 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting the Starting Frame of Actions in Video
Jun 07, 2019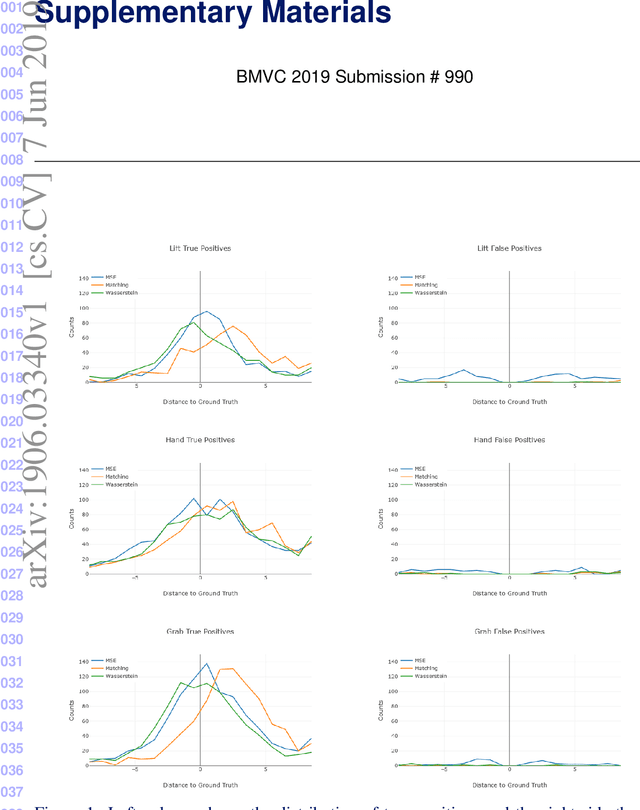
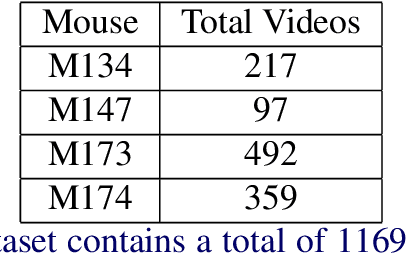
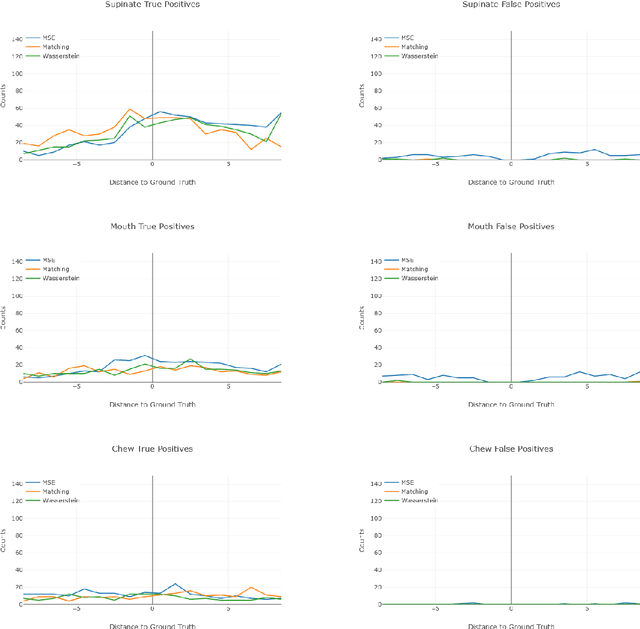
To understand causal relationships between events in the world, it is useful to pinpoint when actions occur in videos and to examine the state of the world at and around that time point. For example, one must accurately detect the start of an audience response -- laughter in a movie, cheering at a sporting event -- to understand the cause of the reaction. In this work, we focus on the problem of accurately detecting action starts rather than isolated events or action ends. We introduce a novel structured loss function based on matching predictions to true action starts that is tailored to this problem; it more heavily penalizes extra and missed action start detections over small misalignments. Recurrent neural networks are used to minimize a differentiable approximation of this loss. To evaluate these methods, we introduce the Mouse Reach Dataset, a large, annotated video dataset of mice performing a sequence of actions. The dataset was labeled by experts for the purpose of neuroscience research on causally relating neural activity to behavior. On this dataset, we demonstrate that the structured loss leads to significantly higher accuracy than a baseline of mean-squared error loss.
Learning Concept Embeddings with Combined Human-Machine Expertise
Sep 28, 2015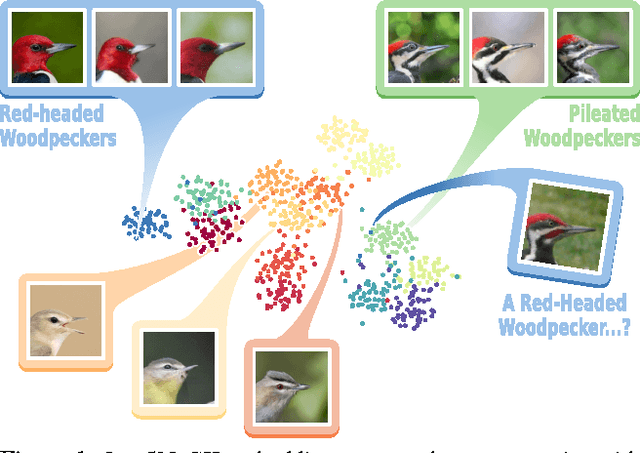
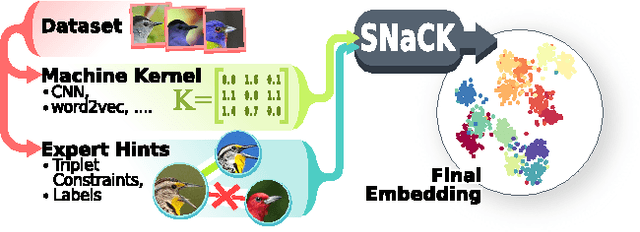
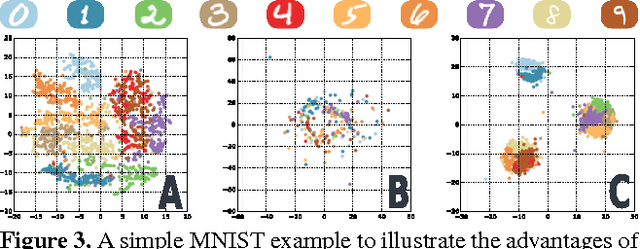

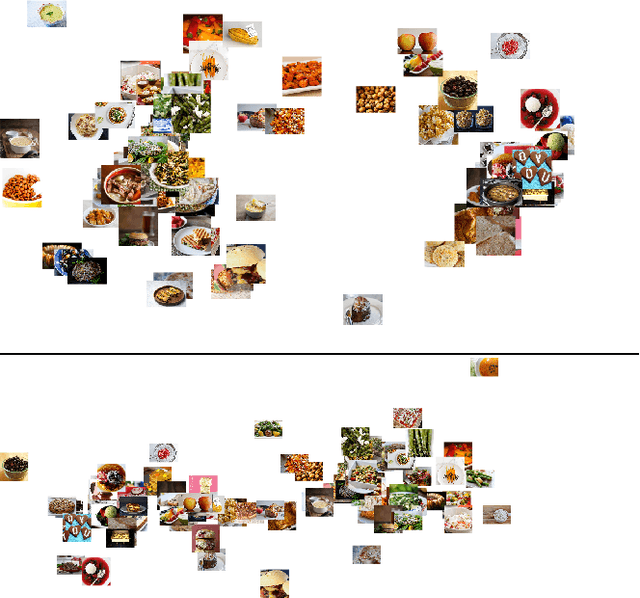
This paper presents our work on "SNaCK," a low-dimensional concept embedding algorithm that combines human expertise with automatic machine similarity kernels. Both parts are complimentary: human insight can capture relationships that are not apparent from the object's visual similarity and the machine can help relieve the human from having to exhaustively specify many constraints. We show that our SNaCK embeddings are useful in several tasks: distinguishing prime and nonprime numbers on MNIST, discovering labeling mistakes in the Caltech UCSD Birds (CUB) dataset with the help of deep-learned features, creating training datasets for bird classifiers, capturing subjective human taste on a new dataset of 10,000 foods, and qualitatively exploring an unstructured set of pictographic characters. Comparisons with the state-of-the-art in these tasks show that SNaCK produces better concept embeddings that require less human supervision than the leading methods.
Cost-Effective HITs for Relative Similarity Comparisons
Apr 12, 2014
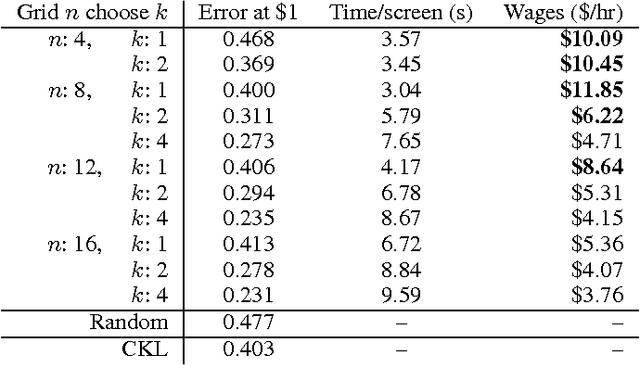
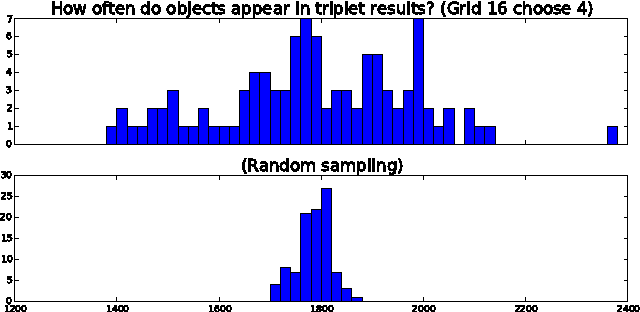
Similarity comparisons of the form "Is object a more similar to b than to c?" are useful for computer vision and machine learning applications. Unfortunately, an embedding of $n$ points is specified by $n^3$ triplets, making collecting every triplet an expensive task. In noticing this difficulty, other researchers have investigated more intelligent triplet sampling techniques, but they do not study their effectiveness or their potential drawbacks. Although it is important to reduce the number of collected triplets, it is also important to understand how best to display a triplet collection task to a user. In this work we explore an alternative display for collecting triplets and analyze the monetary cost and speed of the display. We propose best practices for creating cost effective human intelligence tasks for collecting triplets. We show that rather than changing the sampling algorithm, simple changes to the crowdsourcing UI can lead to much higher quality embeddings. We also provide a dataset as well as the labels collected from crowd workers.