 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEMPURA: Temporal Event Masked Prediction and Understanding for Reasoning in Action
May 02, 2025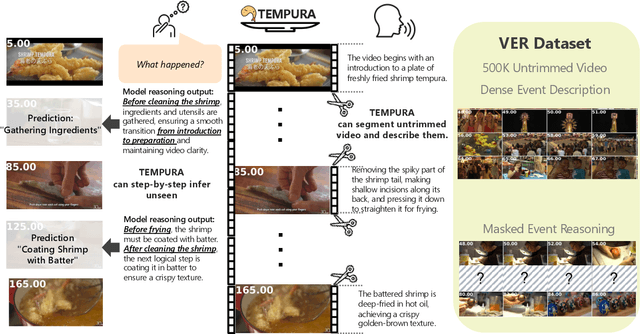

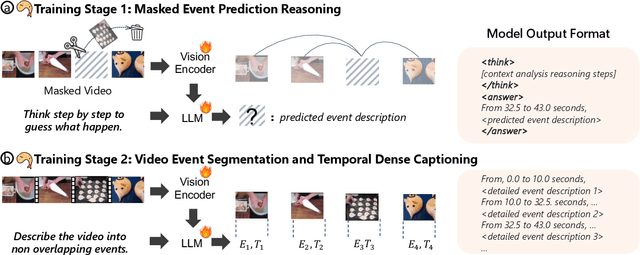
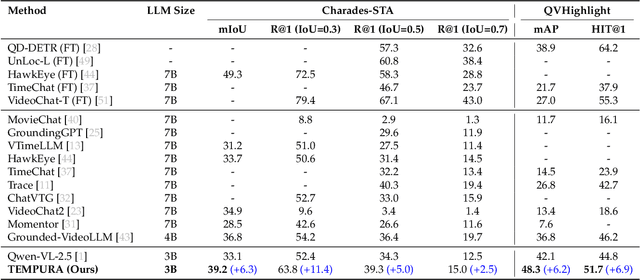
Understanding causal event relationships and achieving fine-grained temporal grounding in videos remain challenging for vision-language models. Existing methods either compress video tokens to reduce temporal resolution, or treat videos as unsegmented streams, which obscures fine-grained event boundaries and limits the modeling of causal dependencies. We propose TEMPURA (Temporal Event Masked Prediction and Understanding for Reasoning in Action), a two-stage training framework that enhances video temporal understanding. TEMPURA first applies masked event prediction reasoning to reconstruct missing events and generate step-by-step causal explanations from dense event annotations, drawing inspiration from effective infilling techniques. TEMPURA then learns to perform video segmentation and dense captioning to decompose videos into non-overlapping events with detailed, timestamp-aligned descriptions. We train TEMPURA on VER, a large-scale dataset curated by us that comprises 1M training instances and 500K videos with temporally aligned event descriptions and structured reasoning steps. Experiments on temporal grounding and highlight detection benchmarks demonstrate that TEMPURA outperforms strong baseline models, confirming that integrating causal reasoning with fine-grained temporal segmentation leads to improved video understanding.
3D-MIR: A Benchmark and Empirical Study on 3D Medical Image Retrieval in Radiology
Nov 23, 2023



The increasing use of medical imaging in healthcare settings presents a significant challenge due to the increasing workload for radiologists, yet it also offers opportunity for enhancing healthcare outcomes if effectively leveraged. 3D image retrieval holds potential to reduce radiologist workloads by enabling clinicians to efficiently search through diagnostically similar or otherwise relevant cases, resulting in faster and more precise diagnoses. However, the field of 3D medical image retrieval is still emerging, lacking established evaluation benchmarks, comprehensive datasets, and thorough studies. This paper attempts to bridge this gap by introducing a novel benchmark for 3D Medical Image Retrieval (3D-MIR) that encompasses four different anatomies imaged with computed tomography. Using this benchmark, we explore a diverse set of search strategies that use aggregated 2D slices, 3D volumes, and multi-modal embeddings from popular multi-modal foundation models as queries. Quantitative and qualitative assessments of each approach are provided alongside an in-depth discussion that offers insight for future research. To promote the advancement of this field, our benchmark, dataset, and code are made publicly available.