 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2TIMT: Efficient and Effective Modal Adapter for Text Image Machine Translation
Paper and Code
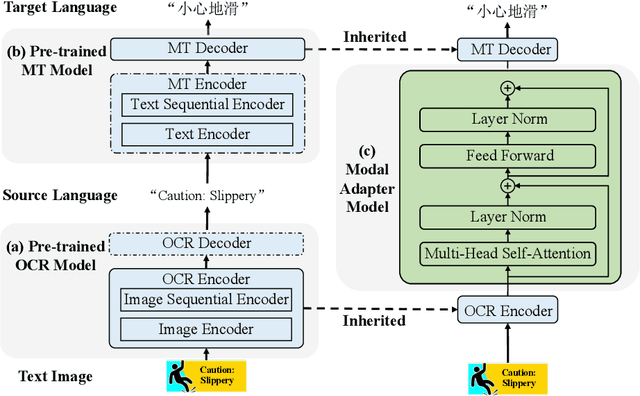
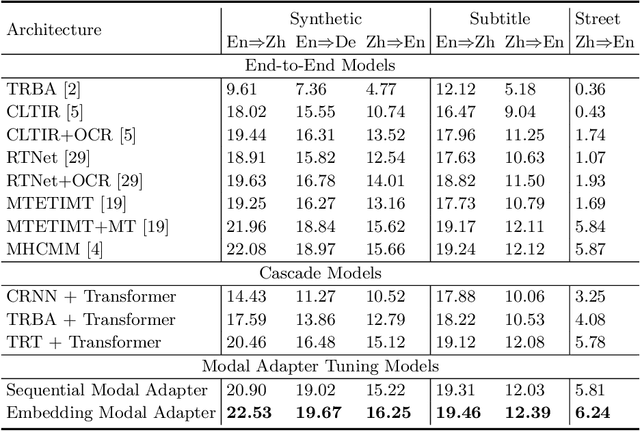
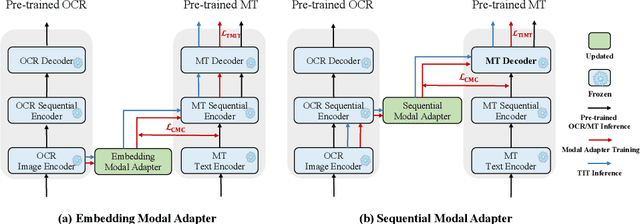
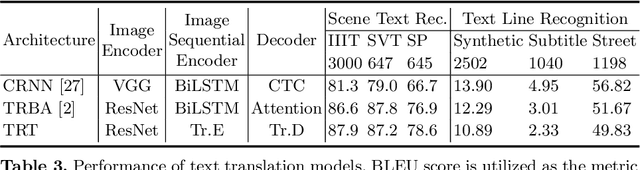
Text image machine translation (TIMT) aims to translate texts embedded in images from one source language to another target language. Existing methods, both two-stage cascade and one-stage end-to-end architectures, suffer from different issues. The cascade models can benefit from the large-scale optical character recognition (OCR) and MT datasets but the two-stage architecture is redundant. The end-to-end models are efficient but suffer from training data deficiency. To this end, in our paper, we propose an end-to-end TIMT model fully making use of the knowledge from existing OCR and MT datasets to pursue both an effective and efficient framework. More specifically, we build a novel modal adapter effectively bridging the OCR encoder and MT decoder. End-to-end TIMT loss and cross-modal contrastive loss are utilized jointly to align the feature distribution of the OCR and MT tasks. Extensive experiments show that the proposed method outperforms the existing two-stage cascade models and one-stage end-to-end models with a lighter and faster architecture. Furthermore, the ablation studies verify the generalization of our method, where the proposed modal adapter is effective to bridge various OCR and MT models.