 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Free Multi-Domain Machine Translation with Stage-wise Training
Paper and Code
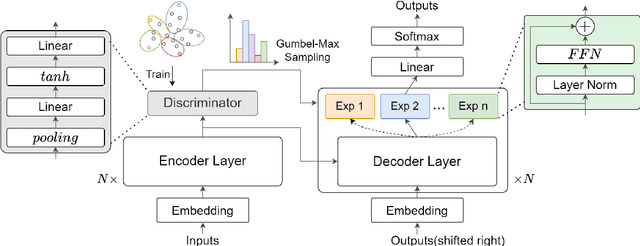
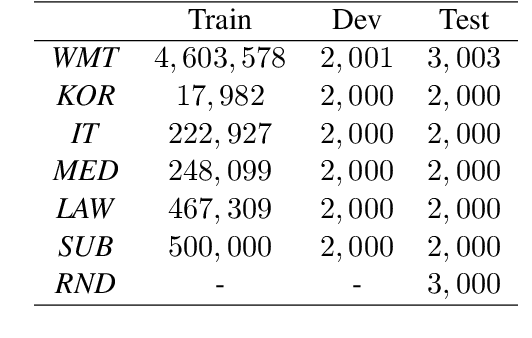
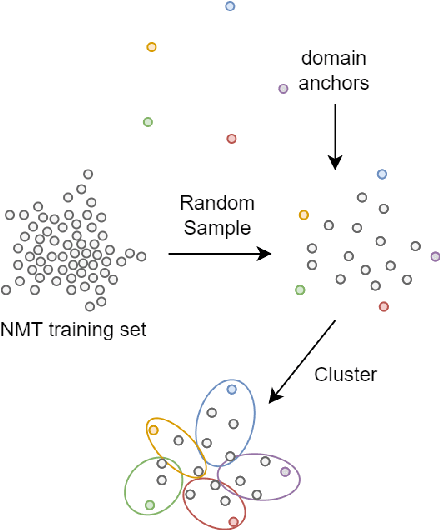
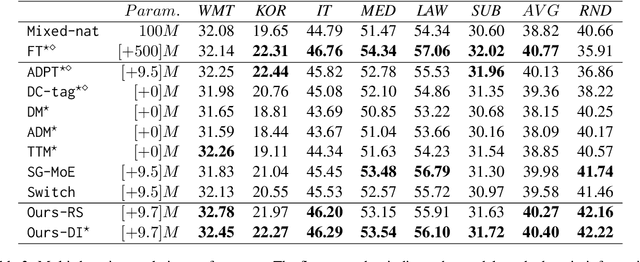
Most multi-domain machine translation models rely on domain-annotated data. Unfortunately, domain labels are usually unavailable in both training processes and real translation scenarios. In this work, we propose a label-free multi-domain machine translation model which requires only a few or no domain-annotated data in training and no domain labels in inference. Our model is composed of three parts: a backbone model, a domain discriminator taking responsibility to discriminate data from different domains, and a set of experts that transfer the decoded features from generic to specific. We design a stage-wise training strategy and train the three parts sequentially. To leverage the extra domain knowledge and improve the training stability, in the discriminator training stage, domain differences are modeled explicitly with clustering and distilled into the discriminator through a multi-classification task. Meanwhile, the Gumbel-Max sampling is adopted as the routing scheme in the expert training stage to achieve the balance of each expert in specialization and generalization. Experimental results on the German-to-English translation task show that our model significantly improves BLEU scores on six different domains and even outperforms most of the models trained with domain-annotated data.