 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Context Is All You Need for Parallel Efficient Tractography Parcellation
Mar 10, 2025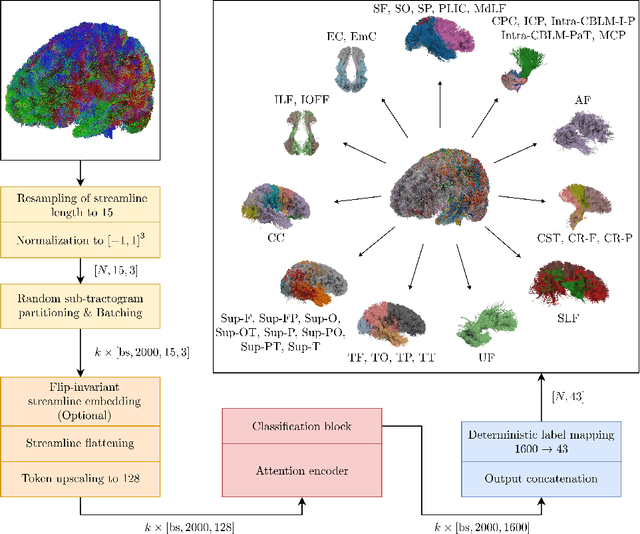
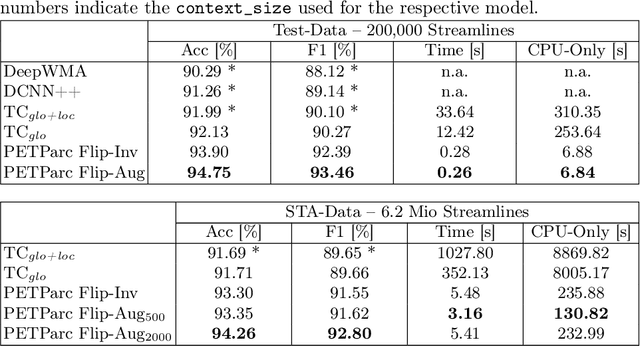

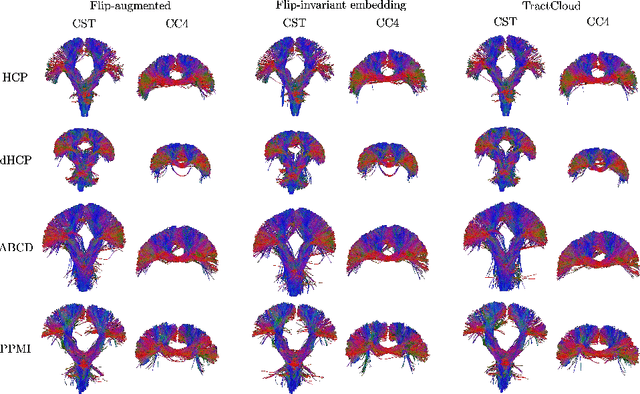
Whole-brain tractography in diffusion MRI is often followed by a parcellation in which each streamline is classified as belonging to a specific white matter bundle, or discarded as a false positive. Efficient parcellation is important both in large-scale studies, which have to process huge amounts of data, and in the clinic, where computational resources are often limited. TractCloud is a state-of-the-art approach that aims to maximize accuracy with a local-global representation. We demonstrate that the local context does not contribute to the accuracy of that approach, and is even detrimental when dealing with pathological cases. Based on this observation, we propose PETParc, a new method for Parallel Efficient Tractography Parcellation. PETParc is a transformer-based architecture in which the whole-brain tractogram is randomly partitioned into sub-tractograms whose streamlines are classified in parallel, while serving as global context for each other. This leads to a speedup of up to two orders of magnitude relative to TractCloud, and permits inference even on clinical workstations without a GPU. PETParc accounts for the lack of streamline orientation either via a novel flip-invariant embedding, or by simply using flips as part of data augmentation. Despite the speedup, results are often even better than those of prior methods. The code and pretrained model will be made public upon acceptance.
Reddiment: Eine SvelteKit- und ElasticSearch-basierte Reddit Sentiment-Analyse
Dec 08, 2023Reddiment is a web-based dashboard that links sentiment analysis of subreddit texts with share prices. The system consists of a backend, frontend and various services. The backend, in Node.js, manages the data and communicates with crawlers that collect Reddit comments and stock market data. Sentiment is analyzed with the help of Vader and TextBlob. The frontend, based on SvelteKit, provides users with a dashboard for visualization. The distribution is carried out via Docker containers and Docker Compose. The project offers expansion options, e.g. the integration of cryptocurrency rates. Reddiment enables the analysis of sentiment and share prices from subreddit data.
#MeTooMaastricht: Building a chatbot to assist survivors of sexual harassment
Sep 06, 2019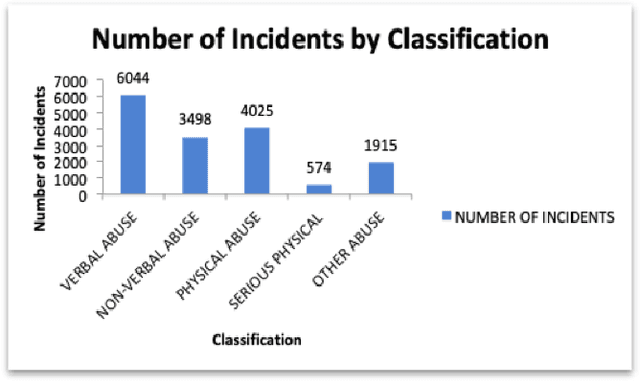


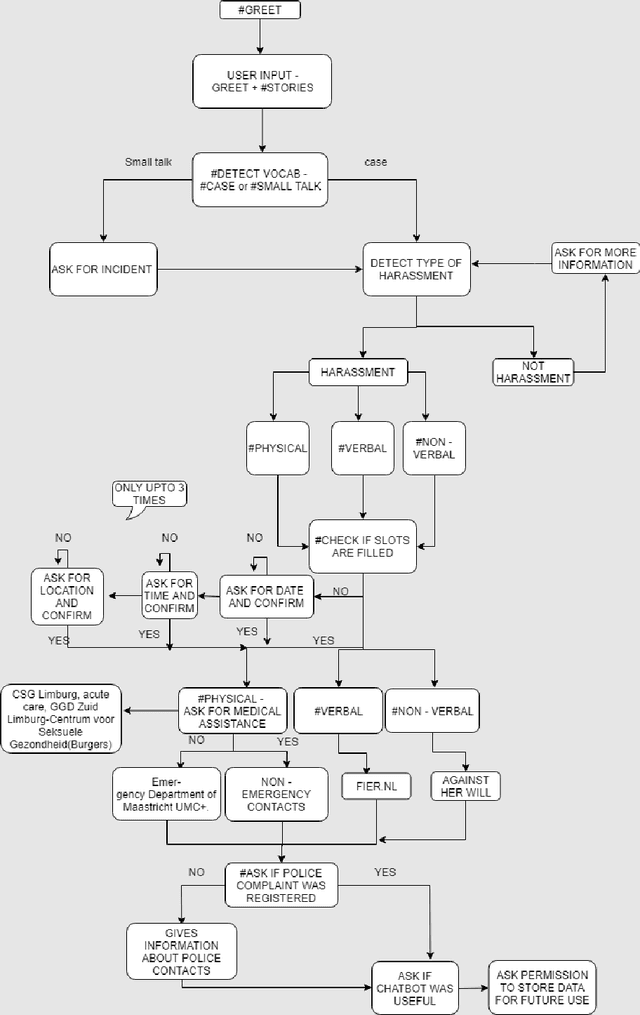
Inspired by the recent social movement of #MeToo, we are building a chatbot to assist survivors of sexual harassment cases (designed for the city of Maastricht but can easily be extended). The motivation behind this work is twofold: properly assist survivors of such events by directing them to appropriate institutions that can offer them help and increase the incident documentation so as to gather more data about harassment cases which are currently under reported. We break down the problem into three data science/machine learning components: harassment type identification (treated as a classification problem), spatio-temporal information extraction (treated as Named Entity Recognition problem) and dialogue with the users (treated as a slot-filling based chatbot). We are able to achieve a success rate of more than 98% for the identification of a harassment-or-not case and around 80% for the specific type harassment identification. Locations and dates are identified with more than 90% accuracy and time occurrences prove more challenging with almost 80%. Finally, initial validation of the chatbot shows great potential for the further development and deployment of such a beneficial for the whole society tool.