characterized by large volumetric data, small and dispersed lesions, and lengthy radiology reports. We introduce a large-scale dataset comprising over 11,000 lesion-level descriptions paired with 3D segmentations from more than 5,000 PET/CT exams, extracted via a hybrid rule-based and large language model (LLM) pipeline. Building upon this dataset, we propose PETAR-4B, a 3D mask-aware vision-language model that integrates PET, CT, and lesion contours for spatially grounded report generation. PETAR bridges global contextual reasoning with fine-grained lesion awareness, producing clinically coherent and localized findings. Comprehensive automated and human evaluations demonstrate that PETAR substantially improves PET/CT report generation quality, advancing 3D medical vision-language understanding.
From Embeddings to Accuracy: Comparing Foundation Models for Radiographic Classification
May 16, 2025Foundation models, pretrained on extensive datasets, have significantly advanced machine learning by providing robust and transferable embeddings applicable to various domains, including medical imaging diagnostics. This study evaluates the utility of embeddings derived from both general-purpose and medical domain-specific foundation models for training lightweight adapter models in multi-class radiography classification, focusing specifically on tube placement assessment. A dataset comprising 8842 radiographs classified into seven distinct categories was employed to extract embeddings using six foundation models: DenseNet121, BiomedCLIP, Med-Flamingo, MedImageInsight, Rad-DINO, and CXR-Foundation. Adapter models were subsequently trained using classical machine learning algorithms. Among these combinations, MedImageInsight embeddings paired with an support vector machine adapter yielded the highest mean area under the curve (mAUC) at 93.8%, followed closely by Rad-DINO (91.1%) and CXR-Foundation (89.0%). In comparison, BiomedCLIP and DenseNet121 exhibited moderate performance with mAUC scores of 83.0% and 81.8%, respectively, whereas Med-Flamingo delivered the lowest performance at 75.1%. Notably, most adapter models demonstrated computational efficiency, achieving training within one minute and inference within seconds on CPU, underscoring their practicality for clinical applications. Furthermore, fairness analyses on adapters trained on MedImageInsight-derived embeddings indicated minimal disparities, with gender differences in performance within 2% and standard deviations across age groups not exceeding 3%. These findings confirm that foundation model embeddings-especially those from MedImageInsight-facilitate accurate, computationally efficient, and equitable diagnostic classification using lightweight adapters for radiographic image analysis.
Scalable Drift Monitoring in Medical Imaging AI
Oct 17, 2024



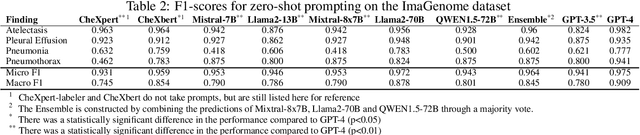
The integration of artificial intelligence (AI) into medical imaging has advanced clinical diagnostics but poses challenges in managing model drift and ensuring long-term reliability. To address these challenges, we develop MMC+, an enhanced framework for scalable drift monitoring, building upon the CheXstray framework that introduced real-time drift detection for medical imaging AI models using multi-modal data concordance. This work extends the original framework's methodologies, providing a more scalable and adaptable solution for real-world healthcare settings and offers a reliable and cost-effective alternative to continuous performance monitoring addressing limitations of both continuous and periodic monitoring methods. MMC+ introduces critical improvements to the original framework, including more robust handling of diverse data streams, improved scalability with the integration of foundation models like MedImageInsight for high-dimensional image embeddings without site-specific training, and the introduction of uncertainty bounds to better capture drift in dynamic clinical environments. Validated with real-world data from Massachusetts General Hospital during the COVID-19 pandemic, MMC+ effectively detects significant data shifts and correlates them with model performance changes. While not directly predicting performance degradation, MMC+ serves as an early warning system, indicating when AI systems may deviate from acceptable performance bounds and enabling timely interventions. By emphasizing the importance of monitoring diverse data streams and evaluating data shifts alongside model performance, this work contributes to the broader adoption and integration of AI solutions in clinical settings.
Is Open-Source There Yet? A Comparative Study on Commercial and Open-Source LLMs in Their Ability to Label Chest X-Ray Reports
Feb 19, 2024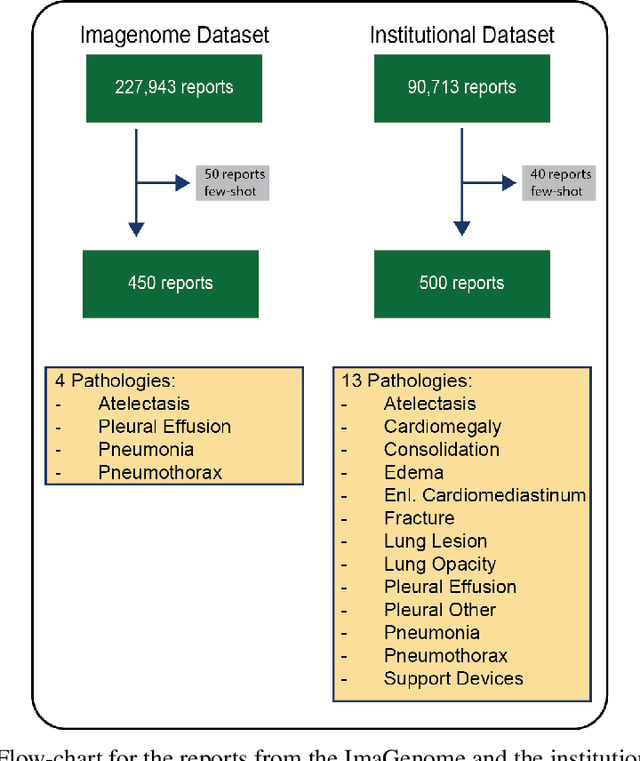
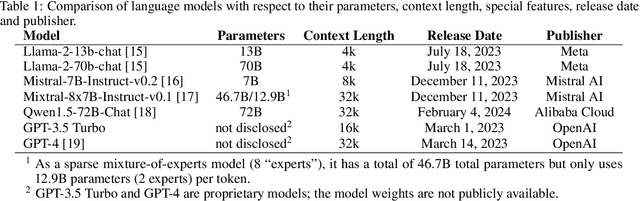
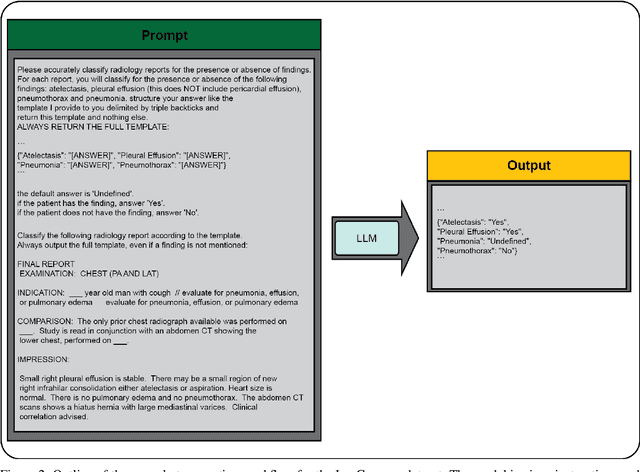
Introduction: With the rapid advances in large language models (LLMs), there have been numerous new open source as well as commercial models. While recent publications have explored GPT-4 in its application to extracting information of interest from radiology reports, there has not been a real-world comparison of GPT-4 to different leading open-source models. Materials and Methods: Two different and independent datasets were used. The first dataset consists of 540 chest x-ray reports that were created at the Massachusetts General Hospital between July 2019 and July 2021. The second dataset consists of 500 chest x-ray reports from the ImaGenome dataset. We then compared the commercial models GPT-3.5 Turbo and GPT-4 from OpenAI to the open-source models Mistral-7B, Mixtral-8x7B, Llama2-13B, Llama2-70B, QWEN1.5-72B and CheXbert and CheXpert-labeler in their ability to accurately label the presence of multiple findings in x-ray text reports using different prompting techniques. Results: On the ImaGenome dataset, the best performing open-source model was Llama2-70B with micro F1-scores of 0.972 and 0.970 for zero- and few-shot prompts, respectively. GPT-4 achieved micro F1-scores of 0.975 and 0.984, respectively. On the institutional dataset, the best performing open-source model was QWEN1.5-72B with micro F1-scores of 0.952 and 0.965 for zero- and few-shot prompting, respectively. GPT-4 achieved micro F1-scores of 0.975 and 0.973, respectively. Conclusion: In this paper, we show that while GPT-4 is superior to open-source models in zero-shot report labeling, the implementation of few-shot prompting can bring open-source models on par with GPT-4. This shows that open-source models could be a performant and privacy preserving alternative to GPT-4 for the task of radiology report classification.
3D-MIR: A Benchmark and Empirical Study on 3D Medical Image Retrieval in Radiology
Nov 23, 2023



The increasing use of medical imaging in healthcare settings presents a significant challenge due to the increasing workload for radiologists, yet it also offers opportunity for enhancing healthcare outcomes if effectively leveraged. 3D image retrieval holds potential to reduce radiologist workloads by enabling clinicians to efficiently search through diagnostically similar or otherwise relevant cases, resulting in faster and more precise diagnoses. However, the field of 3D medical image retrieval is still emerging, lacking established evaluation benchmarks, comprehensive datasets, and thorough studies. This paper attempts to bridge this gap by introducing a novel benchmark for 3D Medical Image Retrieval (3D-MIR) that encompasses four different anatomies imaged with computed tomography. Using this benchmark, we explore a diverse set of search strategies that use aggregated 2D slices, 3D volumes, and multi-modal embeddings from popular multi-modal foundation models as queries. Quantitative and qualitative assessments of each approach are provided alongside an in-depth discussion that offers insight for future research. To promote the advancement of this field, our benchmark, dataset, and code are made publicly available.
Region-based Contrastive Pretraining for Medical Image Retrieval with Anatomic Query
May 09, 2023



We introduce a novel Region-based contrastive pretraining for Medical Image Retrieval (RegionMIR) that demonstrates the feasibility of medical image retrieval with similar anatomical regions. RegionMIR addresses two major challenges for medical image retrieval i) standardization of clinically relevant searching criteria (e.g., anatomical, pathology-based), and ii) localization of anatomical area of interests that are semantically meaningful. In this work, we propose an ROI image retrieval image network that retrieves images with similar anatomy by extracting anatomical features (via bounding boxes) and evaluate similarity between pairwise anatomy-categorized features between the query and the database of images using contrastive learning. ROI queries are encoded using a contrastive-pretrained encoder that was fine-tuned for anatomy classification, which generates an anatomical-specific latent space for region-correlated image retrieval. During retrieval, we compare the anatomically encoded query to find similar features within a feature database generated from training samples, and retrieve images with similar regions from training samples. We evaluate our approach on both anatomy classification and image retrieval tasks using the Chest ImaGenome Dataset. Our proposed strategy yields an improvement over state-of-the-art pretraining and co-training strategies, from 92.24 to 94.12 (2.03%) classification accuracy in anatomies. We qualitatively evaluate the image retrieval performance demonstrating generalizability across multiple anatomies with different morphology.
CheXstray: Real-time Multi-Modal Data Concordance for Drift Detection in Medical Imaging AI
Feb 06, 2022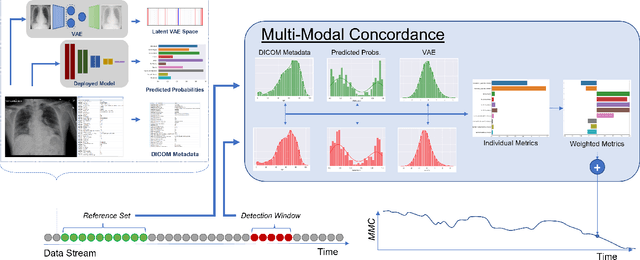

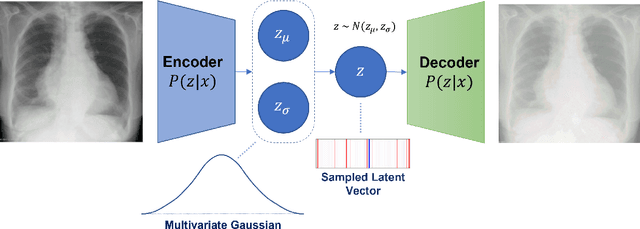
Rapidly expanding Clinical AI applications worldwide have the potential to impact to all areas of medical practice. Medical imaging applications constitute a vast majority of approved clinical AI applications. Though healthcare systems are eager to adopt AI solutions a fundamental question remains: \textit{what happens after the AI model goes into production?} We use the CheXpert and PadChest public datasets to build and test a medical imaging AI drift monitoring workflow that tracks data and model drift without contemporaneous ground truth. We simulate drift in multiple experiments to compare model performance with our novel multi-modal drift metric, which uses DICOM metadata, image appearance representation from a variational autoencoder (VAE), and model output probabilities as input. Through experimentation, we demonstrate a strong proxy for ground truth performance using unsupervised distributional shifts in relevant metadata, predicted probabilities, and VAE latent representation. Our key contributions include (1) proof-of-concept for medical imaging drift detection including use of VAE and domain specific statistical methods (2) a multi-modal methodology for measuring and unifying drift metrics (3) new insights into the challenges and solutions for observing deployed medical imaging AI (4) creation of open-source tools enabling others to easily run their own workflows or scenarios. This work has important implications for addressing the translation gap related to continuous medical imaging AI model monitoring in dynamic healthcare environments.
DeepRadiologyNet: Radiologist Level Pathology Detection in CT Head Images
Dec 02, 2017

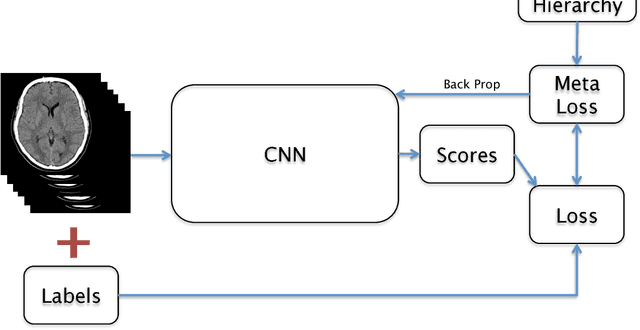
We describe a system to automatically filter clinically significant findings from computerized tomography (CT) head scans, operating at performance levels exceeding that of practicing radiologists. Our system, named DeepRadiologyNet, builds on top of deep convolutional neural networks (CNNs) trained using approximately 3.5 million CT head images gathered from over 24,000 studies taken from January 1, 2015 to August 31, 2015 and January 1, 2016 to April 30 2016 in over 80 clinical sites. For our initial system, we identified 30 phenomenological traits to be recognized in the CT scans. To test the system, we designed a clinical trial using over 4.8 million CT head images (29,925 studies), completely disjoint from the training and validation set, interpreted by 35 US Board Certified radiologists with specialized CT head experience. We measured clinically significant error rates to ascertain whether the performance of DeepRadiologyNet was comparable to or better than that of US Board Certified radiologists. DeepRadiologyNet achieved a clinically significant miss rate of 0.0367% on automatically selected high-confidence studies. Thus, DeepRadiologyNet enables significant reduction in the workload of human radiologists by automatically filtering studies and reporting on the high-confidence ones at an operating point well below the literal error rate for US Board Certified radiologists, estimated at 0.82%.
Dense Volume-to-Volume Vascular Boundary Detection
May 26, 2016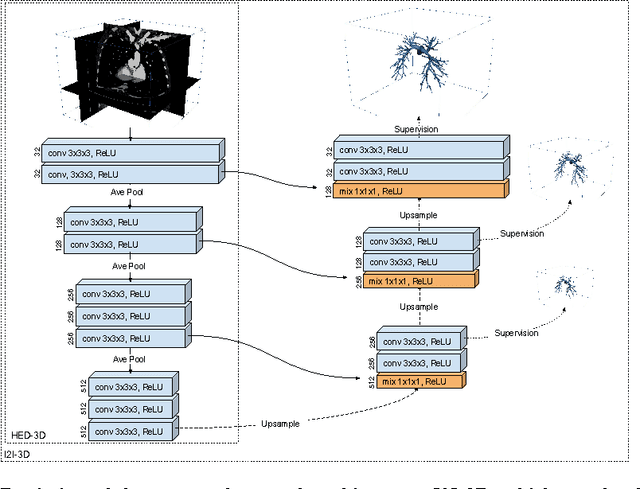

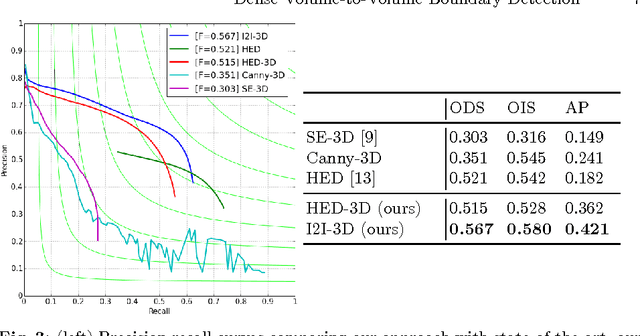
In this work, we present a novel 3D-Convolutional Neural Network (CNN) architecture called I2I-3D that predicts boundary location in volumetric data. Our fine-to-fine, deeply supervised framework addresses three critical issues to 3D boundary detection: (1) efficient, holistic, end-to-end volumetric label training and prediction (2) precise voxel-level prediction to capture fine scale structures prevalent in medical data and (3) directed multi-scale, multi-level feature learning. We evaluate our approach on a dataset consisting of 93 medical image volumes with a wide variety of anatomical regions and vascular structures. In the process, we also introduce HED-3D, a 3D extension of the state-of-the-art 2D edge detector (HED). We show that our deep learning approach out-performs, the current state-of-the-art in 3D vascular boundary detection (structured forests 3D), by a large margin, as well as HED applied to slices, and HED-3D while successfully localizing fine structures. With our approach, boundary detection takes about one minute on a typical 512x512x512 volume.