 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA case study of evaluating AI agents on a neuroscience data-to-discovery pipeline
Jun 05, 2026Agentic AI tools offer a promising path to automating software development bottlenecks in scientific research pipelines, particularly for stages that take domain experts days to months to build, where scientists care about correctness and robustness, not implementation details. We present an empirical study of general-purpose coding agents on a fly optogenetics data-to-discovery pipeline. We assess agents on tasks substantially larger than existing benchmarks, datasets orders of magnitude bigger, and evaluation criteria grounded in domain expert standards. We show that agents can solve several individual pipeline stages, suggesting stage-level automation is tractable. By analyzing agents' code iterations, we show that they struggle most when there is not a pre-defined criterion to iterate on, and they must instead use their scientific judgment to assess their current solution, a key open challenge. Mirroring scientific practice, they sometimes attempt visual inspection of intermediate outputs for self-evaluation, but largely fail to interpret what they see or act on it appropriately. Solving the end-to-end pipeline correctly requires stringing together successes across all pipeline stages, and this is beyond agents' current abilities. We identify challenges largely absent from existing benchmarks, including computational resource management and generalization to large held-out data collections. Finally, we distill principles for constructing scientific tasks and rigorous evaluation criteria for open-ended problems.
Neurodata Without Boredom: Benchmarking Agentic AI for Data Reuse
May 14, 2026Neuroscience data are highly fragmented across labs, formats, and experimental paradigms, and reuse often requires substantial manual effort. A persistent roadblock to data reuse and integration is the need to decipher bespoke and diverse data formatting choices. Common data formats have been proposed in response, but the field continues to struggle with a fundamental tension: formats flexible enough to accommodate diverse experiments are rarely descriptive enough to be self-explanatory, and sufficiently descriptive formats demand detailed documentation and curation effort that few labs can sustain. Agentic AI is a natural candidate to solve this problem: LLMs read code and text faster and with sustained attention to the low-level details humans tend to skim over. To measure how well agentic AI performs on this task, we selected eight recent papers studying large-scale mouse neural population recordings that shared both data and code, spanning diverse recording modalities, behavioral paradigms, and dataset formats (e.g., NWB, specialized APIs, and general-purpose Python or MATLAB files). We provided agents with the data, code, and paper, and prompted them to load, understand, and reformat the data for a common downstream task: training a decoder from neural activity to task or behavioral variables. General-purpose coding agents commonly used by scientists performed well on each sub-task, but rarely strung together a fully error-free end-to-end solution. We characterize the types of mistakes agents made and the dataset properties that elicited them, and propose data-sharing best practices for the agentic-AI era. We further find that agents-as-judges are unreliable at catching errors, especially without ground-truth references, so interactive, human-in-the-loop coding remains necessary.
The MABe22 Benchmarks for Representation Learning of Multi-Agent Behavior
Jul 21, 2022
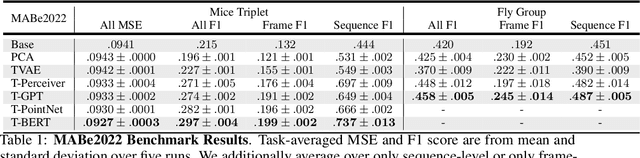
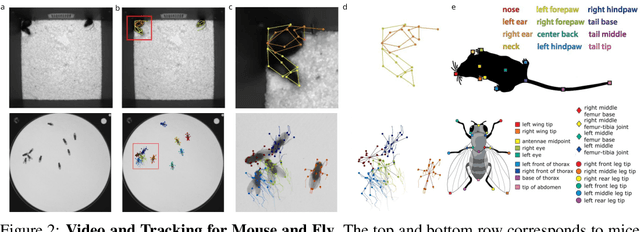
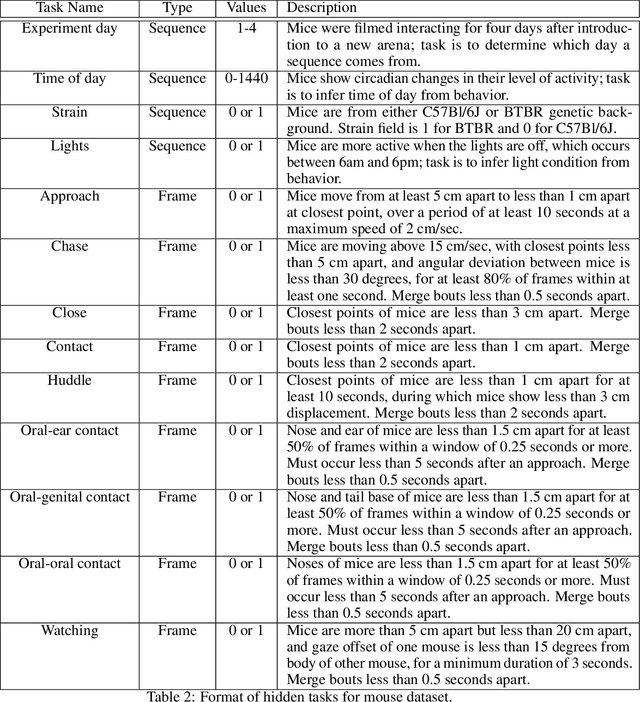
Real-world behavior is often shaped by complex interactions between multiple agents. To scalably study multi-agent behavior, advances in unsupervised and self-supervised learning have enabled a variety of different behavioral representations to be learned from trajectory data. To date, there does not exist a unified set of benchmarks that can enable comparing methods quantitatively and systematically across a broad set of behavior analysis settings. We aim to address this by introducing a large-scale, multi-agent trajectory dataset from real-world behavioral neuroscience experiments that covers a range of behavior analysis tasks. Our dataset consists of trajectory data from common model organisms, with 9.6 million frames of mouse data and 4.4 million frames of fly data, in a variety of experimental settings, such as different strains, lengths of interaction, and optogenetic stimulation. A subset of the frames also consist of expert-annotated behavior labels. Improvements on our dataset corresponds to behavioral representations that work across multiple organisms and is able to capture differences for common behavior analysis tasks.
Evaluation metrics for behaviour modeling
Jul 23, 2020
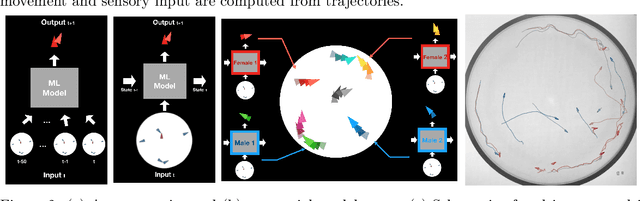
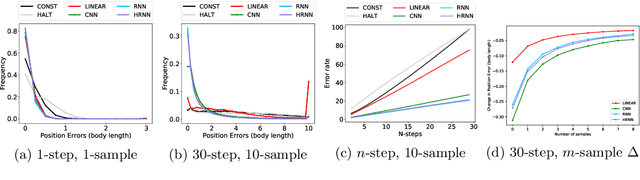

A primary difficulty with unsupervised discovery of structure in large data sets is a lack of quantitative evaluation criteria. In this work, we propose and investigate several metrics for evaluating and comparing generative models of behavior learned using imitation learning. Compared to the commonly-used model log-likelihood, these criteria look at longer temporal relationships in behavior, are relevant if behavior has some properties that are inherently unpredictable, and highlight biases in the overall distribution of behaviors produced by the model. Pointwise metrics compare real to model-predicted trajectories given true past information. Distribution metrics compare statistics of the model simulating behavior in open loop, and are inspired by how experimental biologists evaluate the effects of manipulations on animal behavior. We show that the proposed metrics correspond with biologists' intuitions about behavior, and allow us to evaluate models, understand their biases, and enable us to propose new research directions.
Are skip connections necessary for biologically plausible learning rules?
Dec 04, 2019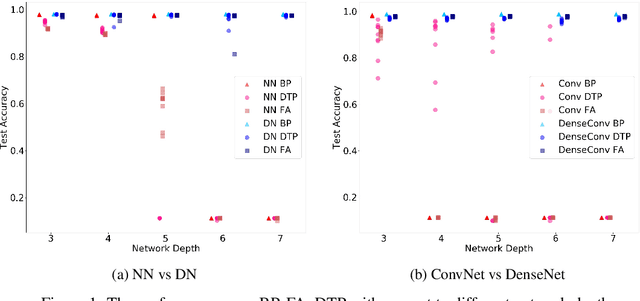
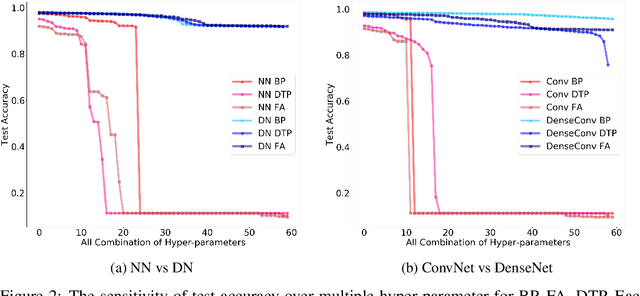
Backpropagation is the workhorse of deep learning, however, several other biologically-motivated learning rules have been introduced, such as random feedback alignment and difference target propagation. None of these methods have produced a competitive performance against backpropagation. In this paper, we show that biologically-motivated learning rules with skip connections between intermediate layers can perform as well as backpropagation on the MNIST dataset and are robust to various sets of hyper-parameters.
Detecting the Starting Frame of Actions in Video
Jun 07, 2019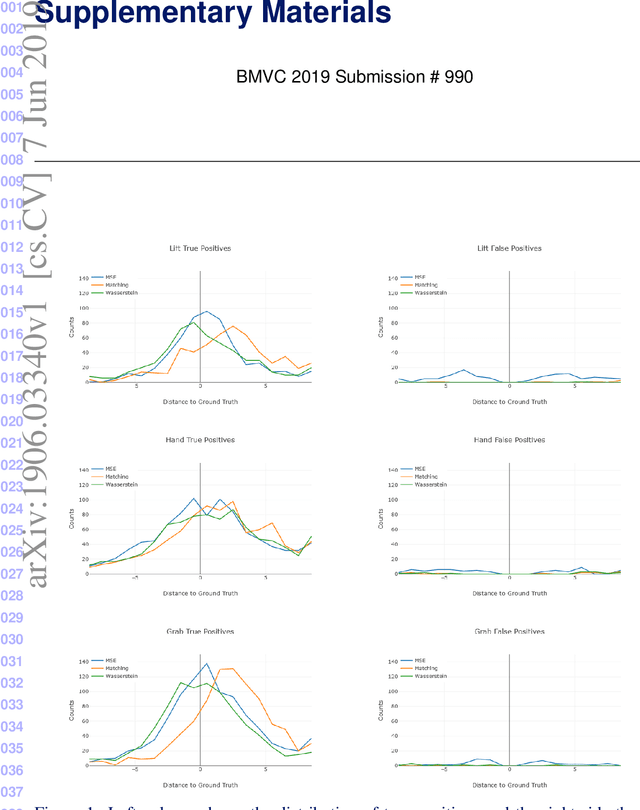
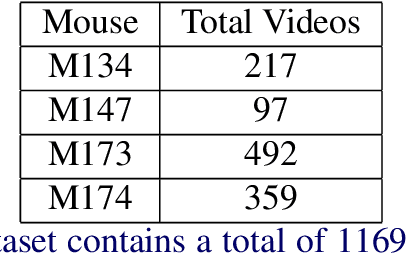
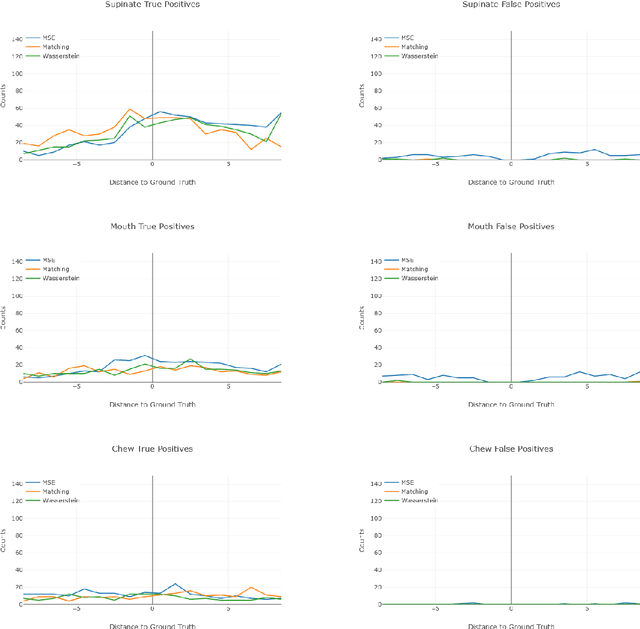
To understand causal relationships between events in the world, it is useful to pinpoint when actions occur in videos and to examine the state of the world at and around that time point. For example, one must accurately detect the start of an audience response -- laughter in a movie, cheering at a sporting event -- to understand the cause of the reaction. In this work, we focus on the problem of accurately detecting action starts rather than isolated events or action ends. We introduce a novel structured loss function based on matching predictions to true action starts that is tailored to this problem; it more heavily penalizes extra and missed action start detections over small misalignments. Recurrent neural networks are used to minimize a differentiable approximation of this loss. To evaluate these methods, we introduce the Mouse Reach Dataset, a large, annotated video dataset of mice performing a sequence of actions. The dataset was labeled by experts for the purpose of neuroscience research on causally relating neural activity to behavior. On this dataset, we demonstrate that the structured loss leads to significantly higher accuracy than a baseline of mean-squared error loss.
Importance Weighted Adversarial Variational Autoencoders for Spike Inference from Calcium Imaging Data
Jun 07, 2019
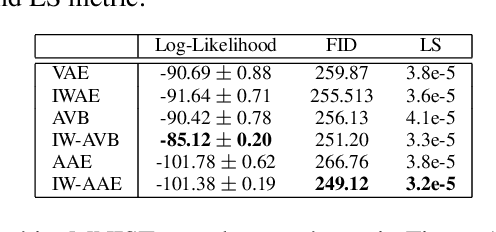
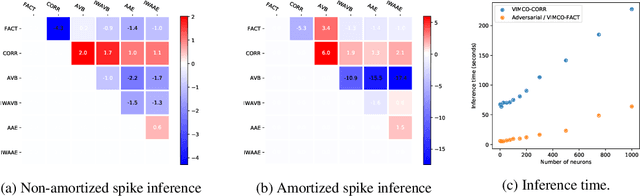
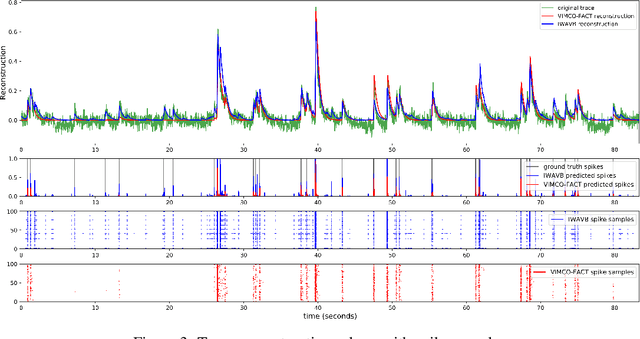
The Importance Weighted Auto Encoder (IWAE) objective has been shown to improve the training of generative models over the standard Variational Auto Encoder (VAE) objective. Here, we derive importance weighted extensions to AVB and AAE. These latent variable models use implicitly defined inference networks whose approximate posterior density q_\phi(z|x) cannot be directly evaluated, an essential ingredient for importance weighting. We show improved training and inference in latent variable models with our adversarially trained importance weighting method, and derive new theoretical connections between adversarial generative model training criteria and marginal likelihood based methods. We apply these methods to the important problem of inferring spiking neural activity from calcium imaging data, a challenging posterior inference problem in neuroscience, and show that posterior samples from the adversarial methods outperform factorized posteriors used in VAEs.
Stochastic Neighbor Embedding under f-divergences
Nov 03, 2018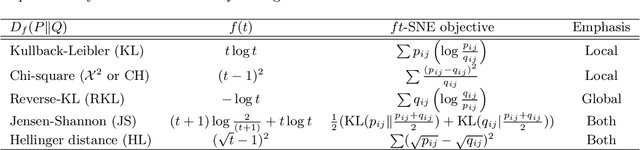
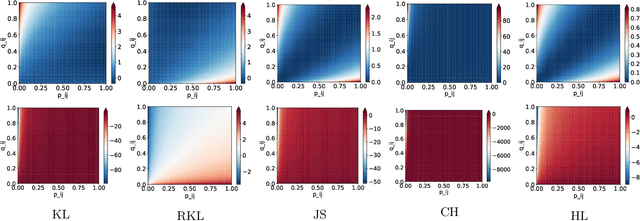
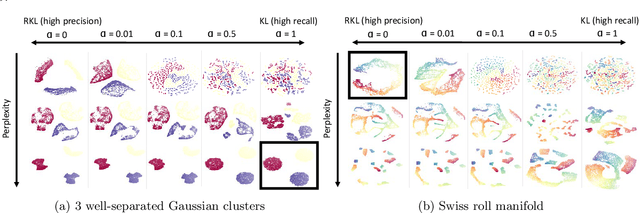
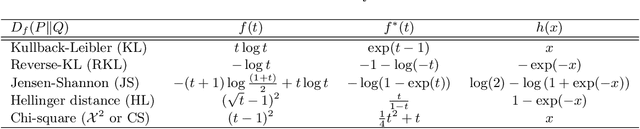
The t-distributed Stochastic Neighbor Embedding (t-SNE) is a powerful and popular method for visualizing high-dimensional data. It minimizes the Kullback-Leibler (KL) divergence between the original and embedded data distributions. In this work, we propose extending this method to other f-divergences. We analytically and empirically evaluate the types of latent structure-manifold, cluster, and hierarchical-that are well-captured using both the original KL-divergence as well as the proposed f-divergence generalization, and find that different divergences perform better for different types of structure. A common concern with $t$-SNE criterion is that it is optimized using gradient descent, and can become stuck in poor local minima. We propose optimizing the f-divergence based loss criteria by minimizing a variational bound. This typically performs better than optimizing the primal form, and our experiments show that it can improve upon the embedding results obtained from the original $t$-SNE criterion as well.
Quantitatively Evaluating GANs With Divergences Proposed for Training
Apr 28, 2018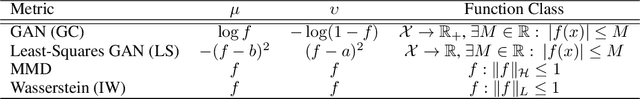
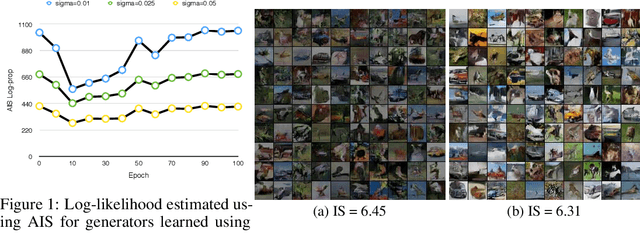
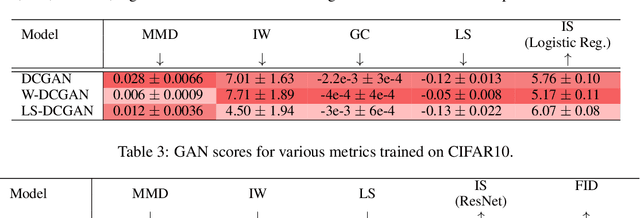

Generative adversarial networks (GANs) have been extremely effective in approximating complex distributions of high-dimensional, input data samples, and substantial progress has been made in understanding and improving GAN performance in terms of both theory and application. However, we currently lack quantitative methods for model assessment. Because of this, while many GAN variants are being proposed, we have relatively little understanding of their relative abilities. In this paper, we evaluate the performance of various types of GANs using divergence and distance functions typically used only for training. We observe consistency across the various proposed metrics and, interestingly, the test-time metrics do not favour networks that use the same training-time criterion. We also compare the proposed metrics to human perceptual scores.
An empirical analysis of the optimization of deep network loss surfaces
Dec 07, 2017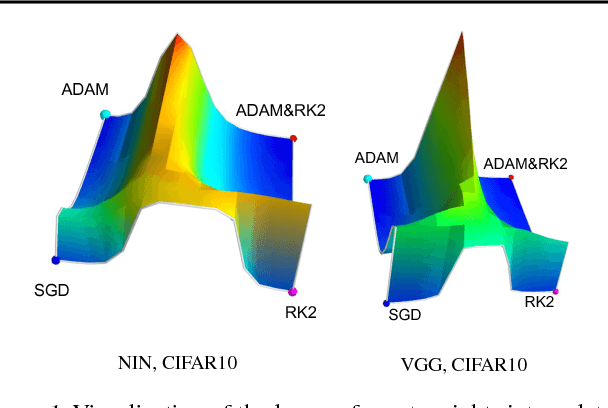
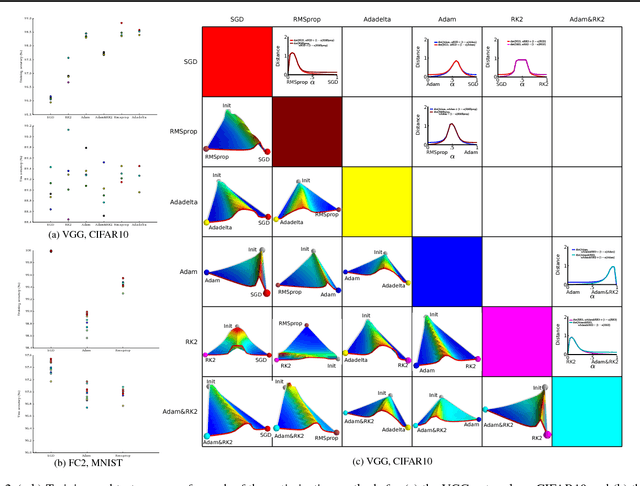
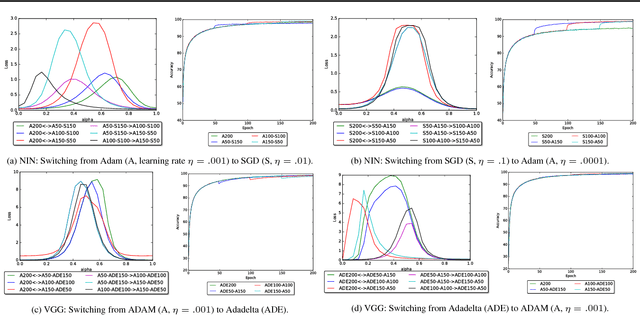
The success of deep neural networks hinges on our ability to accurately and efficiently optimize high-dimensional, non-convex functions. In this paper, we empirically investigate the loss functions of state-of-the-art networks, and how commonly-used stochastic gradient descent variants optimize these loss functions. To do this, we visualize the loss function by projecting them down to low-dimensional spaces chosen based on the convergence points of different optimization algorithms. Our observations suggest that optimization algorithms encounter and choose different descent directions at many saddle points to find different final weights. Based on consistency we observe across re-runs of the same stochastic optimization algorithm, we hypothesize that each optimization algorithm makes characteristic choices at these saddle points.