 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlue Data Intelligence Layer: Streaming Data and Agents for Multi-source Multi-modal Data-Centric Applications
Apr 16, 2026NL2SQL systems aim to address the growing need for natural language interaction with data. However, real-world information rarely maps to a single SQL query because (1) users express queries iteratively (2) questions often span multiple data sources beyond the closed-world assumption of a single database, and (3) queries frequently rely on commonsense or external knowledge. Consequently, satisfying realistic data needs require integrating heterogeneous sources, modalities, and contextual data. In this paper, we present Blue's Data Intelligence Layer (DIL) designed to support multi-source, multi-modal, and data-centric applications. Blue is a compound AI system that orchestrates agents and data for enterprise settings. DIL serves as the data intelligence layer for agentic data processing, to bridge the semantic gap between user intent and available information by unifying structured enterprise data, world knowledge accessible through LLMs, and personal context obtained through interaction. At the core of DIL is a data registry that stores metadata for diverse data sources and modalities to enable both native and natural language queries. DIL treats LLMs, the Web, and the User as source 'databases', each with their own query interface, elevating them to first-class data sources. DIL relies on data planners to transform user queries into executable query plans. These plans are declarative abstractions that unify relational operators with other operators spanning multiple modalities. DIL planners support decomposition of complex requests into subqueries, retrieval from diverse sources, and finally reasoning and integration to produce final results. We demonstrate DIL through two interactive scenarios in which user queries dynamically trigger multi-source retrieval, cross-modal reasoning, and result synthesis, illustrating how compound AI systems can move beyond single database NL2SQL.
When and Why does a Model Fail? A Human-in-the-loop Error Detection Framework for Sentiment Analysis
Jun 02, 2021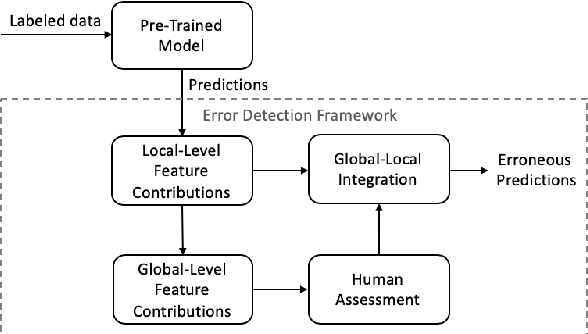


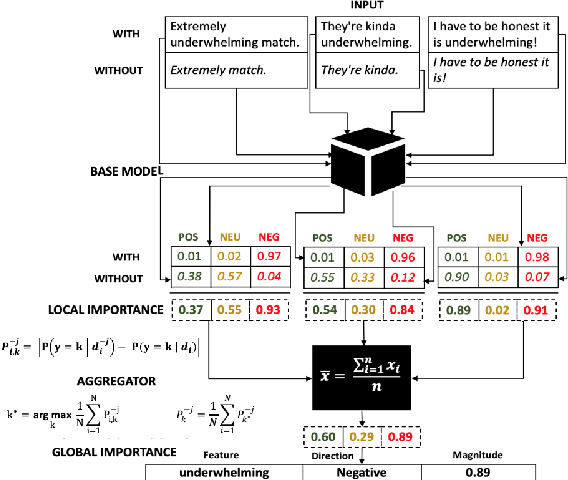
Although deep neural networks have been widely employed and proven effective in sentiment analysis tasks, it remains challenging for model developers to assess their models for erroneous predictions that might exist prior to deployment. Once deployed, emergent errors can be hard to identify in prediction run-time and impossible to trace back to their sources. To address such gaps, in this paper we propose an error detection framework for sentiment analysis based on explainable features. We perform global-level feature validation with human-in-the-loop assessment, followed by an integration of global and local-level feature contribution analysis. Experimental results show that, given limited human-in-the-loop intervention, our method is able to identify erroneous model predictions on unseen data with high precision.
Accountable Error Characterization
May 10, 2021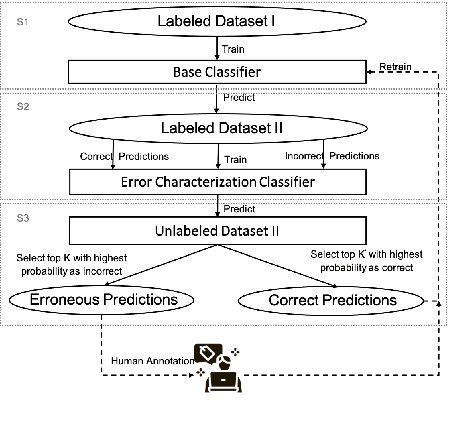

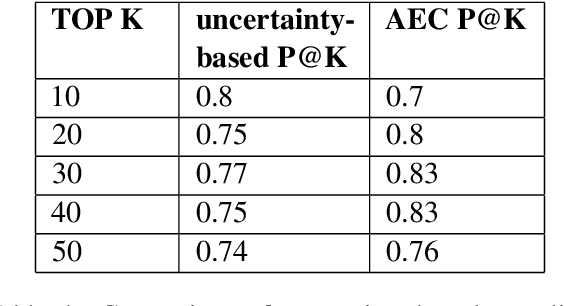
Customers of machine learning systems demand accountability from the companies employing these algorithms for various prediction tasks. Accountability requires understanding of system limit and condition of erroneous predictions, as customers are often interested in understanding the incorrect predictions, and model developers are absorbed in finding methods that can be used to get incremental improvements to an existing system. Therefore, we propose an accountable error characterization method, AEC, to understand when and where errors occur within the existing black-box models. AEC, as constructed with human-understandable linguistic features, allows the model developers to automatically identify the main sources of errors for a given classification system. It can also be used to sample for the set of most informative input points for a next round of training. We perform error detection for a sentiment analysis task using AEC as a case study. Our results on the sample sentiment task show that AEC is able to characterize erroneous predictions into human understandable categories and also achieves promising results on selecting erroneous samples when compared with the uncertainty-based sampling.
Teacher-Student Learning Paradigm for Tri-training: An Efficient Method for Unlabeled Data Exploitation
Sep 25, 2019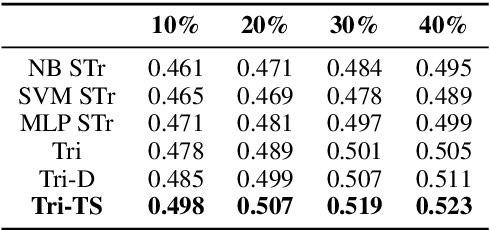
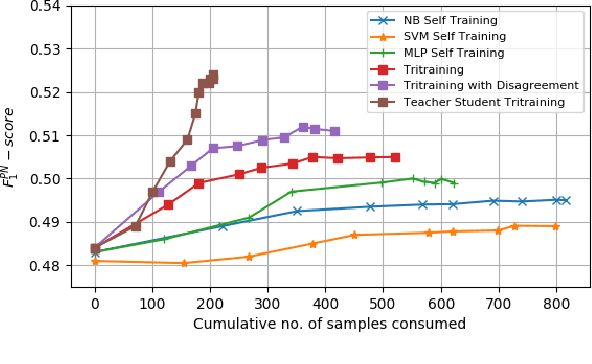
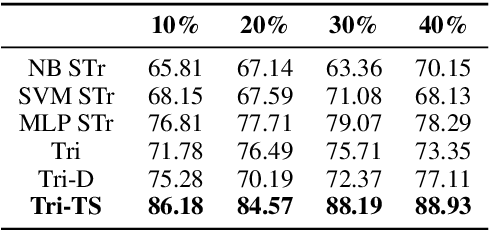
Given that labeled data is expensive to obtain in real-world scenarios, many semi-supervised algorithms have explored the task of exploitation of unlabeled data. Traditional tri-training algorithm and tri-training with disagreement have shown promise in tasks where labeled data is limited. In this work, we introduce a new paradigm for tri-training, mimicking the real world teacher-student learning process. We show that the adaptive teacher-student thresholds used in the proposed method provide more control over the learning process with higher label quality. We perform evaluation on SemEval sentiment analysis task and provide comprehensive comparisons over experimental settings containing varied labeled versus unlabeled data rates. Experimental results show that our method outperforms other strong semi-supervised baselines, while requiring less number of labeled training samples.
Using Structured Representation and Data: A Hybrid Model for Negation and Sentiment in Customer Service Conversations
Jun 11, 2019


Twitter customer service interactions have recently emerged as an effective platform to respond and engage with customers. In this work, we explore the role of negation in customer service interactions, particularly applied to sentiment analysis. We define rules to identify true negation cues and scope more suited to conversational data than existing general review data. Using semantic knowledge and syntactic structure from constituency parse trees, we propose an algorithm for scope detection that performs comparable to state of the art BiLSTM. We further investigate the results of negation scope detection for the sentiment prediction task on customer service conversation data using both a traditional SVM and a Neural Network. We propose an antonym dictionary based method for negation applied to a CNN-LSTM combination model for sentiment analysis. Experimental results show that the antonym-based method outperforms the previous lexicon-based and neural network methods.
Characterizing machine learning process: A maturity framework
Nov 12, 2018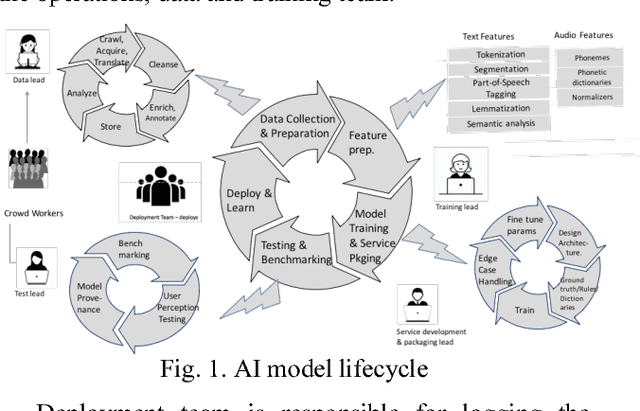
Academic literature on machine learning modeling fails to address how to make machine learning models work for enterprises. For example, existing machine learning processes cannot address how to define business use cases for an AI application, how to convert business requirements from offering managers into data requirements for data scientists, and how to continuously improve AI applications in term of accuracy and fairness, and how to customize general purpose machine learning models with industry, domain, and use case specific data to make them more accurate for specific situations etc. Making AI work for enterprises requires special considerations, tools, methods and processes. In this paper we present a maturity framework for machine learning model lifecycle management for enterprises. Our framework is a re-interpretation of the software Capability Maturity Model (CMM) for machine learning model development process. We present a set of best practices from our personal experience of building large scale real-world machine learning models to help organizations achieve higher levels of maturity independent of their starting point.
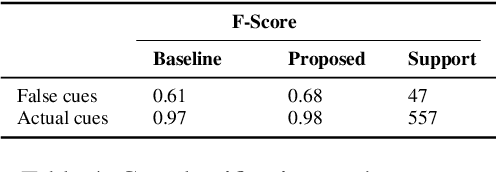
Don't get Lost in Negation: An Effective Negation Handled Dialogue Acts Prediction Algorithm for Twitter Customer Service Conversations
Jul 16, 2018

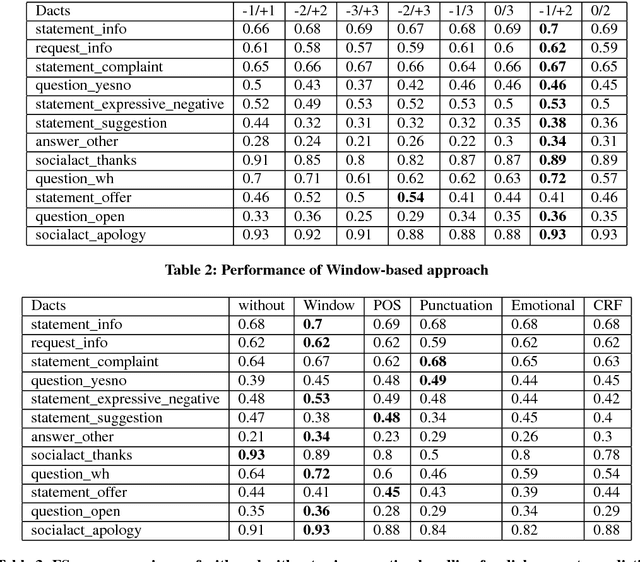
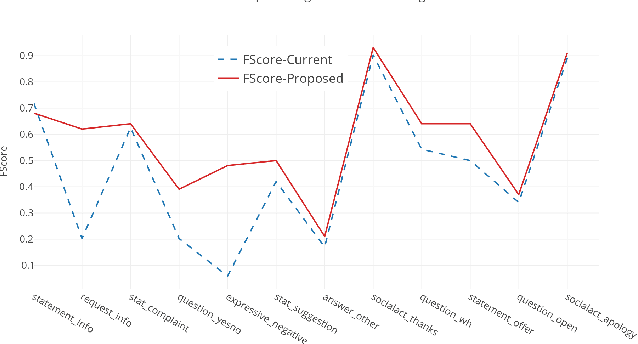
In the last several years, Twitter is being adopted by the companies as an alternative platform to interact with the customers to address their concerns. With the abundance of such unconventional conversation resources, push for developing effective virtual agents is more than ever. To address this challenge, a better understanding of such customer service conversations is required. Lately, there have been several works proposing a novel taxonomy for fine-grained dialogue acts as well as develop algorithms for automatic detection of these acts. The outcomes of these works are providing stepping stones for the ultimate goal of building efficient and effective virtual agents. But none of these works consider handling the notion of negation into the proposed algorithms. In this work, we developed an SVM-based dialogue acts prediction algorithm for Twitter customer service conversations where negation handling is an integral part of the end-to-end solution. For negation handling, we propose several efficient heuristics as well as adopt recent state-of- art third party machine learning based solutions. Empirically we show model's performance gain while handling negation compared to when we don't. Our experiments show that for the informal text such as tweets, the heuristic-based approach is more effective.
"How May I Help You?": Modeling Twitter Customer Service Conversations Using Fine-Grained Dialogue Acts
Sep 15, 2017
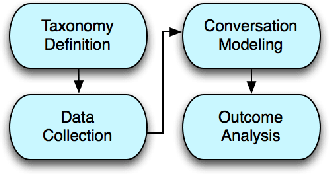
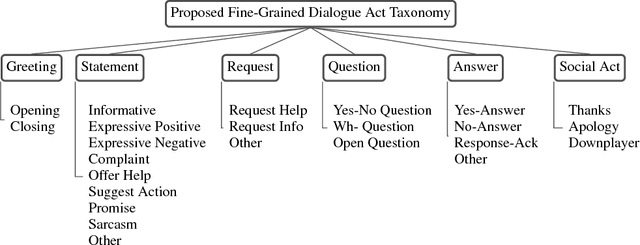
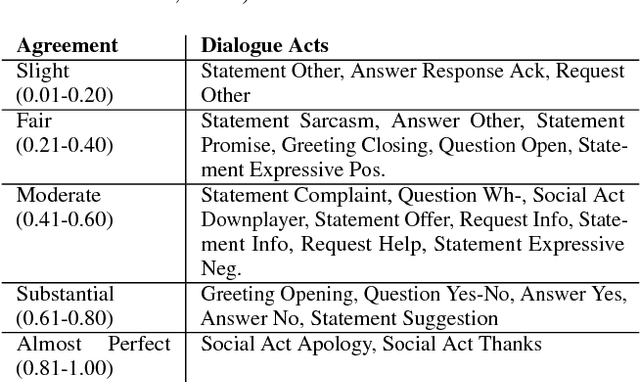
Given the increasing popularity of customer service dialogue on Twitter, analysis of conversation data is essential to understand trends in customer and agent behavior for the purpose of automating customer service interactions. In this work, we develop a novel taxonomy of fine-grained "dialogue acts" frequently observed in customer service, showcasing acts that are more suited to the domain than the more generic existing taxonomies. Using a sequential SVM-HMM model, we model conversation flow, predicting the dialogue act of a given turn in real-time. We characterize differences between customer and agent behavior in Twitter customer service conversations, and investigate the effect of testing our system on different customer service industries. Finally, we use a data-driven approach to predict important conversation outcomes: customer satisfaction, customer frustration, and overall problem resolution. We show that the type and location of certain dialogue acts in a conversation have a significant effect on the probability of desirable and undesirable outcomes, and present actionable rules based on our findings. The patterns and rules we derive can be used as guidelines for outcome-driven automated customer service platforms.
25 Tweets to Know You: A New Model to Predict Personality with Social Media
Apr 18, 2017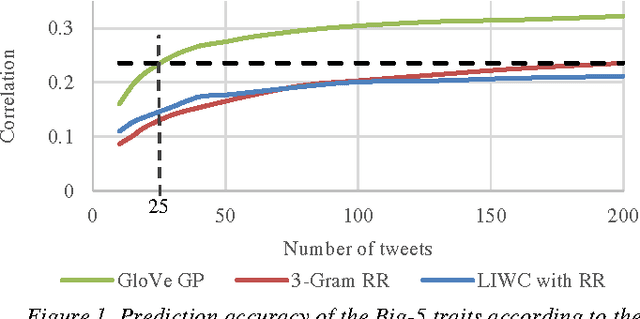
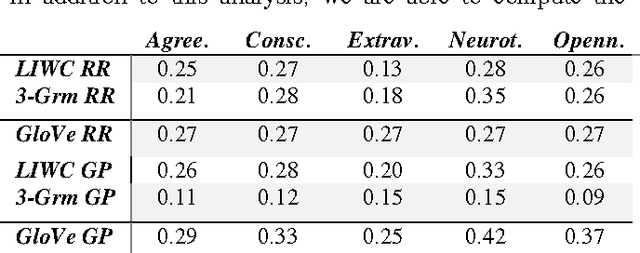
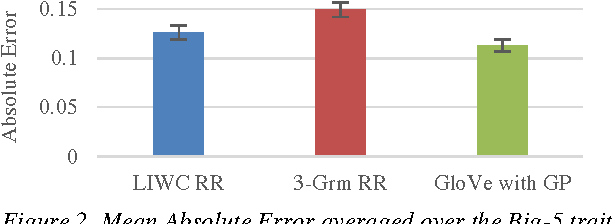
Predicting personality is essential for social applications supporting human-centered activities, yet prior modeling methods with users written text require too much input data to be realistically used in the context of social media. In this work, we aim to drastically reduce the data requirement for personality modeling and develop a model that is applicable to most users on Twitter. Our model integrates Word Embedding features with Gaussian Processes regression. Based on the evaluation of over 1.3K users on Twitter, we find that our model achieves comparable or better accuracy than state of the art techniques with 8 times fewer data.
Fostering User Engagement: Rhetorical Devices for Applause Generation Learnt from TED Talks
Apr 17, 2017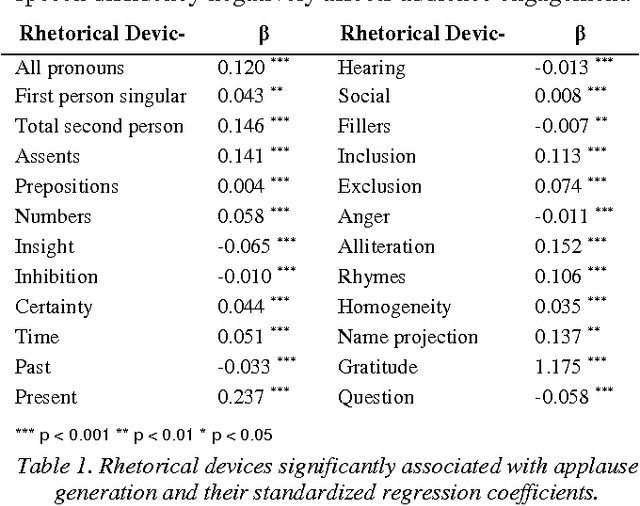
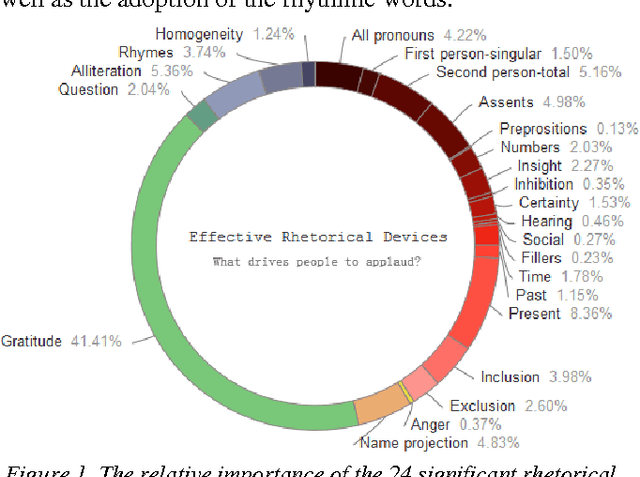
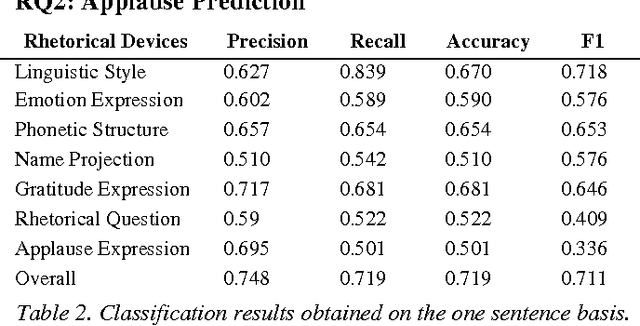
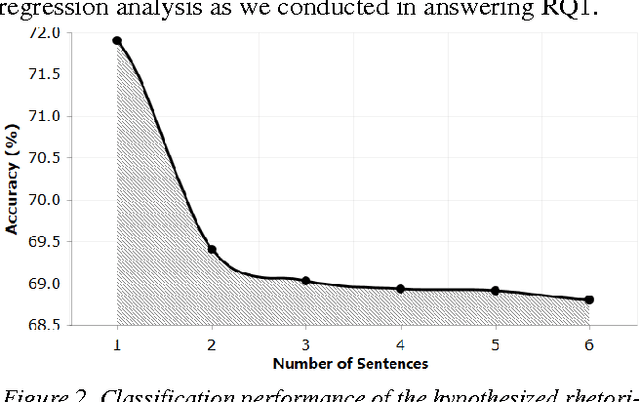
One problem that every presenter faces when delivering a public discourse is how to hold the listeners' attentions or to keep them involved. Therefore, many studies in conversation analysis work on this issue and suggest qualitatively con-structions that can effectively lead to audience's applause. To investigate these proposals quantitatively, in this study we an-alyze the transcripts of 2,135 TED Talks, with a particular fo-cus on the rhetorical devices that are used by the presenters for applause elicitation. Through conducting regression anal-ysis, we identify and interpret 24 rhetorical devices as triggers of audience applauding. We further build models that can rec-ognize applause-evoking sentences and conclude this work with potential implications.