 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFerret-UI Lite: Lessons from Building Small On-Device GUI Agents
Sep 30, 2025
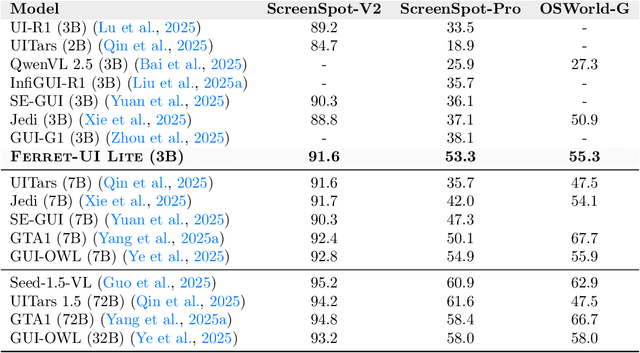
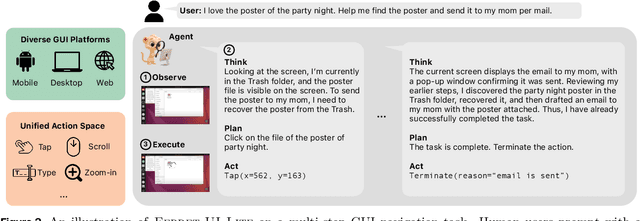
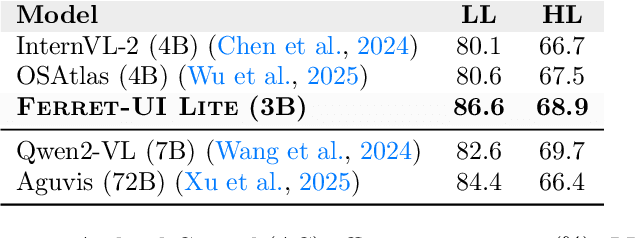
Developing autonomous agents that effectively interact with Graphic User Interfaces (GUIs) remains a challenging open problem, especially for small on-device models. In this paper, we present Ferret-UI Lite, a compact, end-to-end GUI agent that operates across diverse platforms, including mobile, web, and desktop. Utilizing techniques optimized for developing small models, we build our 3B Ferret-UI Lite agent through curating a diverse GUI data mixture from real and synthetic sources, strengthening inference-time performance through chain-of-thought reasoning and visual tool-use, and reinforcement learning with designed rewards. Ferret-UI Lite achieves competitive performance with other small-scale GUI agents. In GUI grounding, Ferret-UI Lite attains scores of $91.6\%$, $53.3\%$, and $61.2\%$ on the ScreenSpot-V2, ScreenSpot-Pro, and OSWorld-G benchmarks, respectively. For GUI navigation, Ferret-UI Lite achieves success rates of $28.0\%$ on AndroidWorld and $19.8\%$ on OSWorld. We share our methods and lessons learned from developing compact, on-device GUI agents.
UICoder: Finetuning Large Language Models to Generate User Interface Code through Automated Feedback
Jun 11, 2024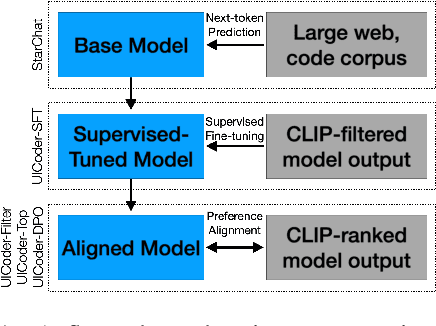

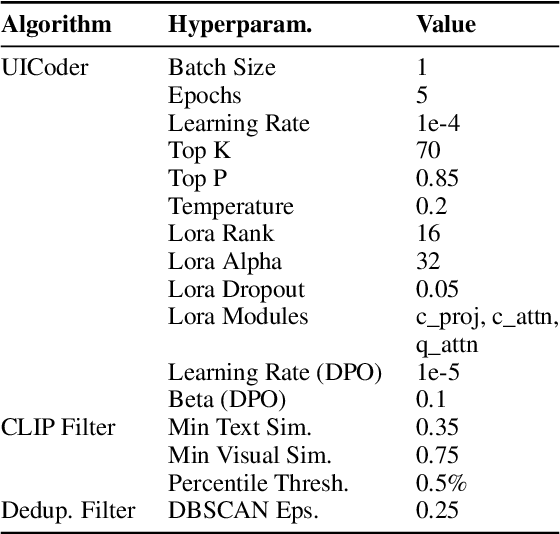

Large language models (LLMs) struggle to consistently generate UI code that compiles and produces visually relevant designs. Existing approaches to improve generation rely on expensive human feedback or distilling a proprietary model. In this paper, we explore the use of automated feedback (compilers and multi-modal models) to guide LLMs to generate high-quality UI code. Our method starts with an existing LLM and iteratively produces improved models by self-generating a large synthetic dataset using an original model, applying automated tools to aggressively filter, score, and de-duplicate the data into a refined higher quality dataset. The original LLM is improved by finetuning on this refined dataset. We applied our approach to several open-source LLMs and compared the resulting performance to baseline models with both automated metrics and human preferences. Our evaluation shows the resulting models outperform all other downloadable baselines and approach the performance of larger proprietary models.
UIClip: A Data-driven Model for Assessing User Interface Design
Apr 18, 2024User interface (UI) design is a difficult yet important task for ensuring the usability, accessibility, and aesthetic qualities of applications. In our paper, we develop a machine-learned model, UIClip, for assessing the design quality and visual relevance of a UI given its screenshot and natural language description. To train UIClip, we used a combination of automated crawling, synthetic augmentation, and human ratings to construct a large-scale dataset of UIs, collated by description and ranked by design quality. Through training on the dataset, UIClip implicitly learns properties of good and bad designs by i) assigning a numerical score that represents a UI design's relevance and quality and ii) providing design suggestions. In an evaluation that compared the outputs of UIClip and other baselines to UIs rated by 12 human designers, we found that UIClip achieved the highest agreement with ground-truth rankings. Finally, we present three example applications that demonstrate how UIClip can facilitate downstream applications that rely on instantaneous assessment of UI design quality: i) UI code generation, ii) UI design tips generation, and iii) quality-aware UI example search.
BISCUIT: Scaffolding LLM-Generated Code with Ephemeral UIs in Computational Notebooks
Apr 12, 2024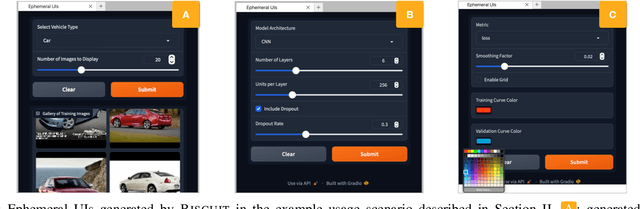
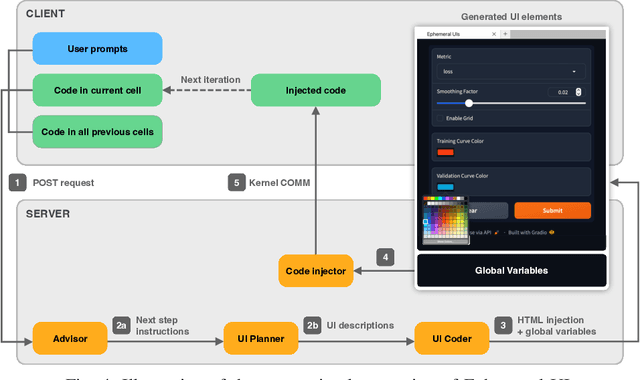
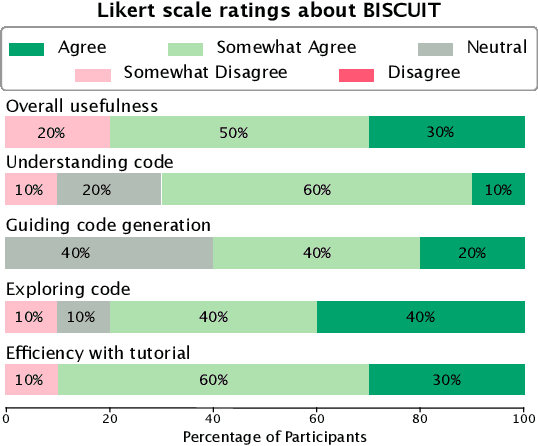
Novices frequently engage with machine learning tutorials in computational notebooks and have been adopting code generation technologies based on large language models (LLMs). However, they encounter difficulties in understanding and working with code produced by LLMs. To mitigate these challenges, we introduce a novel workflow into computational notebooks that augments LLM-based code generation with an additional ephemeral UI step, offering users UI-based scaffolds as an intermediate stage between user prompts and code generation. We present this workflow in BISCUIT, an extension for JupyterLab that provides users with ephemeral UIs generated by LLMs based on the context of their code and intentions, scaffolding users to understand, guide, and explore with LLM-generated code. Through a user study where 10 novices used BISCUIT for machine learning tutorials, we discover that BISCUIT offers user semantic representation of code to aid their understanding, reduces the complexity of prompt engineering, and creates a playground for users to explore different variables and iterate on their ideas. We discuss the implications of our findings for UI-centric interactive paradigm in code generation LLMs.
Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs
Apr 08, 2024Recent advancements in multimodal large language models (MLLMs) have been noteworthy, yet, these general-domain MLLMs often fall short in their ability to comprehend and interact effectively with user interface (UI) screens. In this paper, we present Ferret-UI, a new MLLM tailored for enhanced understanding of mobile UI screens, equipped with referring, grounding, and reasoning capabilities. Given that UI screens typically exhibit a more elongated aspect ratio and contain smaller objects of interest (e.g., icons, texts) than natural images, we incorporate "any resolution" on top of Ferret to magnify details and leverage enhanced visual features. Specifically, each screen is divided into 2 sub-images based on the original aspect ratio (i.e., horizontal division for portrait screens and vertical division for landscape screens). Both sub-images are encoded separately before being sent to LLMs. We meticulously gather training samples from an extensive range of elementary UI tasks, such as icon recognition, find text, and widget listing. These samples are formatted for instruction-following with region annotations to facilitate precise referring and grounding. To augment the model's reasoning ability, we further compile a dataset for advanced tasks, including detailed description, perception/interaction conversations, and function inference. After training on the curated datasets, Ferret-UI exhibits outstanding comprehension of UI screens and the capability to execute open-ended instructions. For model evaluation, we establish a comprehensive benchmark encompassing all the aforementioned tasks. Ferret-UI excels not only beyond most open-source UI MLLMs, but also surpasses GPT-4V on all the elementary UI tasks.
AXNav: Replaying Accessibility Tests from Natural Language
Oct 13, 2023Developers and quality assurance testers often rely on manual testing to test accessibility features throughout the product lifecycle. Unfortunately, manual testing can be tedious, often has an overwhelming scope, and can be difficult to schedule amongst other development milestones. Recently, Large Language Models (LLMs) have been used for a variety of tasks including automation of UIs, however to our knowledge no one has yet explored their use in controlling assistive technologies for the purposes of supporting accessibility testing. In this paper, we explore the requirements of a natural language based accessibility testing workflow, starting with a formative study. From this we build a system that takes as input a manual accessibility test (e.g., ``Search for a show in VoiceOver'') and uses an LLM combined with pixel-based UI Understanding models to execute the test and produce a chaptered, navigable video. In each video, to help QA testers we apply heuristics to detect and flag accessibility issues (e.g., Text size not increasing with Large Text enabled, VoiceOver navigation loops). We evaluate this system through a 10 participant user study with accessibility QA professionals who indicated that the tool would be very useful in their current work and performed tests similarly to how they would manually test the features. The study also reveals insights for future work on using LLMs for accessibility testing.
ILuvUI: Instruction-tuned LangUage-Vision modeling of UIs from Machine Conversations
Oct 07, 2023Multimodal Vision-Language Models (VLMs) enable powerful applications from their fused understanding of images and language, but many perform poorly on UI tasks due to the lack of UI training data. In this paper, we adapt a recipe for generating paired text-image training data for VLMs to the UI domain by combining existing pixel-based methods with a Large Language Model (LLM). Unlike prior art, our method requires no human-provided annotations, and it can be applied to any dataset of UI screenshots. We generate a dataset of 335K conversational examples paired with UIs that cover Q&A, UI descriptions, and planning, and use it to fine-tune a conversational VLM for UI tasks. To assess the performance of our model, we benchmark it on UI element detection tasks, evaluate response quality, and showcase its applicability to multi-step UI navigation and planning.
Sketch-based Creativity Support Tools using Deep Learning
Nov 19, 2021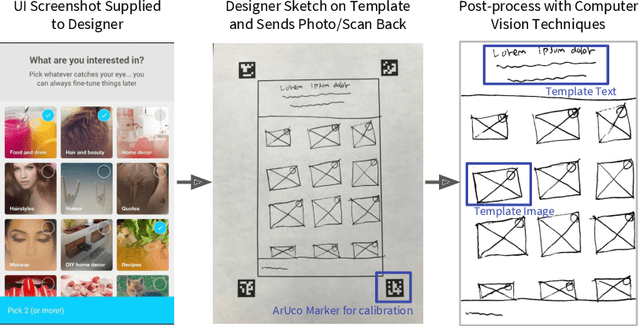

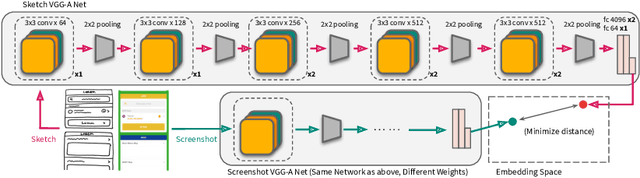
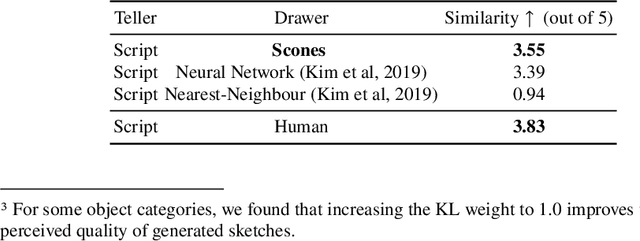
Sketching is a natural and effective visual communication medium commonly used in creative processes. Recent developments in deep-learning models drastically improved machines' ability in understanding and generating visual content. An exciting area of development explores deep-learning approaches used to model human sketches, opening opportunities for creative applications. This chapter describes three fundamental steps in developing deep-learning-driven creativity support tools that consumes and generates sketches: 1) a data collection effort that generated a new paired dataset between sketches and mobile user interfaces; 2) a sketch-based user interface retrieval system adapted from state-of-the-art computer vision techniques; and, 3) a conversational sketching system that supports the novel interaction of a natural-language-based sketch/critique authoring process. In this chapter, we survey relevant prior work in both the deep-learning and human-computer-interaction communities, document the data collection process and the systems' architectures in detail, present qualitative and quantitative results, and paint the landscape of several future research directions in this exciting area.
A Computational Method for Evaluating UI Patterns
Jul 11, 2018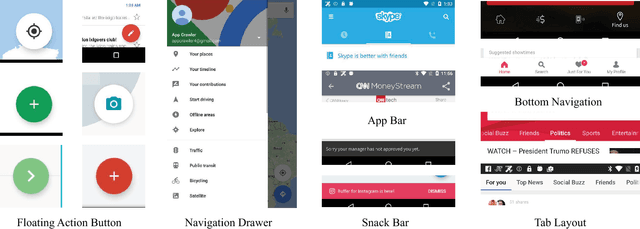
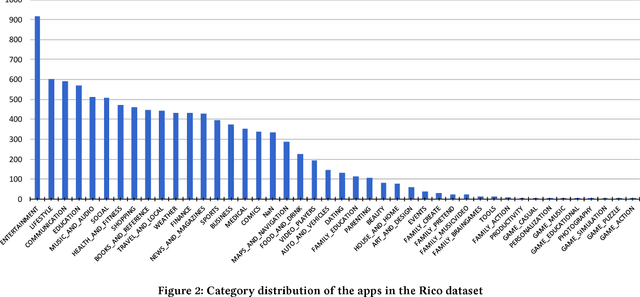


UI design languages, such as Google's Material Design, make applications both easier to develop and easier to learn by providing a set of standard UI components. Nonetheless, it is hard to assess the impact of design languages in the wild. Moreover, designers often get stranded by strong-opinionated debates around the merit of certain UI components, such as the Floating Action Button and the Navigation Drawer. To address these challenges, this short paper introduces a method for measuring the impact of design languages and informing design debates through analyzing a dataset consisting of view hierarchies, screenshots, and app metadata for more than 9,000 mobile apps. Our data analysis shows that use of Material Design is positively correlated to app ratings, and to some extent, also the number of installs. Furthermore, we show that use of UI components vary by app category, suggesting a more nuanced view needed in design debates.
Home Location Identification of Twitter Users
Mar 07, 2014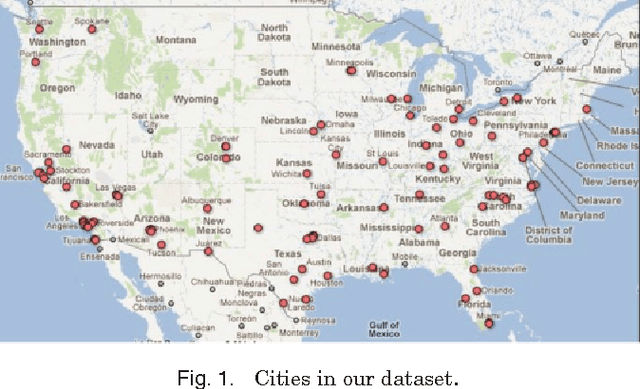
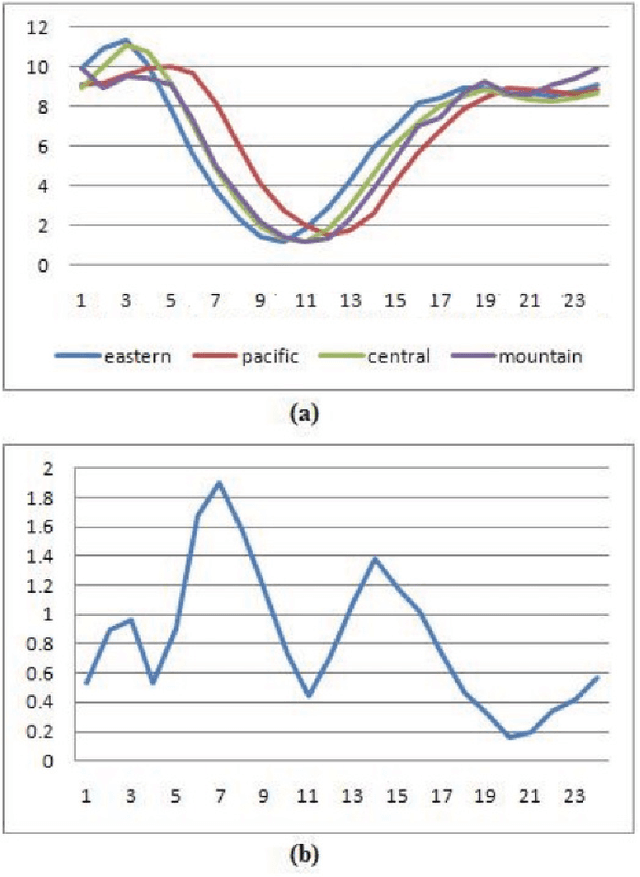
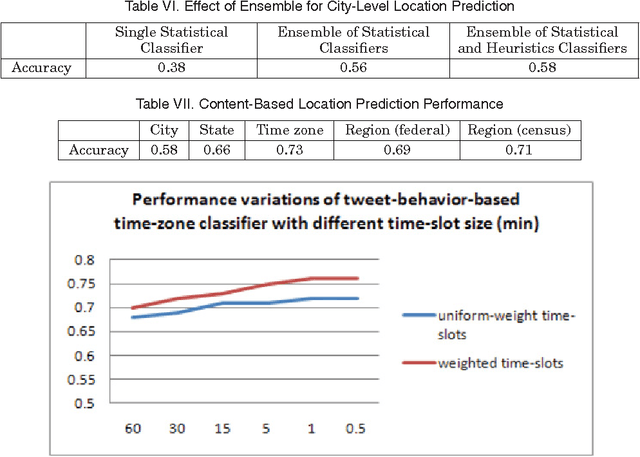
We present a new algorithm for inferring the home location of Twitter users at different granularities, including city, state, time zone or geographic region, using the content of users tweets and their tweeting behavior. Unlike existing approaches, our algorithm uses an ensemble of statistical and heuristic classifiers to predict locations and makes use of a geographic gazetteer dictionary to identify place-name entities. We find that a hierarchical classification approach, where time zone, state or geographic region is predicted first and city is predicted next, can improve prediction accuracy. We have also analyzed movement variations of Twitter users, built a classifier to predict whether a user was travelling in a certain period of time and use that to further improve the location detection accuracy. Experimental evidence suggests that our algorithm works well in practice and outperforms the best existing algorithms for predicting the home location of Twitter users.