 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAM! The Behance Artistic Media Dataset for Recognition Beyond Photography
Jul 09, 2017
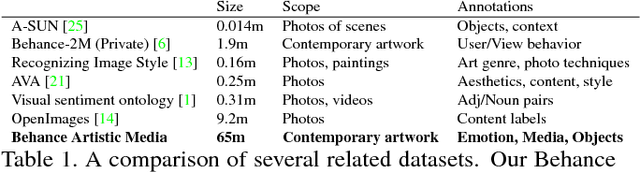

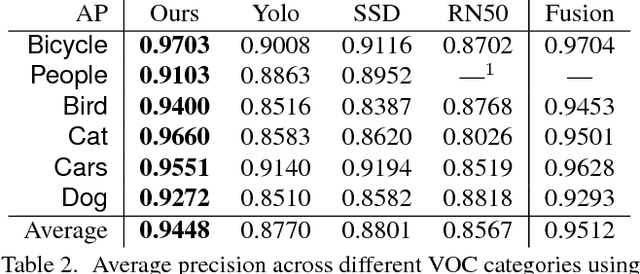
Computer vision systems are designed to work well within the context of everyday photography. However, artists often render the world around them in ways that do not resemble photographs. Artwork produced by people is not constrained to mimic the physical world, making it more challenging for machines to recognize. This work is a step toward teaching machines how to categorize images in ways that are valuable to humans. First, we collect a large-scale dataset of contemporary artwork from Behance, a website containing millions of portfolios from professional and commercial artists. We annotate Behance imagery with rich attribute labels for content, emotions, and artistic media. Furthermore, we carry out baseline experiments to show the value of this dataset for artistic style prediction, for improving the generality of existing object classifiers, and for the study of visual domain adaptation. We believe our Behance Artistic Media dataset will be a good starting point for researchers wishing to study artistic imagery and relevant problems.
Can we still avoid automatic face detection?
Feb 14, 2016

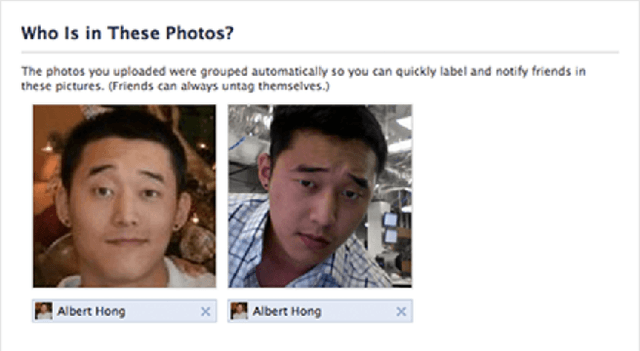

After decades of study, automatic face detection and recognition systems are now accurate and widespread. Naturally, this means users who wish to avoid automatic recognition are becoming less able to do so. Where do we stand in this cat-and-mouse race? We currently live in a society where everyone carries a camera in their pocket. Many people willfully upload most or all of the pictures they take to social networks which invest heavily in automatic face recognition systems. In this setting, is it still possible for privacy-conscientious users to avoid automatic face detection and recognition? If so, how? Must evasion techniques be obvious to be effective, or are there still simple measures that users can use to protect themselves? In this work, we find ways to evade face detection on Facebook, a representative example of a popular social network that uses automatic face detection to enhance their service. We challenge widely-held beliefs about evading face detection: do our old techniques such as blurring the face region or wearing "privacy glasses" still work? We show that in general, state-of-the-art detectors can often find faces even if the subject wears occluding clothing or even if the uploader damages the photo to prevent faces from being detected.
Learning Concept Embeddings with Combined Human-Machine Expertise
Sep 28, 2015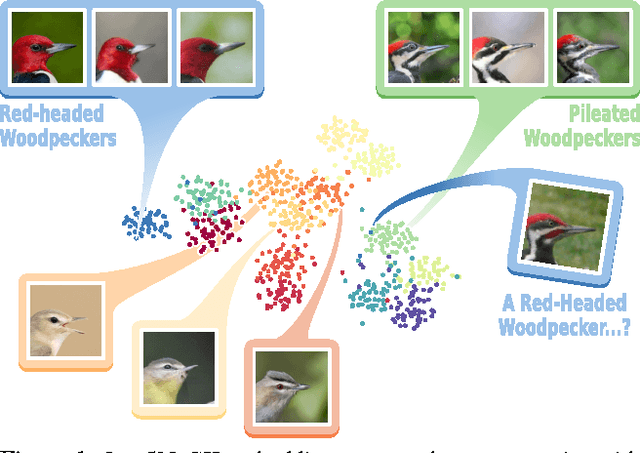
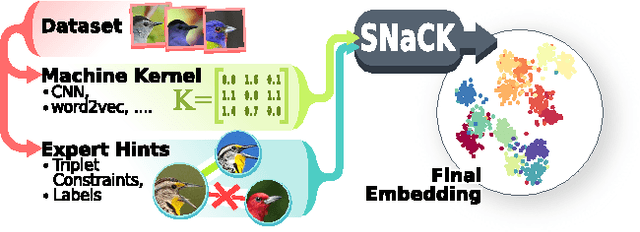
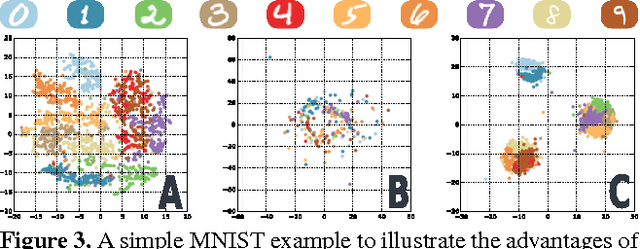

This paper presents our work on "SNaCK," a low-dimensional concept embedding algorithm that combines human expertise with automatic machine similarity kernels. Both parts are complimentary: human insight can capture relationships that are not apparent from the object's visual similarity and the machine can help relieve the human from having to exhaustively specify many constraints. We show that our SNaCK embeddings are useful in several tasks: distinguishing prime and nonprime numbers on MNIST, discovering labeling mistakes in the Caltech UCSD Birds (CUB) dataset with the help of deep-learned features, creating training datasets for bird classifiers, capturing subjective human taste on a new dataset of 10,000 foods, and qualitatively exploring an unstructured set of pictographic characters. Comparisons with the state-of-the-art in these tasks show that SNaCK produces better concept embeddings that require less human supervision than the leading methods.
Image Representations and New Domains in Neural Image Captioning
Aug 09, 2015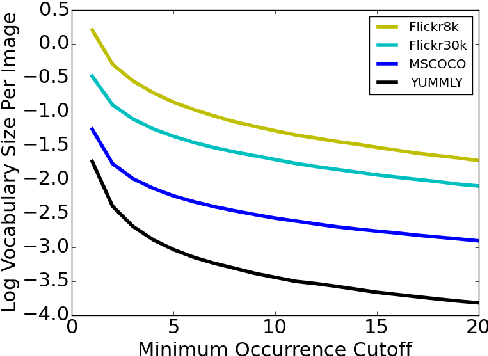
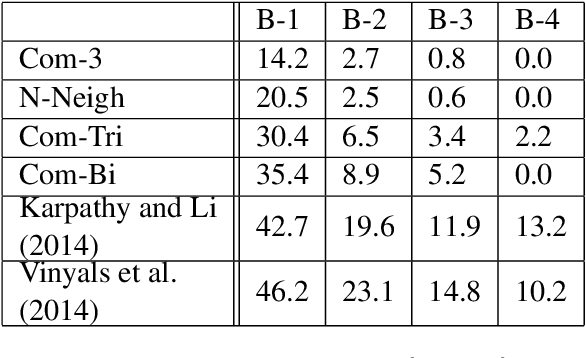

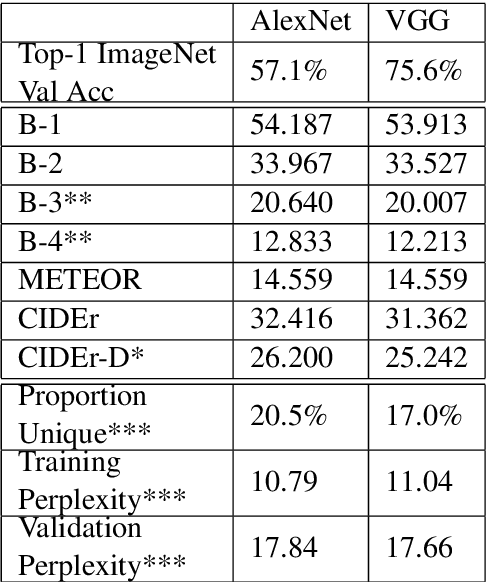
We examine the possibility that recent promising results in automatic caption generation are due primarily to language models. By varying image representation quality produced by a convolutional neural network, we find that a state-of-the-art neural captioning algorithm is able to produce quality captions even when provided with surprisingly poor image representations. We replicate this result in a new, fine-grained, transfer learned captioning domain, consisting of 66K recipe image/title pairs. We also provide some experiments regarding the appropriateness of datasets for automatic captioning, and find that having multiple captions per image is beneficial, but not an absolute requirement.
Cost-Effective HITs for Relative Similarity Comparisons
Apr 12, 2014
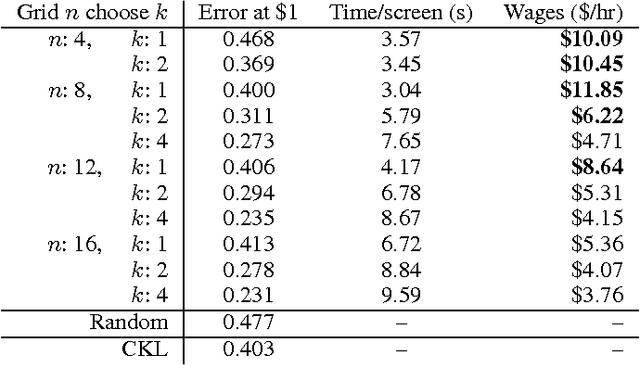
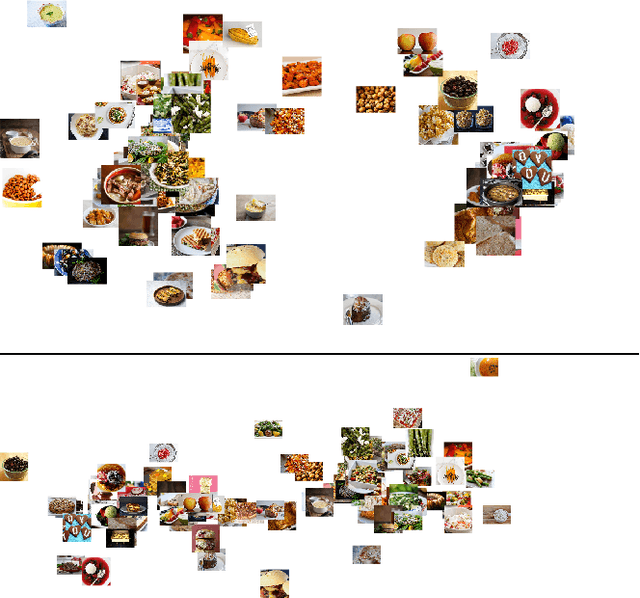
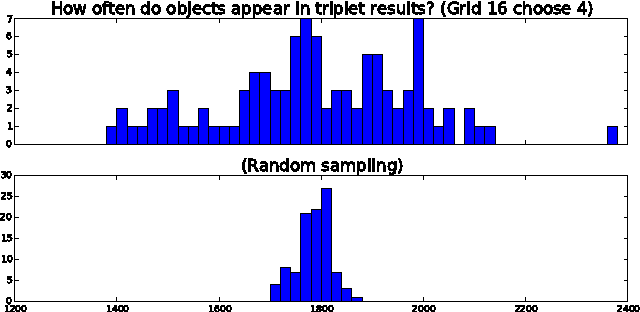
Similarity comparisons of the form "Is object a more similar to b than to c?" are useful for computer vision and machine learning applications. Unfortunately, an embedding of $n$ points is specified by $n^3$ triplets, making collecting every triplet an expensive task. In noticing this difficulty, other researchers have investigated more intelligent triplet sampling techniques, but they do not study their effectiveness or their potential drawbacks. Although it is important to reduce the number of collected triplets, it is also important to understand how best to display a triplet collection task to a user. In this work we explore an alternative display for collecting triplets and analyze the monetary cost and speed of the display. We propose best practices for creating cost effective human intelligence tasks for collecting triplets. We show that rather than changing the sampling algorithm, simple changes to the crowdsourcing UI can lead to much higher quality embeddings. We also provide a dataset as well as the labels collected from crowd workers.
Good Recognition is Non-Metric
Feb 19, 2013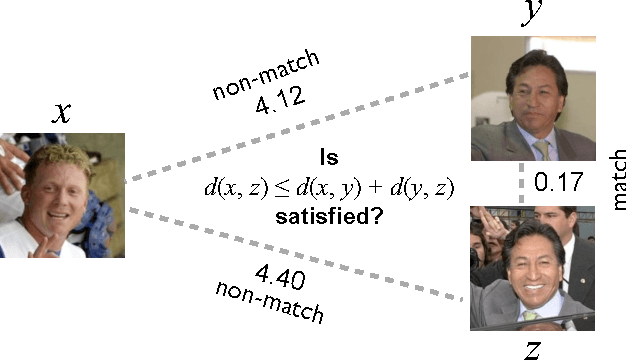

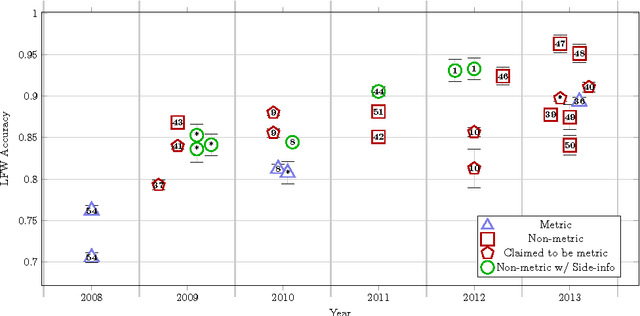
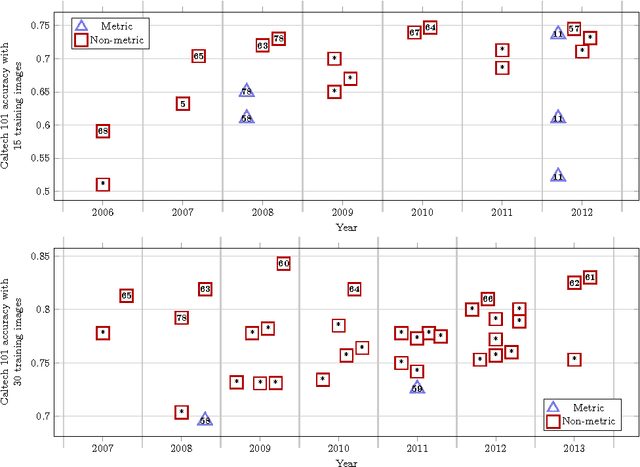
Recognition is the fundamental task of visual cognition, yet how to formalize the general recognition problem for computer vision remains an open issue. The problem is sometimes reduced to the simplest case of recognizing matching pairs, often structured to allow for metric constraints. However, visual recognition is broader than just pair matching -- especially when we consider multi-class training data and large sets of features in a learning context. What we learn and how we learn it has important implications for effective algorithms. In this paper, we reconsider the assumption of recognition as a pair matching test, and introduce a new formal definition that captures the broader context of the problem. Through a meta-analysis and an experimental assessment of the top algorithms on popular data sets, we gain a sense of how often metric properties are violated by good recognition algorithms. By studying these violations, useful insights come to light: we make the case that locally metric algorithms should leverage outside information to solve the general recognition problem.