 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2TIMT: Efficient and Effective Modal Adapter for Text Image Machine Translation
May 10, 2023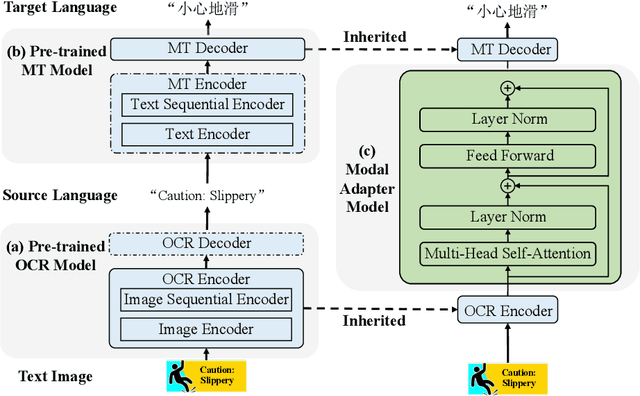
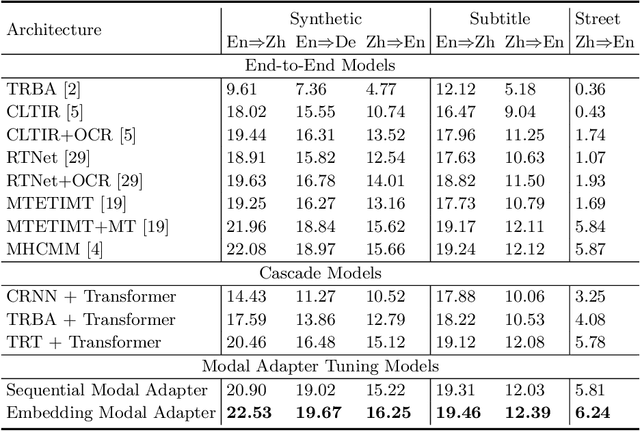
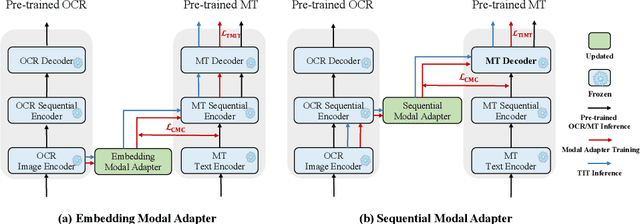
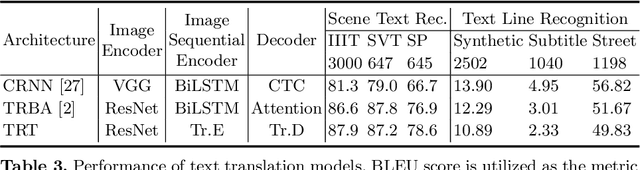
Text image machine translation (TIMT) aims to translate texts embedded in images from one source language to another target language. Existing methods, both two-stage cascade and one-stage end-to-end architectures, suffer from different issues. The cascade models can benefit from the large-scale optical character recognition (OCR) and MT datasets but the two-stage architecture is redundant. The end-to-end models are efficient but suffer from training data deficiency. To this end, in our paper, we propose an end-to-end TIMT model fully making use of the knowledge from existing OCR and MT datasets to pursue both an effective and efficient framework. More specifically, we build a novel modal adapter effectively bridging the OCR encoder and MT decoder. End-to-end TIMT loss and cross-modal contrastive loss are utilized jointly to align the feature distribution of the OCR and MT tasks. Extensive experiments show that the proposed method outperforms the existing two-stage cascade models and one-stage end-to-end models with a lighter and faster architecture. Furthermore, the ablation studies verify the generalization of our method, where the proposed modal adapter is effective to bridge various OCR and MT models.
Multi-Teacher Knowledge Distillation For Text Image Machine Translation
May 10, 2023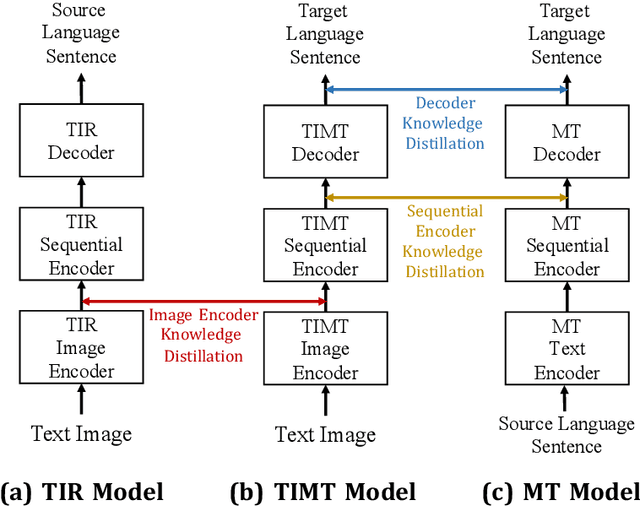



Text image machine translation (TIMT) has been widely used in various real-world applications, which translates source language texts in images into another target language sentence. Existing methods on TIMT are mainly divided into two categories: the recognition-then-translation pipeline model and the end-to-end model. However, how to transfer knowledge from the pipeline model into the end-to-end model remains an unsolved problem. In this paper, we propose a novel Multi-Teacher Knowledge Distillation (MTKD) method to effectively distillate knowledge into the end-to-end TIMT model from the pipeline model. Specifically, three teachers are utilized to improve the performance of the end-to-end TIMT model. The image encoder in the end-to-end TIMT model is optimized with the knowledge distillation guidance from the recognition teacher encoder, while the sequential encoder and decoder are improved by transferring knowledge from the translation sequential and decoder teacher models. Furthermore, both token and sentence-level knowledge distillations are incorporated to better boost the translation performance. Extensive experimental results show that our proposed MTKD effectively improves the text image translation performance and outperforms existing end-to-end and pipeline models with fewer parameters and less decoding time, illustrating that MTKD can take advantage of both pipeline and end-to-end models.
Label-Free Multi-Domain Machine Translation with Stage-wise Training
May 06, 2023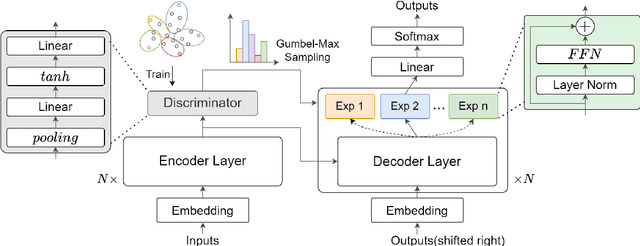
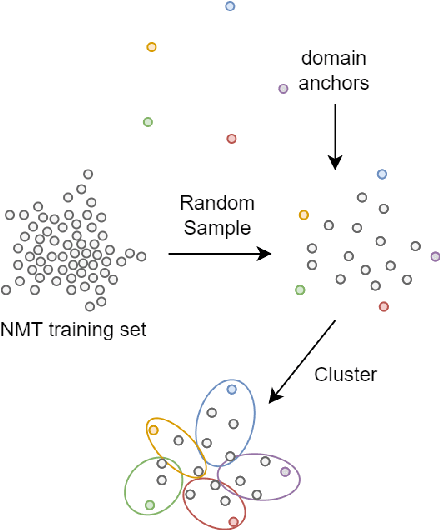
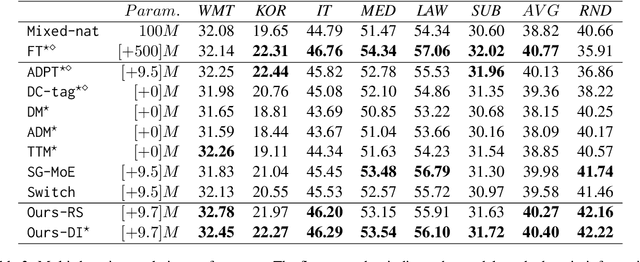
Most multi-domain machine translation models rely on domain-annotated data. Unfortunately, domain labels are usually unavailable in both training processes and real translation scenarios. In this work, we propose a label-free multi-domain machine translation model which requires only a few or no domain-annotated data in training and no domain labels in inference. Our model is composed of three parts: a backbone model, a domain discriminator taking responsibility to discriminate data from different domains, and a set of experts that transfer the decoded features from generic to specific. We design a stage-wise training strategy and train the three parts sequentially. To leverage the extra domain knowledge and improve the training stability, in the discriminator training stage, domain differences are modeled explicitly with clustering and distilled into the discriminator through a multi-classification task. Meanwhile, the Gumbel-Max sampling is adopted as the routing scheme in the expert training stage to achieve the balance of each expert in specialization and generalization. Experimental results on the German-to-English translation task show that our model significantly improves BLEU scores on six different domains and even outperforms most of the models trained with domain-annotated data.
Improving End-to-End Text Image Translation From the Auxiliary Text Translation Task
Oct 08, 2022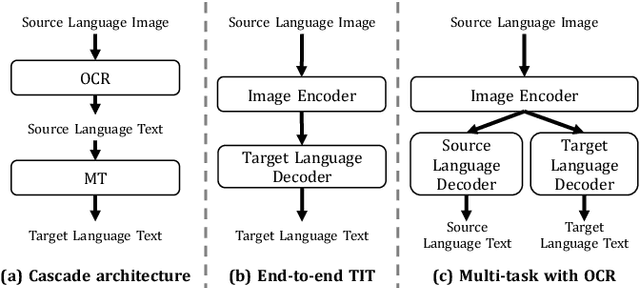

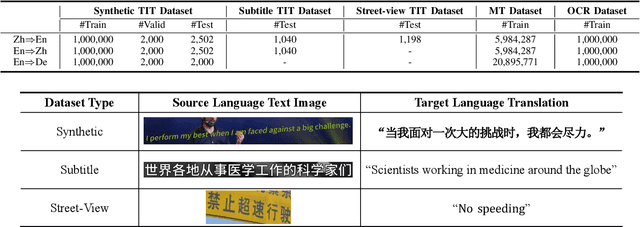
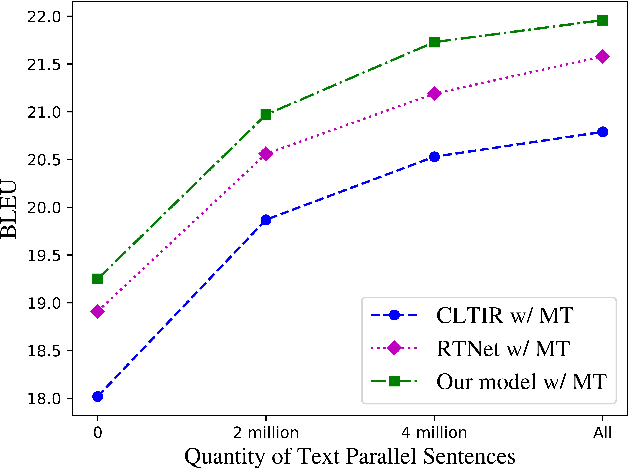
End-to-end text image translation (TIT), which aims at translating the source language embedded in images to the target language, has attracted intensive attention in recent research. However, data sparsity limits the performance of end-to-end text image translation. Multi-task learning is a non-trivial way to alleviate this problem via exploring knowledge from complementary related tasks. In this paper, we propose a novel text translation enhanced text image translation, which trains the end-to-end model with text translation as an auxiliary task. By sharing model parameters and multi-task training, our model is able to take full advantage of easily-available large-scale text parallel corpus. Extensive experimental results show our proposed method outperforms existing end-to-end methods, and the joint multi-task learning with both text translation and recognition tasks achieves better results, proving translation and recognition auxiliary tasks are complementary.
Angular Gap: Reducing the Uncertainty of Image Difficulty through Model Calibration
Jul 18, 2022



Curriculum learning needs example difficulty to proceed from easy to hard. However, the credibility of image difficulty is rarely investigated, which can seriously affect the effectiveness of curricula. In this work, we propose Angular Gap, a measure of difficulty based on the difference in angular distance between feature embeddings and class-weight embeddings built by hyperspherical learning. To ascertain difficulty estimation, we introduce class-wise model calibration, as a post-training technique, to the learnt hyperbolic space. This bridges the gap between probabilistic model calibration and angular distance estimation of hyperspherical learning. We show the superiority of our calibrated Angular Gap over recent difficulty metrics on CIFAR10-H and ImageNetV2. We further propose Angular Gap based curriculum learning for unsupervised domain adaptation that can translate from learning easy samples to mining hard samples. We combine this curriculum with a state-of-the-art self-training method, Cycle Self Training (CST). The proposed Curricular CST learns robust representations and outperforms recent baselines on Office31 and VisDA 2017.