 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepWrite: Adaptive Planning for Speech-Driven Text Generation
Aug 06, 2025



People frequently use speech-to-text systems to compose short texts with voice. However, current voice-based interfaces struggle to support composing more detailed, contextually complex texts, especially in scenarios where users are on the move and cannot visually track progress. Longer-form communication, such as composing structured emails or thoughtful responses, requires persistent context tracking, structured guidance, and adaptability to evolving user intentions--capabilities that conventional dictation tools and voice assistants do not support. We introduce StepWrite, a large language model-driven voice-based interaction system that augments human writing ability by enabling structured, hands-free and eyes-free composition of longer-form texts while on the move. StepWrite decomposes the writing process into manageable subtasks and sequentially guides users with contextually-aware non-visual audio prompts. StepWrite reduces cognitive load by offloading the context-tracking and adaptive planning tasks to the models. Unlike baseline methods like standard dictation features (e.g., Microsoft Word) and conversational voice assistants (e.g., ChatGPT Advanced Voice Mode), StepWrite dynamically adapts its prompts based on the evolving context and user intent, and provides coherent guidance without compromising user autonomy. An empirical evaluation with 25 participants engaging in mobile or stationary hands-occupied activities demonstrated that StepWrite significantly reduces cognitive load, improves usability and user satisfaction compared to baseline methods. Technical evaluations further confirmed StepWrite's capability in dynamic contextual prompt generation, accurate tone alignment, and effective fact checking. This work highlights the potential of structured, context-aware voice interactions in enhancing hands-free and eye-free communication in everyday multitasking scenarios.
TEMPURA: Temporal Event Masked Prediction and Understanding for Reasoning in Action
May 02, 2025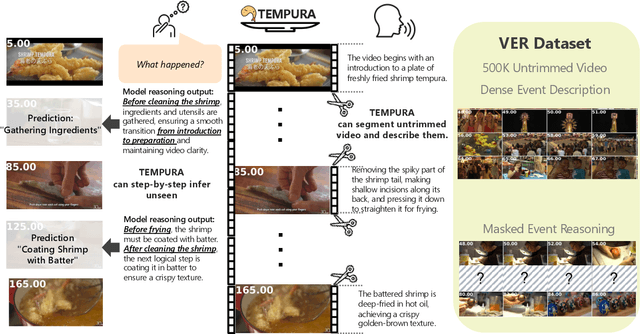

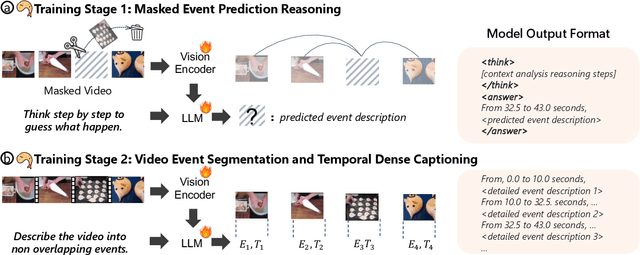
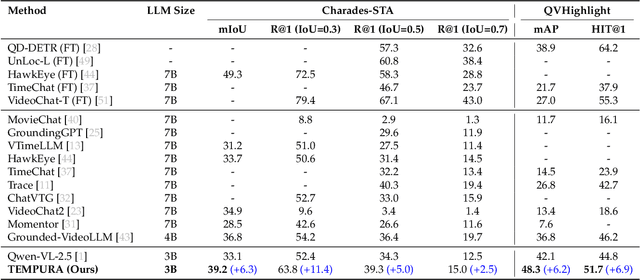
Understanding causal event relationships and achieving fine-grained temporal grounding in videos remain challenging for vision-language models. Existing methods either compress video tokens to reduce temporal resolution, or treat videos as unsegmented streams, which obscures fine-grained event boundaries and limits the modeling of causal dependencies. We propose TEMPURA (Temporal Event Masked Prediction and Understanding for Reasoning in Action), a two-stage training framework that enhances video temporal understanding. TEMPURA first applies masked event prediction reasoning to reconstruct missing events and generate step-by-step causal explanations from dense event annotations, drawing inspiration from effective infilling techniques. TEMPURA then learns to perform video segmentation and dense captioning to decompose videos into non-overlapping events with detailed, timestamp-aligned descriptions. We train TEMPURA on VER, a large-scale dataset curated by us that comprises 1M training instances and 500K videos with temporally aligned event descriptions and structured reasoning steps. Experiments on temporal grounding and highlight detection benchmarks demonstrate that TEMPURA outperforms strong baseline models, confirming that integrating causal reasoning with fine-grained temporal segmentation leads to improved video understanding.
AutoPresent: Designing Structured Visuals from Scratch
Jan 01, 2025
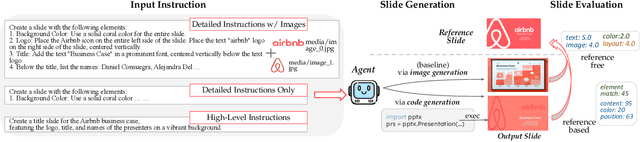
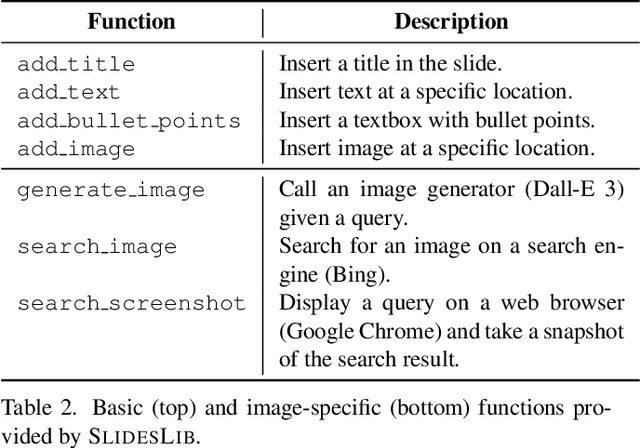
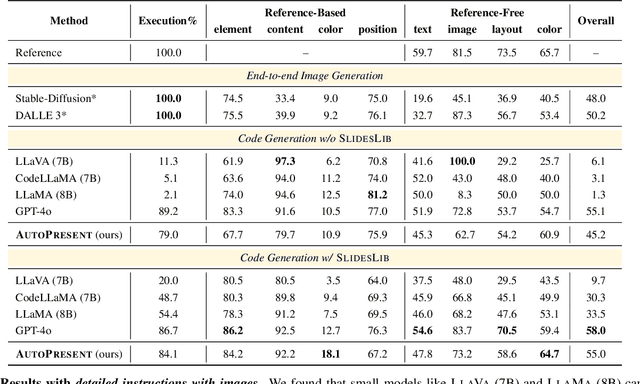
Designing structured visuals such as presentation slides is essential for communicative needs, necessitating both content creation and visual planning skills. In this work, we tackle the challenge of automated slide generation, where models produce slide presentations from natural language (NL) instructions. We first introduce the SlidesBench benchmark, the first benchmark for slide generation with 7k training and 585 testing examples derived from 310 slide decks across 10 domains. SlidesBench supports evaluations that are (i)reference-based to measure similarity to a target slide, and (ii)reference-free to measure the design quality of generated slides alone. We benchmark end-to-end image generation and program generation methods with a variety of models, and find that programmatic methods produce higher-quality slides in user-interactable formats. Built on the success of program generation, we create AutoPresent, an 8B Llama-based model trained on 7k pairs of instructions paired with code for slide generation, and achieve results comparable to the closed-source model GPT-4o. We further explore iterative design refinement where the model is tasked to self-refine its own output, and we found that this process improves the slide's quality. We hope that our work will provide a basis for future work on generating structured visuals.
Long-Form Answers to Visual Questions from Blind and Low Vision People
Aug 12, 2024



Vision language models can now generate long-form answers to questions about images - long-form visual question answers (LFVQA). We contribute VizWiz-LF, a dataset of long-form answers to visual questions posed by blind and low vision (BLV) users. VizWiz-LF contains 4.2k long-form answers to 600 visual questions, collected from human expert describers and six VQA models. We develop and annotate functional roles of sentences of LFVQA and demonstrate that long-form answers contain information beyond the question answer such as explanations and suggestions. We further conduct automatic and human evaluations with BLV and sighted people to evaluate long-form answers. BLV people perceive both human-written and generated long-form answers to be plausible, but generated answers often hallucinate incorrect visual details, especially for unanswerable visual questions (e.g., blurry or irrelevant images). To reduce hallucinations, we evaluate the ability of VQA models to abstain from answering unanswerable questions across multiple prompting strategies.
Towards Bidirectional Human-AI Alignment: A Systematic Review for Clarifications, Framework, and Future Directions
Jun 17, 2024Recent advancements in general-purpose AI have highlighted the importance of guiding AI systems towards the intended goals, ethical principles, and values of individuals and groups, a concept broadly recognized as alignment. However, the lack of clarified definitions and scopes of human-AI alignment poses a significant obstacle, hampering collaborative efforts across research domains to achieve this alignment. In particular, ML- and philosophy-oriented alignment research often views AI alignment as a static, unidirectional process (i.e., aiming to ensure that AI systems' objectives match humans) rather than an ongoing, mutual alignment problem [429]. This perspective largely neglects the long-term interaction and dynamic changes of alignment. To understand these gaps, we introduce a systematic review of over 400 papers published between 2019 and January 2024, spanning multiple domains such as Human-Computer Interaction (HCI), Natural Language Processing (NLP), Machine Learning (ML), and others. We characterize, define and scope human-AI alignment. From this, we present a conceptual framework of "Bidirectional Human-AI Alignment" to organize the literature from a human-centered perspective. This framework encompasses both 1) conventional studies of aligning AI to humans that ensures AI produces the intended outcomes determined by humans, and 2) a proposed concept of aligning humans to AI, which aims to help individuals and society adjust to AI advancements both cognitively and behaviorally. Additionally, we articulate the key findings derived from literature analysis, including discussions about human values, interaction techniques, and evaluations. To pave the way for future studies, we envision three key challenges for future directions and propose examples of potential future solutions.
"This really lets us see the entire world:" Designing a conversational telepresence robot for homebound older adults
May 23, 2024



In this paper, we explore the design and use of conversational telepresence robots to help homebound older adults interact with the external world. An initial needfinding study (N=8) using video vignettes revealed older adults' experiential needs for robot-mediated remote experiences such as exploration, reminiscence and social participation. We then designed a prototype system to support these goals and conducted a technology probe study (N=11) to garner a deeper understanding of user preferences for remote experiences. The study revealed user interactive patterns in each desired experience, highlighting the need of robot guidance, social engagements with the robot and the remote bystanders. Our work identifies a novel design space where conversational telepresence robots can be used to foster meaningful interactions in the remote physical environment. We offer design insights into the robot's proactive role in providing guidance and using dialogue to create personalized, contextualized and meaningful experiences.
UIClip: A Data-driven Model for Assessing User Interface Design
Apr 18, 2024User interface (UI) design is a difficult yet important task for ensuring the usability, accessibility, and aesthetic qualities of applications. In our paper, we develop a machine-learned model, UIClip, for assessing the design quality and visual relevance of a UI given its screenshot and natural language description. To train UIClip, we used a combination of automated crawling, synthetic augmentation, and human ratings to construct a large-scale dataset of UIs, collated by description and ranked by design quality. Through training on the dataset, UIClip implicitly learns properties of good and bad designs by i) assigning a numerical score that represents a UI design's relevance and quality and ii) providing design suggestions. In an evaluation that compared the outputs of UIClip and other baselines to UIs rated by 12 human designers, we found that UIClip achieved the highest agreement with ground-truth rankings. Finally, we present three example applications that demonstrate how UIClip can facilitate downstream applications that rely on instantaneous assessment of UI design quality: i) UI code generation, ii) UI design tips generation, and iii) quality-aware UI example search.