 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Vote Veto: A Self-Training Strategy for Low-Shot Learning of a Task-Invariant Embedding to Diagnose Glaucoma
Jan 19, 2021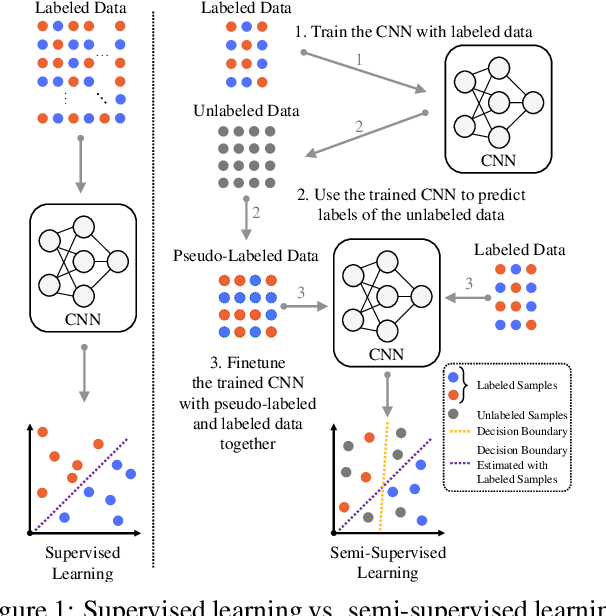

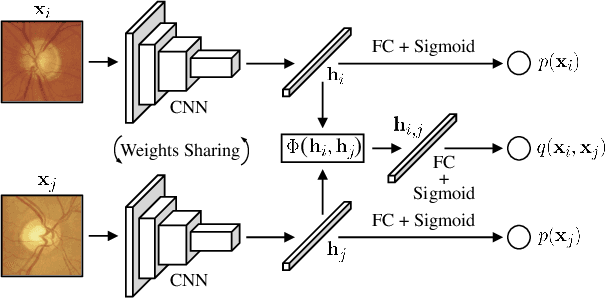
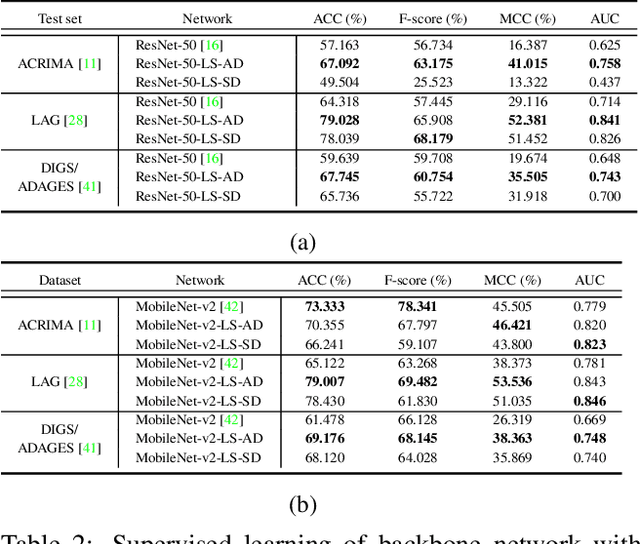
Convolutional neural networks (CNNs) are a promising technique for automated glaucoma diagnosis from images of the fundus, and these images are routinely acquired as part of an ophthalmic exam. Nevertheless, CNNs typically require a large amount of well-labeled data for training, which may not be available in many biomedical image classification applications, especially when diseases are rare and where labeling by experts is costly. This paper makes two contributions to address this issue: (1) It introduces a new network architecture and training method for low-shot learning when labeled data are limited and imbalanced, and (2) it introduces a new semi-supervised learning strategy that uses additional unlabeled training data to achieve great accuracy. Our multi-task twin neural network (MTTNN) can use any backbone CNN, and we demonstrate with ResNet-50 and MobileNet-v2 that its accuracy with limited training data approaches the accuracy of a finetuned backbone trained with a dataset that is 50 times larger. We also introduce One-Vote Veto (OVV) self-training, a semi-supervised learning strategy, that is designed specifically for MTTNNs. By taking both self-predictions and contrastive-predictions of the unlabeled training data into account, OVV self-training provides additional pseudo labels for finetuning a pretrained MTTNN. Using a large dataset with more than 50,000 fundus images acquired over 25 years, extensive experimental results demonstrate the effectiveness of low-shot learning with MTTNN and semi-supervised learning with OVV. Three additional, smaller clinical datasets of fundus images acquired under different conditions (cameras, instruments, locations, populations), are used to demonstrate generalizability of the methods. Source code and pretrained models will be publicly available upon publication.
Neural Reflectance Fields for Appearance Acquisition
Aug 16, 2020
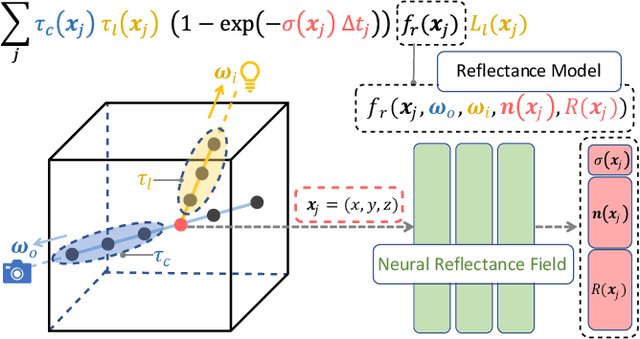
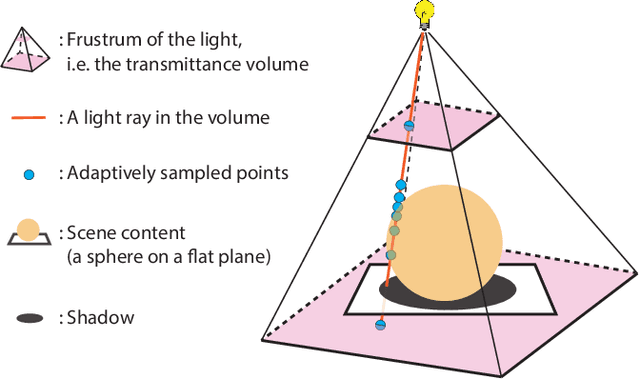
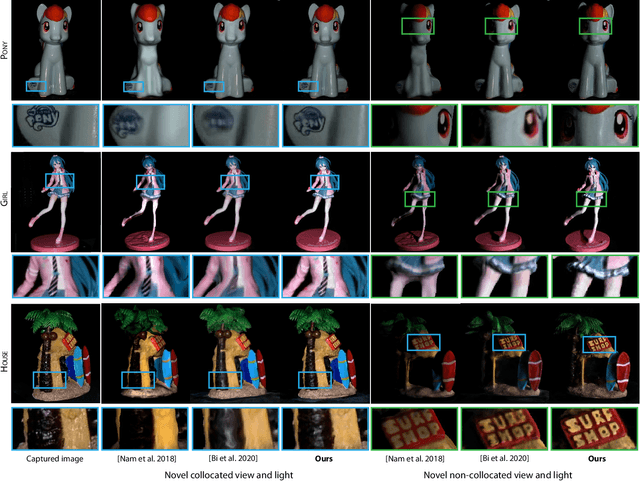
We present Neural Reflectance Fields, a novel deep scene representation that encodes volume density, normal and reflectance properties at any 3D point in a scene using a fully-connected neural network. We combine this representation with a physically-based differentiable ray marching framework that can render images from a neural reflectance field under any viewpoint and light. We demonstrate that neural reflectance fields can be estimated from images captured with a simple collocated camera-light setup, and accurately model the appearance of real-world scenes with complex geometry and reflectance. Once estimated, they can be used to render photo-realistic images under novel viewpoint and (non-collocated) lighting conditions and accurately reproduce challenging effects like specularities, shadows and occlusions. This allows us to perform high-quality view synthesis and relighting that is significantly better than previous methods. We also demonstrate that we can compose the estimated neural reflectance field of a real scene with traditional scene models and render them using standard Monte Carlo rendering engines. Our work thus enables a complete pipeline from high-quality and practical appearance acquisition to 3D scene composition and rendering.
Deep Reflectance Volumes: Relightable Reconstructions from Multi-View Photometric Images
Jul 20, 2020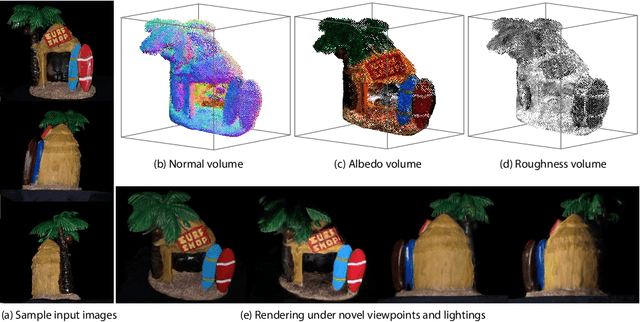
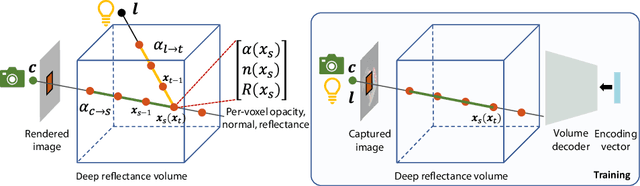

We present a deep learning approach to reconstruct scene appearance from unstructured images captured under collocated point lighting. At the heart of Deep Reflectance Volumes is a novel volumetric scene representation consisting of opacity, surface normal and reflectance voxel grids. We present a novel physically-based differentiable volume ray marching framework to render these scene volumes under arbitrary viewpoint and lighting. This allows us to optimize the scene volumes to minimize the error between their rendered images and the captured images. Our method is able to reconstruct real scenes with challenging non-Lambertian reflectance and complex geometry with occlusions and shadowing. Moreover, it accurately generalizes to novel viewpoints and lighting, including non-collocated lighting, rendering photorealistic images that are significantly better than state-of-the-art mesh-based methods. We also show that our learned reflectance volumes are editable, allowing for modifying the materials of the captured scenes.
Deep 3D Capture: Geometry and Reflectance from Sparse Multi-View Images
Mar 27, 2020
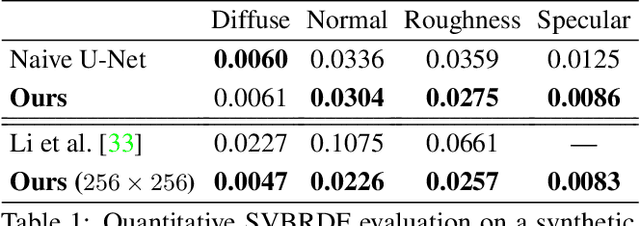

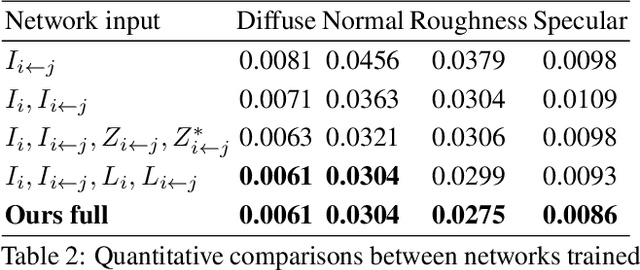
We introduce a novel learning-based method to reconstruct the high-quality geometry and complex, spatially-varying BRDF of an arbitrary object from a sparse set of only six images captured by wide-baseline cameras under collocated point lighting. We first estimate per-view depth maps using a deep multi-view stereo network; these depth maps are used to coarsely align the different views. We propose a novel multi-view reflectance estimation network architecture that is trained to pool features from these coarsely aligned images and predict per-view spatially-varying diffuse albedo, surface normals, specular roughness and specular albedo. We do this by jointly optimizing the latent space of our multi-view reflectance network to minimize the photometric error between images rendered with our predictions and the input images. While previous state-of-the-art methods fail on such sparse acquisition setups, we demonstrate, via extensive experiments on synthetic and real data, that our method produces high-quality reconstructions that can be used to render photorealistic images.
Detecting the Starting Frame of Actions in Video
Jun 07, 2019
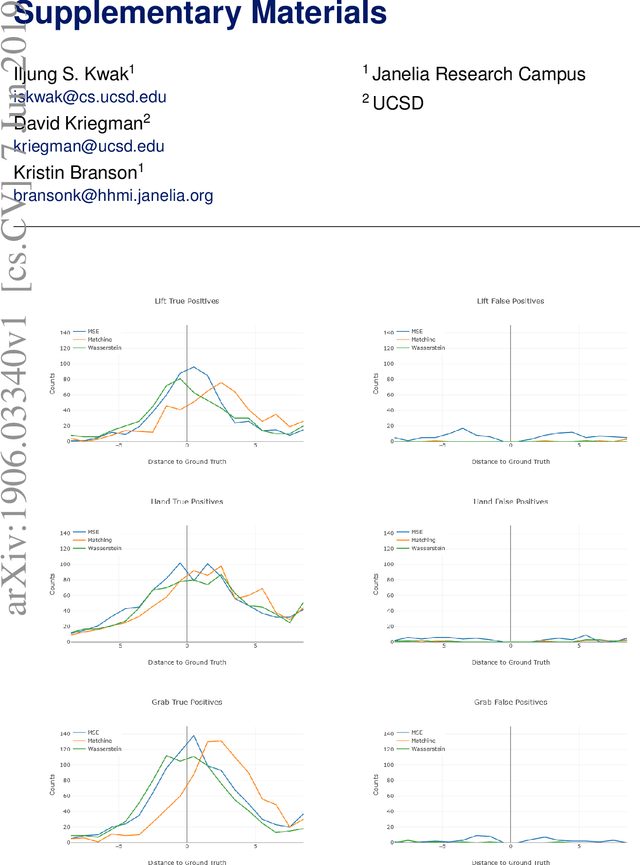
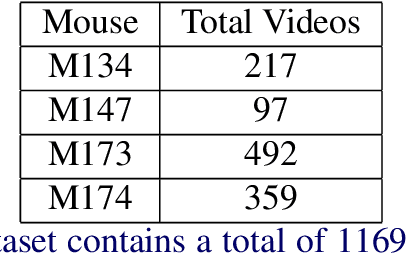
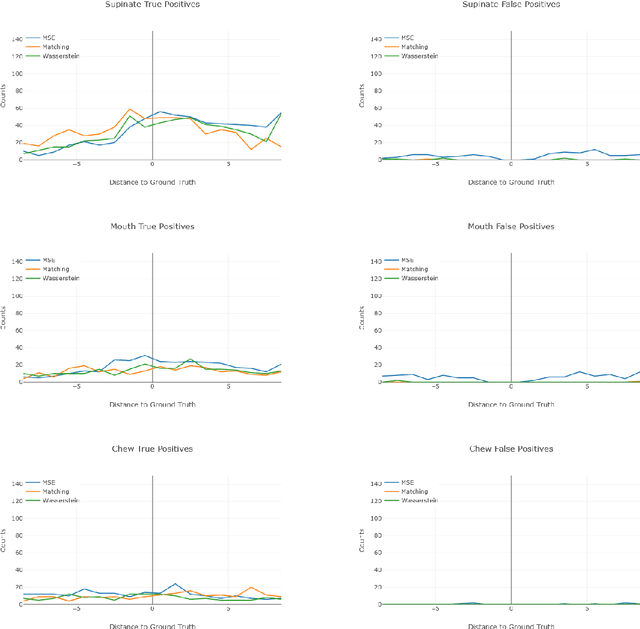
To understand causal relationships between events in the world, it is useful to pinpoint when actions occur in videos and to examine the state of the world at and around that time point. For example, one must accurately detect the start of an audience response -- laughter in a movie, cheering at a sporting event -- to understand the cause of the reaction. In this work, we focus on the problem of accurately detecting action starts rather than isolated events or action ends. We introduce a novel structured loss function based on matching predictions to true action starts that is tailored to this problem; it more heavily penalizes extra and missed action start detections over small misalignments. Recurrent neural networks are used to minimize a differentiable approximation of this loss. To evaluate these methods, we introduce the Mouse Reach Dataset, a large, annotated video dataset of mice performing a sequence of actions. The dataset was labeled by experts for the purpose of neuroscience research on causally relating neural activity to behavior. On this dataset, we demonstrate that the structured loss leads to significantly higher accuracy than a baseline of mean-squared error loss.
Image to Image Translation for Domain Adaptation
Dec 01, 2017

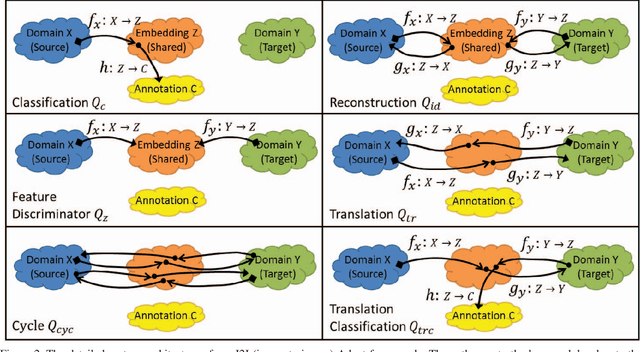
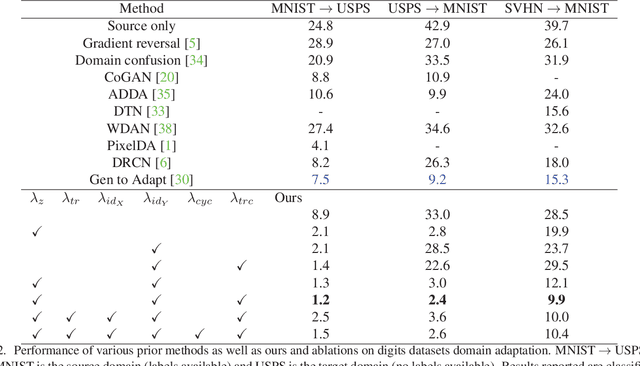
We propose a general framework for unsupervised domain adaptation, which allows deep neural networks trained on a source domain to be tested on a different target domain without requiring any training annotations in the target domain. This is achieved by adding extra networks and losses that help regularize the features extracted by the backbone encoder network. To this end we propose the novel use of the recently proposed unpaired image-toimage translation framework to constrain the features extracted by the encoder network. Specifically, we require that the features extracted are able to reconstruct the images in both domains. In addition we require that the distribution of features extracted from images in the two domains are indistinguishable. Many recent works can be seen as specific cases of our general framework. We apply our method for domain adaptation between MNIST, USPS, and SVHN datasets, and Amazon, Webcam and DSLR Office datasets in classification tasks, and also between GTA5 and Cityscapes datasets for a segmentation task. We demonstrate state of the art performance on each of these datasets.
Dense Volume-to-Volume Vascular Boundary Detection
May 26, 2016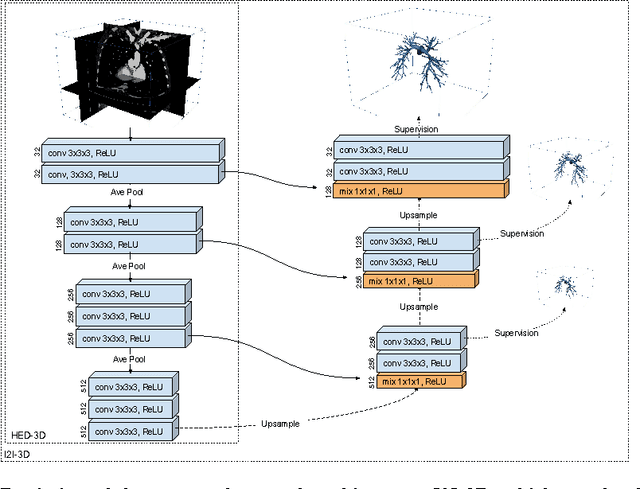

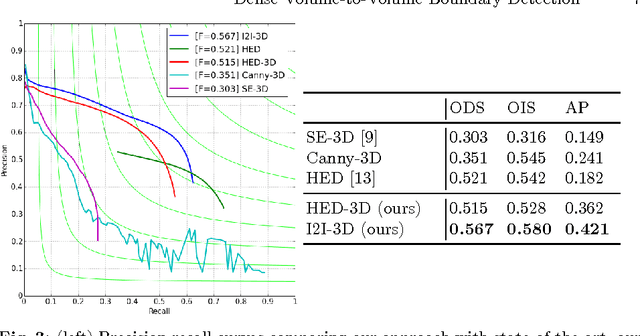
In this work, we present a novel 3D-Convolutional Neural Network (CNN) architecture called I2I-3D that predicts boundary location in volumetric data. Our fine-to-fine, deeply supervised framework addresses three critical issues to 3D boundary detection: (1) efficient, holistic, end-to-end volumetric label training and prediction (2) precise voxel-level prediction to capture fine scale structures prevalent in medical data and (3) directed multi-scale, multi-level feature learning. We evaluate our approach on a dataset consisting of 93 medical image volumes with a wide variety of anatomical regions and vascular structures. In the process, we also introduce HED-3D, a 3D extension of the state-of-the-art 2D edge detector (HED). We show that our deep learning approach out-performs, the current state-of-the-art in 3D vascular boundary detection (structured forests 3D), by a large margin, as well as HED applied to slices, and HED-3D while successfully localizing fine structures. With our approach, boundary detection takes about one minute on a typical 512x512x512 volume.
Learning Concept Embeddings with Combined Human-Machine Expertise
Sep 28, 2015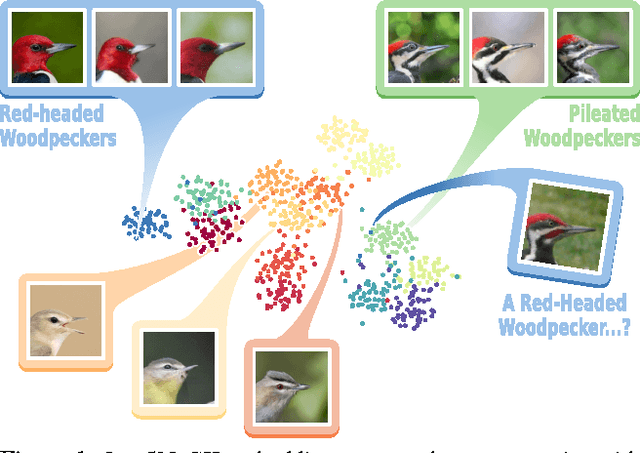
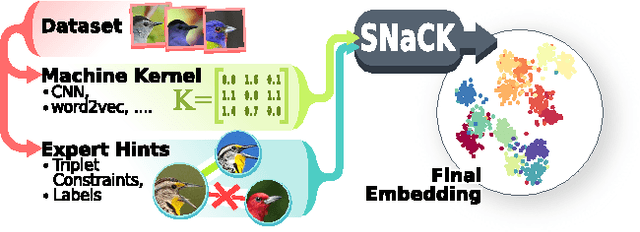
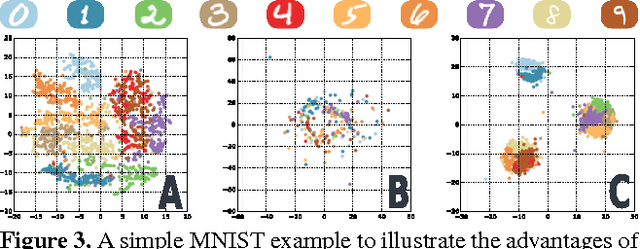

This paper presents our work on "SNaCK," a low-dimensional concept embedding algorithm that combines human expertise with automatic machine similarity kernels. Both parts are complimentary: human insight can capture relationships that are not apparent from the object's visual similarity and the machine can help relieve the human from having to exhaustively specify many constraints. We show that our SNaCK embeddings are useful in several tasks: distinguishing prime and nonprime numbers on MNIST, discovering labeling mistakes in the Caltech UCSD Birds (CUB) dataset with the help of deep-learned features, creating training datasets for bird classifiers, capturing subjective human taste on a new dataset of 10,000 foods, and qualitatively exploring an unstructured set of pictographic characters. Comparisons with the state-of-the-art in these tasks show that SNaCK produces better concept embeddings that require less human supervision than the leading methods.