 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Free Multi-Domain Machine Translation with Stage-wise Training
May 06, 2023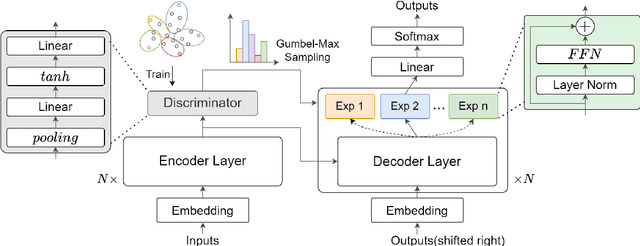
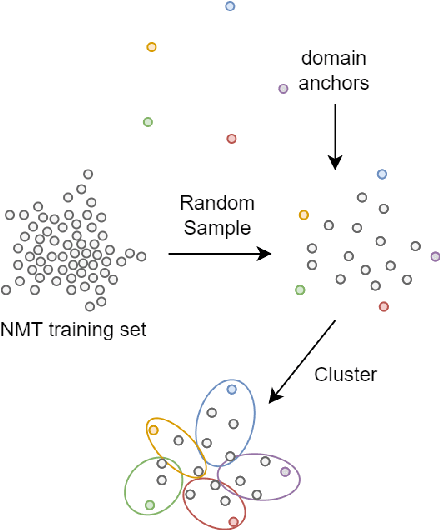
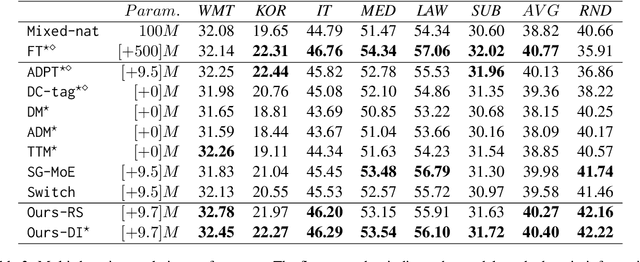
Most multi-domain machine translation models rely on domain-annotated data. Unfortunately, domain labels are usually unavailable in both training processes and real translation scenarios. In this work, we propose a label-free multi-domain machine translation model which requires only a few or no domain-annotated data in training and no domain labels in inference. Our model is composed of three parts: a backbone model, a domain discriminator taking responsibility to discriminate data from different domains, and a set of experts that transfer the decoded features from generic to specific. We design a stage-wise training strategy and train the three parts sequentially. To leverage the extra domain knowledge and improve the training stability, in the discriminator training stage, domain differences are modeled explicitly with clustering and distilled into the discriminator through a multi-classification task. Meanwhile, the Gumbel-Max sampling is adopted as the routing scheme in the expert training stage to achieve the balance of each expert in specialization and generalization. Experimental results on the German-to-English translation task show that our model significantly improves BLEU scores on six different domains and even outperforms most of the models trained with domain-annotated data.
Importance Weighted Adversarial Variational Autoencoders for Spike Inference from Calcium Imaging Data
Jun 07, 2019
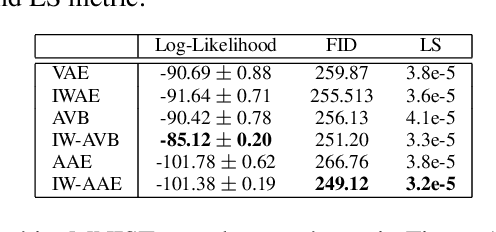
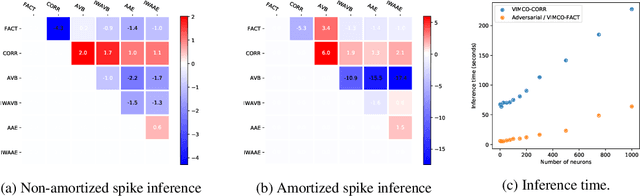
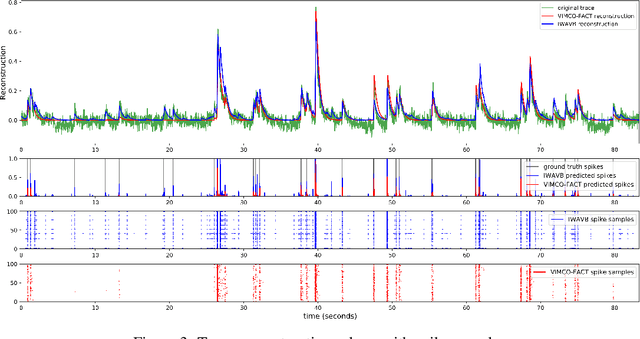
The Importance Weighted Auto Encoder (IWAE) objective has been shown to improve the training of generative models over the standard Variational Auto Encoder (VAE) objective. Here, we derive importance weighted extensions to AVB and AAE. These latent variable models use implicitly defined inference networks whose approximate posterior density q_\phi(z|x) cannot be directly evaluated, an essential ingredient for importance weighting. We show improved training and inference in latent variable models with our adversarially trained importance weighting method, and derive new theoretical connections between adversarial generative model training criteria and marginal likelihood based methods. We apply these methods to the important problem of inferring spiking neural activity from calcium imaging data, a challenging posterior inference problem in neuroscience, and show that posterior samples from the adversarial methods outperform factorized posteriors used in VAEs.
Fast amortized inference of neural activity from calcium imaging data with variational autoencoders
Nov 06, 2017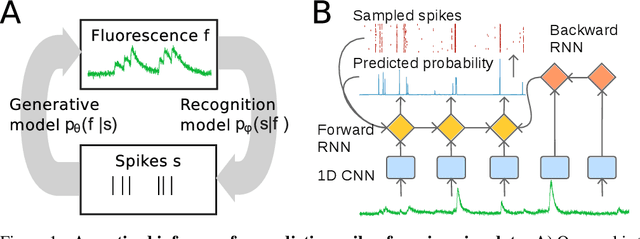
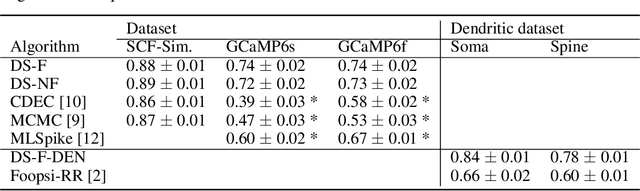
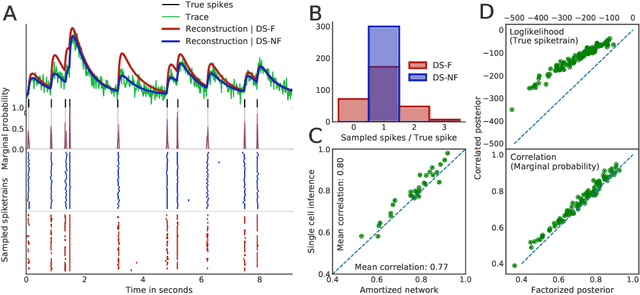
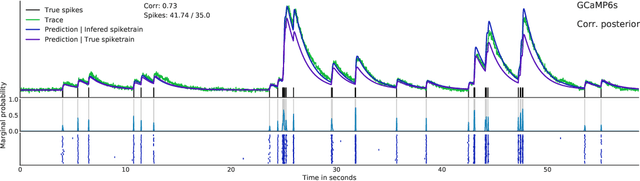
Calcium imaging permits optical measurement of neural activity. Since intracellular calcium concentration is an indirect measurement of neural activity, computational tools are necessary to infer the true underlying spiking activity from fluorescence measurements. Bayesian model inversion can be used to solve this problem, but typically requires either computationally expensive MCMC sampling, or faster but approximate maximum-a-posteriori optimization. Here, we introduce a flexible algorithmic framework for fast, efficient and accurate extraction of neural spikes from imaging data. Using the framework of variational autoencoders, we propose to amortize inference by training a deep neural network to perform model inversion efficiently. The recognition network is trained to produce samples from the posterior distribution over spike trains. Once trained, performing inference amounts to a fast single forward pass through the network, without the need for iterative optimization or sampling. We show that amortization can be applied flexibly to a wide range of nonlinear generative models and significantly improves upon the state of the art in computation time, while achieving competitive accuracy. Our framework is also able to represent posterior distributions over spike-trains. We demonstrate the generality of our method by proposing the first probabilistic approach for separating backpropagating action potentials from putative synaptic inputs in calcium imaging of dendritic spines.