 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBT-DINO: Towards Foundation model based analysis of Digital Breast Tomosynthesis
Dec 15, 2025



Foundation models have shown promise in medical imaging but remain underexplored for three-dimensional imaging modalities. No foundation model currently exists for Digital Breast Tomosynthesis (DBT), despite its use for breast cancer screening. To develop and evaluate a foundation model for DBT (DBT-DINO) across multiple clinical tasks and assess the impact of domain-specific pre-training. Self-supervised pre-training was performed using the DINOv2 methodology on over 25 million 2D slices from 487,975 DBT volumes from 27,990 patients. Three downstream tasks were evaluated: (1) breast density classification using 5,000 screening exams; (2) 5-year risk of developing breast cancer using 106,417 screening exams; and (3) lesion detection using 393 annotated volumes. For breast density classification, DBT-DINO achieved an accuracy of 0.79 (95\% CI: 0.76--0.81), outperforming both the MetaAI DINOv2 baseline (0.73, 95\% CI: 0.70--0.76, p<.001) and DenseNet-121 (0.74, 95\% CI: 0.71--0.76, p<.001). For 5-year breast cancer risk prediction, DBT-DINO achieved an AUROC of 0.78 (95\% CI: 0.76--0.80) compared to DINOv2's 0.76 (95\% CI: 0.74--0.78, p=.57). For lesion detection, DINOv2 achieved a higher average sensitivity of 0.67 (95\% CI: 0.60--0.74) compared to DBT-DINO with 0.62 (95\% CI: 0.53--0.71, p=.60). DBT-DINO demonstrated better performance on cancerous lesions specifically with a detection rate of 78.8\% compared to Dinov2's 77.3\%. Using a dataset of unprecedented size, we developed DBT-DINO, the first foundation model for DBT. DBT-DINO demonstrated strong performance on breast density classification and cancer risk prediction. However, domain-specific pre-training showed variable benefits on the detection task, with ImageNet baseline outperforming DBT-DINO on general lesion detection, indicating that localized detection tasks require further methodological development.
Global Context Is All You Need for Parallel Efficient Tractography Parcellation
Mar 10, 2025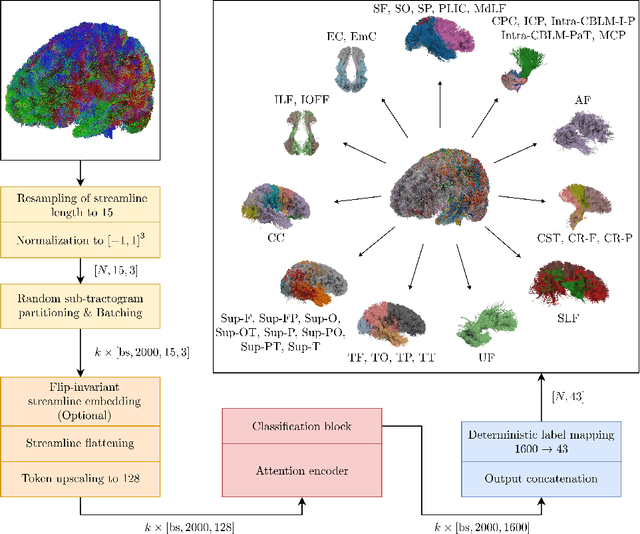
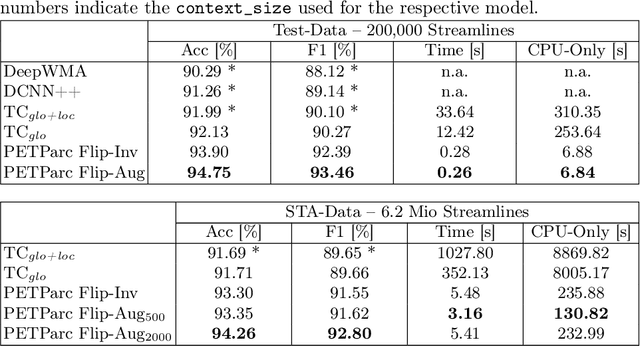

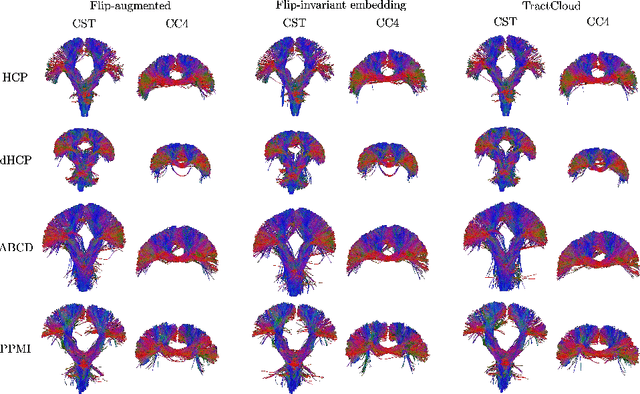
Whole-brain tractography in diffusion MRI is often followed by a parcellation in which each streamline is classified as belonging to a specific white matter bundle, or discarded as a false positive. Efficient parcellation is important both in large-scale studies, which have to process huge amounts of data, and in the clinic, where computational resources are often limited. TractCloud is a state-of-the-art approach that aims to maximize accuracy with a local-global representation. We demonstrate that the local context does not contribute to the accuracy of that approach, and is even detrimental when dealing with pathological cases. Based on this observation, we propose PETParc, a new method for Parallel Efficient Tractography Parcellation. PETParc is a transformer-based architecture in which the whole-brain tractogram is randomly partitioned into sub-tractograms whose streamlines are classified in parallel, while serving as global context for each other. This leads to a speedup of up to two orders of magnitude relative to TractCloud, and permits inference even on clinical workstations without a GPU. PETParc accounts for the lack of streamline orientation either via a novel flip-invariant embedding, or by simply using flips as part of data augmentation. Despite the speedup, results are often even better than those of prior methods. The code and pretrained model will be made public upon acceptance.
Weakly Supervised Segmentation of Hyper-Reflective Foci with Compact Convolutional Transformers and SAM2
Jan 10, 2025Weakly supervised segmentation has the potential to greatly reduce the annotation effort for training segmentation models for small structures such as hyper-reflective foci (HRF) in optical coherence tomography (OCT). However, most weakly supervised methods either involve a strong downsampling of input images, or only achieve localization at a coarse resolution, both of which are unsatisfactory for small structures. We propose a novel framework that increases the spatial resolution of a traditional attention-based Multiple Instance Learning (MIL) approach by using Layer-wise Relevance Propagation (LRP) to prompt the Segment Anything Model (SAM~2), and increases recall with iterative inference. Moreover, we demonstrate that replacing MIL with a Compact Convolutional Transformer (CCT), which adds a positional encoding, and permits an exchange of information between different regions of the OCT image, leads to a further and substantial increase in segmentation accuracy.
Phase-Informed Tool Segmentation for Manual Small-Incision Cataract Surgery
Nov 25, 2024



Cataract surgery is the most common surgical procedure globally, with a disproportionately higher burden in developing countries. While automated surgical video analysis has been explored in general surgery, its application to ophthalmic procedures remains limited. Existing works primarily focus on Phaco cataract surgery, an expensive technique not accessible in regions where cataract treatment is most needed. In contrast, Manual Small-Incision Cataract Surgery (MSICS) is the preferred low-cost, faster alternative in high-volume settings and for challenging cases. However, no dataset exists for MSICS. To address this gap, we introduce Cataract-MSICS, the first comprehensive dataset containing 53 surgical videos annotated for 18 surgical phases and 3,527 frames with 13 surgical tools at the pixel level. We benchmark this dataset on state-of-the-art models and present ToolSeg, a novel framework that enhances tool segmentation by introducing a phase-conditional decoder and a simple yet effective semi-supervised setup leveraging pseudo-labels from foundation models. Our approach significantly improves segmentation performance, achieving a $23.77\%$ to $38.10\%$ increase in mean Dice scores, with a notable boost for tools that are less prevalent and small. Furthermore, we demonstrate that ToolSeg generalizes to other surgical settings, showcasing its effectiveness on the CaDIS dataset.
Is Open-Source There Yet? A Comparative Study on Commercial and Open-Source LLMs in Their Ability to Label Chest X-Ray Reports
Feb 19, 2024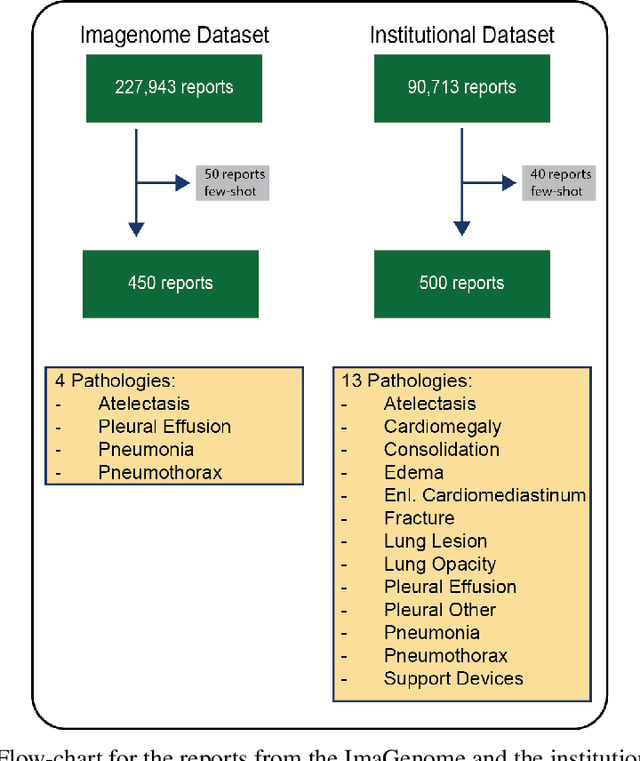
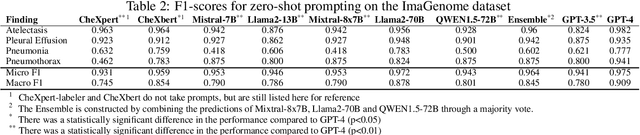
Introduction: With the rapid advances in large language models (LLMs), there have been numerous new open source as well as commercial models. While recent publications have explored GPT-4 in its application to extracting information of interest from radiology reports, there has not been a real-world comparison of GPT-4 to different leading open-source models. Materials and Methods: Two different and independent datasets were used. The first dataset consists of 540 chest x-ray reports that were created at the Massachusetts General Hospital between July 2019 and July 2021. The second dataset consists of 500 chest x-ray reports from the ImaGenome dataset. We then compared the commercial models GPT-3.5 Turbo and GPT-4 from OpenAI to the open-source models Mistral-7B, Mixtral-8x7B, Llama2-13B, Llama2-70B, QWEN1.5-72B and CheXbert and CheXpert-labeler in their ability to accurately label the presence of multiple findings in x-ray text reports using different prompting techniques. Results: On the ImaGenome dataset, the best performing open-source model was Llama2-70B with micro F1-scores of 0.972 and 0.970 for zero- and few-shot prompts, respectively. GPT-4 achieved micro F1-scores of 0.975 and 0.984, respectively. On the institutional dataset, the best performing open-source model was QWEN1.5-72B with micro F1-scores of 0.952 and 0.965 for zero- and few-shot prompting, respectively. GPT-4 achieved micro F1-scores of 0.975 and 0.973, respectively. Conclusion: In this paper, we show that while GPT-4 is superior to open-source models in zero-shot report labeling, the implementation of few-shot prompting can bring open-source models on par with GPT-4. This shows that open-source models could be a performant and privacy preserving alternative to GPT-4 for the task of radiology report classification.
Anisotropic Fanning Aware Low-Rank Tensor Approximation Based Tractography
Jul 03, 2023



Low-rank higher-order tensor approximation has been used successfully to extract discrete directions for tractography from continuous fiber orientation density functions (fODFs). However, while it accounts for fiber crossings, it has so far ignored fanning, which has led to incomplete reconstructions. In this work, we integrate an anisotropic model of fanning based on the Bingham distribution into a recently proposed tractography method that performs low-rank approximation with an Unscented Kalman Filter. Our technical contributions include an initialization scheme for the new parameters, which is based on the Hessian of the low-rank approximation, pre-integration of the required convolution integrals to reduce the computational effort, and representation of the required 3D rotations with quaternions. Results on 12 subjects from the Human Connectome Project confirm that, in almost all considered tracts, our extended model significantly increases completeness of the reconstruction, while reducing excess, at acceptable additional computational cost. Its results are also more accurate than those from a simpler, isotropic fanning model that is based on Watson distributions.
Combining Image Space and q-Space PDEs for Lossless Compression of Diffusion MR Images
Jun 14, 2022
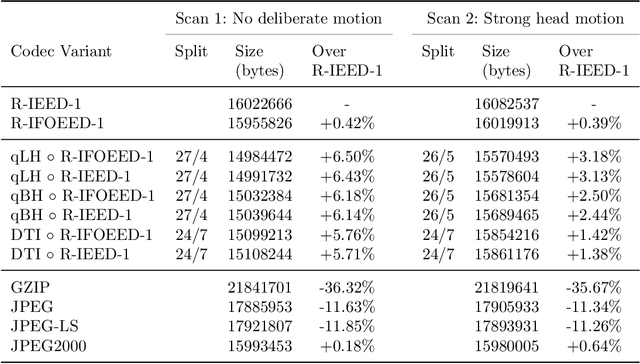
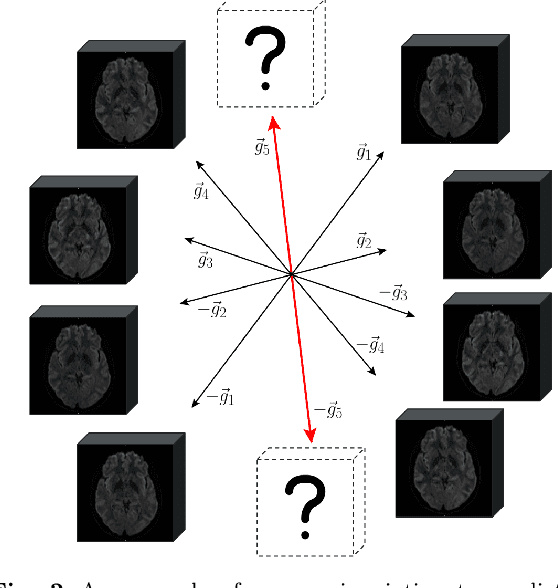
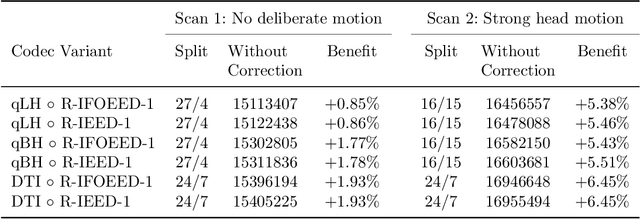
Diffusion MRI is a modern neuroimaging modality with a unique ability to acquire microstructural information by measuring water self-diffusion at the voxel level. However, it generates huge amounts of data, resulting from a large number of repeated 3D scans. Each volume samples a location in q-space, indicating the direction and strength of a diffusion sensitizing gradient during the measurement. This captures detailed information about the self-diffusion, and the tissue microstructure that restricts it. Lossless compression with GZIP is widely used to reduce the memory requirements. We introduce a novel lossless codec for diffusion MRI data. It reduces file sizes by more than 30% compared to GZIP, and also beats lossless codecs from the JPEG family. Our codec builds on recent work on lossless PDE-based compression of 3D medical images, but additionally exploits smoothness in q-space. We demonstrate that, compared to using only image space PDEs, q-space PDEs further improve compression rates. Moreover, implementing them with Finite Element Methods and a custom acceleration significantly reduces computational expense. Finally, we show that our codec clearly benefits from integrating subject motion correction, and slightly from optimizing the order in which the 3D volumes are coded.
Federated Learning for Breast Density Classification: A Real-World Implementation
Sep 17, 2020

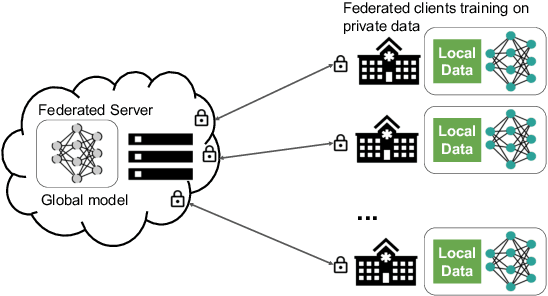
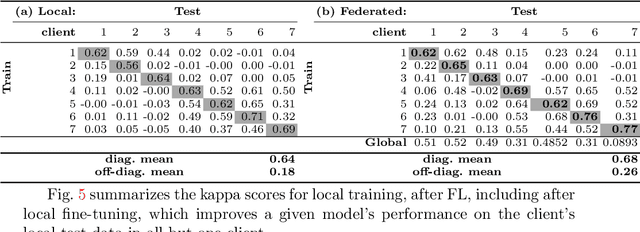
Building robust deep learning-based models requires large quantities of diverse training data. In this study, we investigate the use of federated learning (FL) to build medical imaging classification models in a real-world collaborative setting. Seven clinical institutions from across the world joined this FL effort to train a model for breast density classification based on Breast Imaging, Reporting & Data System (BI-RADS). We show that despite substantial differences among the datasets from all sites (mammography system, class distribution, and data set size) and without centralizing data, we can successfully train AI models in federation. The results show that models trained using FL perform 6.3% on average better than their counterparts trained on an institute's local data alone. Furthermore, we show a 45.8% relative improvement in the models' generalizability when evaluated on the other participating sites' testing data.
Fourth-Order Anisotropic Diffusion for Inpainting and Image Compression
Jun 18, 2020

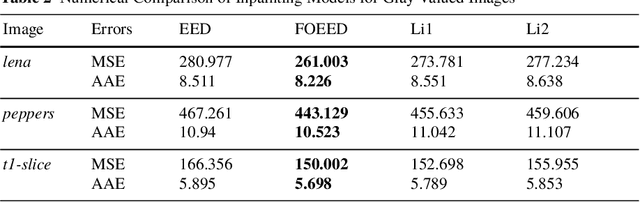

Edge-enhancing diffusion (EED) can reconstruct a close approximation of an original image from a small subset of its pixels. This makes it an attractive foundation for PDE based image compression. In this work, we generalize second-order EED to a fourth-order counterpart. It involves a fourth-order diffusion tensor that is constructed from the regularized image gradient in a similar way as in traditional second-order EED, permitting diffusion along edges, while applying a non-linear diffusivity function across them. We show that our fourth-order diffusion tensor formalism provides a unifying framework for all previous anisotropic fourth-order diffusion based methods, and that it provides additional flexibility. We achieve an efficient implementation using a fast semi-iterative scheme. Experimental results on natural and medical images suggest that our novel fourth-order method produces more accurate reconstructions compared to the existing second-order EED.
Classification on Large Networks: A Quantitative Bound via Motifs and Graphons
Oct 24, 2017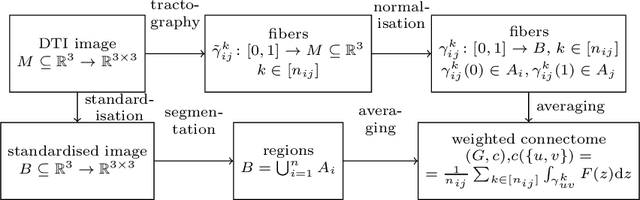

When each data point is a large graph, graph statistics such as densities of certain subgraphs (motifs) can be used as feature vectors for machine learning. While intuitive, motif counts are expensive to compute and difficult to work with theoretically. Via graphon theory, we give an explicit quantitative bound for the ability of motif homomorphisms to distinguish large networks under both generative and sampling noise. Furthermore, we give similar bounds for the graph spectrum and connect it to homomorphism densities of cycles. This results in an easily computable classifier on graph data with theoretical performance guarantee. Our method yields competitive results on classification tasks for the autoimmune disease Lupus Erythematosus.