 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrative neurocybernetic modeling in the era of large-scale neuroscience
Apr 26, 2026Large-scale neuroscience is generating rich datasets across animals, brain areas and behavioral contexts, yet our modeling efforts remains fragmented across isolated experiments. We argue that understanding behavior requires integrative neurocybernetic models: understandable dynamical models that capture the closed-loop coupling of brain, body and environment, treat the brain as a controller pursuing latent objectives, represent structured variation across scales, and scale to heterogeneous datasets. Such models shift the goal from predicting neural recordings in isolation to inferring the organizing principles that govern neural and behavioral dynamics. We outline a practical route toward this goal by combining nonlinear state-space models and meta-dynamical extensions with scalable inference, knowledge distillation, mixed open- and closed-loop training, and connectomics-informed architectures. By pooling complementary constraints from recordings, behavior, perturbations and anatomy, integrative neurocybernetic models can provide statistical amplification, few-shot generalization, and mechanistic insight into shared dynamical structure, individual variation, and the control objectives that govern behavior. This agenda offers a model-centric path from fragmented data to a mechanistic science of how brains produce behavior.
Programmable 3D snapshot microscopy with Fourier convolutional networks
Apr 21, 2021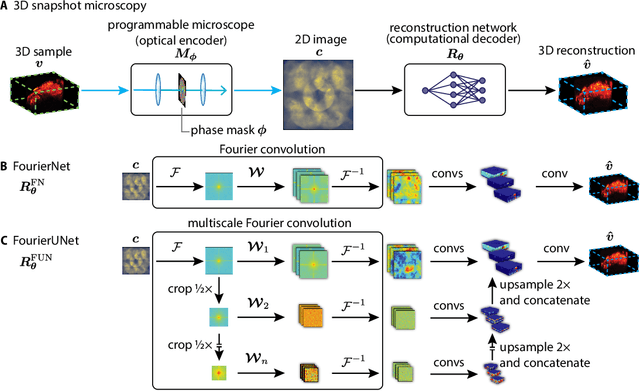


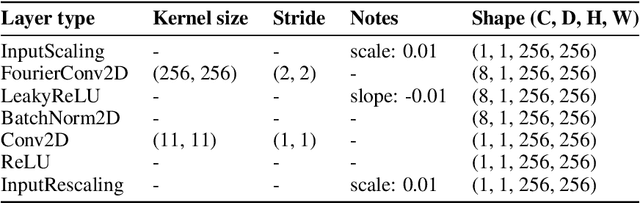
3D snapshot microscopy enables volumetric imaging as fast as a camera allows by capturing a 3D volume in a single 2D camera image, and has found a variety of biological applications such as whole brain imaging of fast neural activity in larval zebrafish. The optimal microscope design for this optical 3D-to-2D encoding to preserve as much 3D information as possible is generally unknown and sample-dependent. Highly-programmable optical elements create new possibilities for sample-specific computational optimization of microscope parameters, e.g. tuning the collection of light for a given sample structure, especially using deep learning. This involves a differentiable simulation of light propagation through the programmable microscope and a neural network to reconstruct volumes from the microscope image. We introduce a class of global kernel Fourier convolutional neural networks which can efficiently integrate the globally mixed information encoded in a 3D snapshot image. We show in silico that our proposed global Fourier convolutional networks succeed in large field-of-view volume reconstruction and microscope parameter optimization where traditional networks fail.
Learning Guided Electron Microscopy with Active Acquisition
Jan 07, 2021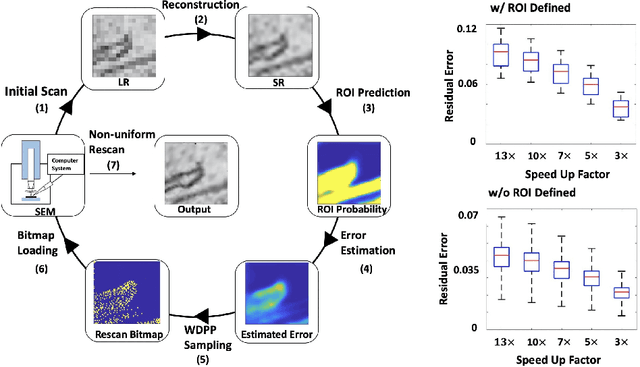
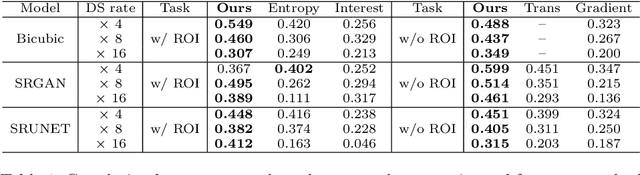
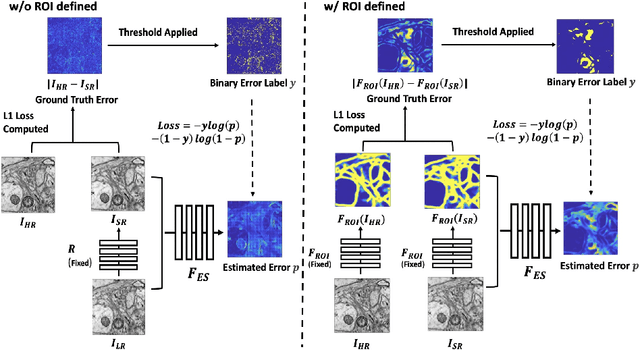
Single-beam scanning electron microscopes (SEM) are widely used to acquire massive data sets for biomedical study, material analysis, and fabrication inspection. Datasets are typically acquired with uniform acquisition: applying the electron beam with the same power and duration to all image pixels, even if there is great variety in the pixels' importance for eventual use. Many SEMs are now able to move the beam to any pixel in the field of view without delay, enabling them, in principle, to invest their time budget more effectively with non-uniform imaging. In this paper, we show how to use deep learning to accelerate and optimize single-beam SEM acquisition of images. Our algorithm rapidly collects an information-lossy image (e.g. low resolution) and then applies a novel learning method to identify a small subset of pixels to be collected at higher resolution based on a trade-off between the saliency and spatial diversity. We demonstrate the efficacy of this novel technique for active acquisition by speeding up the task of collecting connectomic datasets for neurobiology by up to an order of magnitude.
Teaching deep neural networks to localize sources in super-resolution microscopy by combining simulation-based learning and unsupervised learning
Jun 27, 2019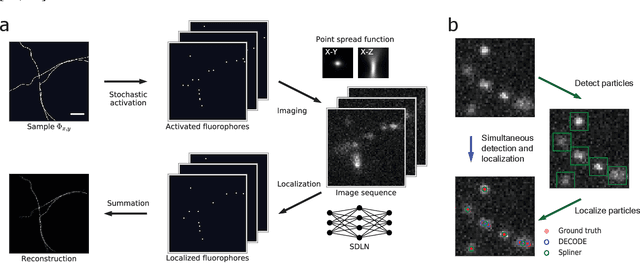
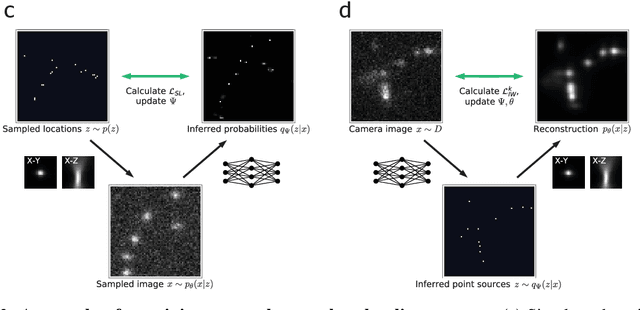

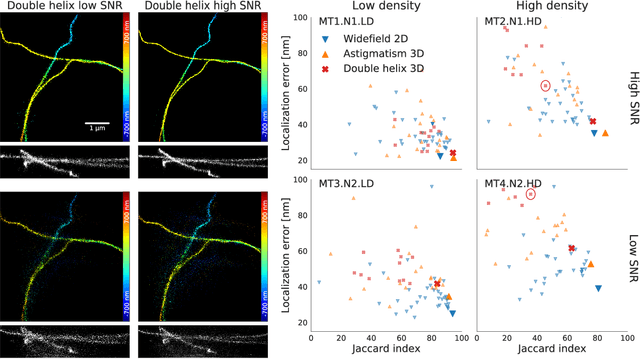
Single-molecule localization microscopy constructs super-resolution images by the sequential imaging and computational localization of sparsely activated fluorophores. Accurate and efficient fluorophore localization algorithms are key to the success of this computational microscopy method. We present a novel localization algorithm based on deep learning which significantly improves upon the state of the art. Our contributions are a novel network architecture for simultaneous detection and localization, and a new training algorithm which enables this deep network to solve the Bayesian inverse problem of detecting and localizing single molecules. Our network architecture uses temporal context from multiple sequentially imaged frames to detect and localize molecules. Our training algorithm combines simulation-based supervised learning with autoencoder-based unsupervised learning to make it more robust against mismatch in the generative model. We demonstrate the performance of our method on datasets imaged using a variety of point spread functions and fluorophore densities. While existing localization algorithms can achieve optimal localization accuracy in data with low fluorophore density, they are confounded by high densities. Our method significantly outperforms the state of the art at high densities and thus, enables faster imaging than previous approaches. Our work also more generally shows how to train deep networks to solve challenging Bayesian inverse problems in biology and physics.
A Connectome Based Hexagonal Lattice Convolutional Network Model of the Drosophila Visual System
Jun 24, 2018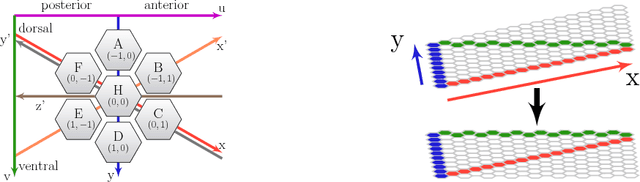
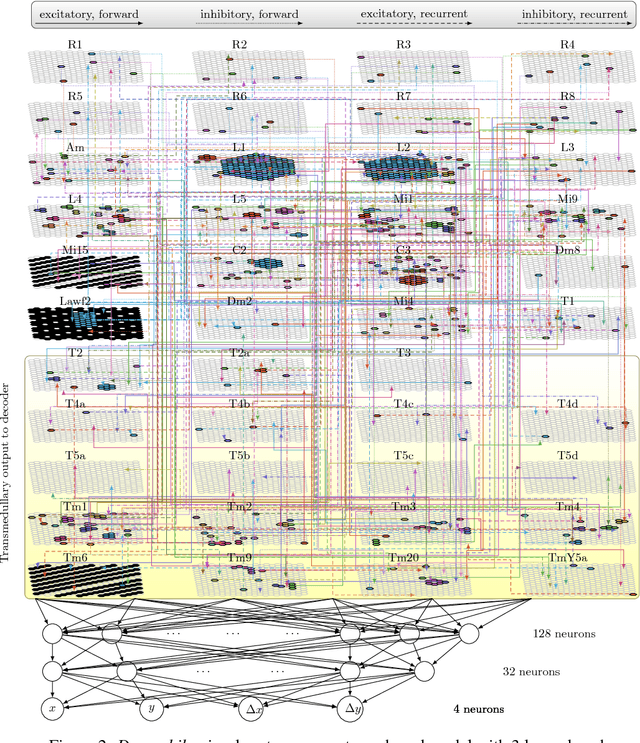
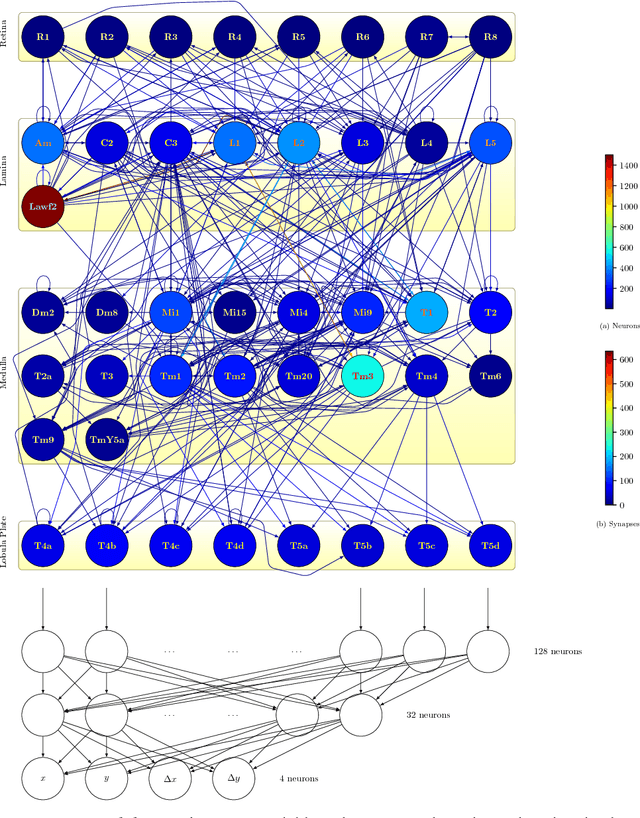
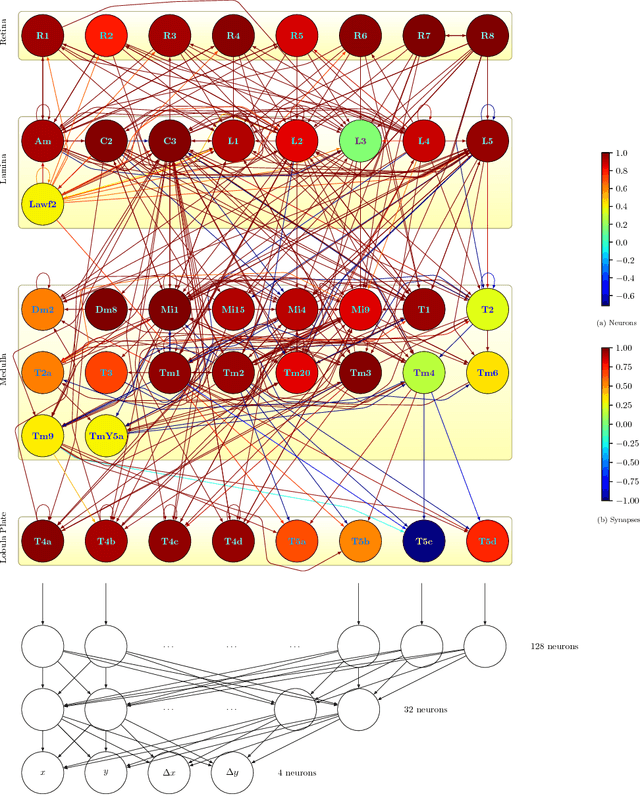
What can we learn from a connectome? We constructed a simplified model of the first two stages of the fly visual system, the lamina and medulla. The resulting hexagonal lattice convolutional network was trained using backpropagation through time to perform object tracking in natural scene videos. Networks initialized with weights from connectome reconstructions automatically discovered well-known orientation and direction selectivity properties in T4 neurons and their inputs, while networks initialized at random did not. Our work is the first demonstration, that knowledge of the connectome can enable in silico predictions of the functional properties of individual neurons in a circuit, leading to an understanding of circuit function from structure alone.
Discrete flow posteriors for variational inference in discrete dynamical systems
May 28, 2018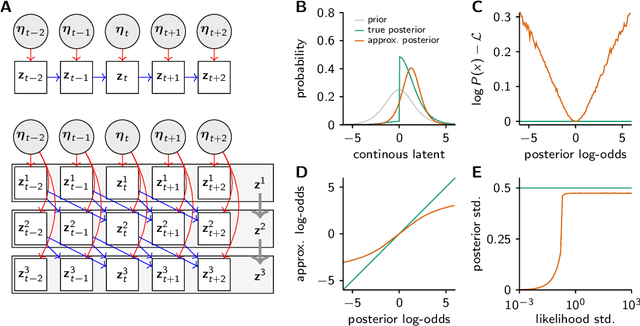
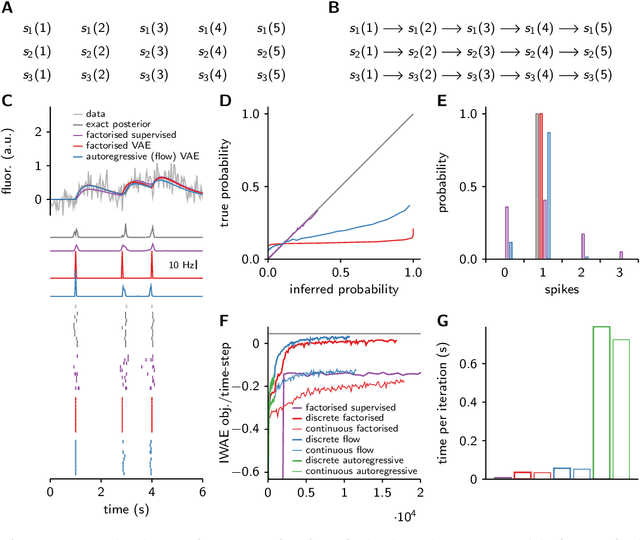
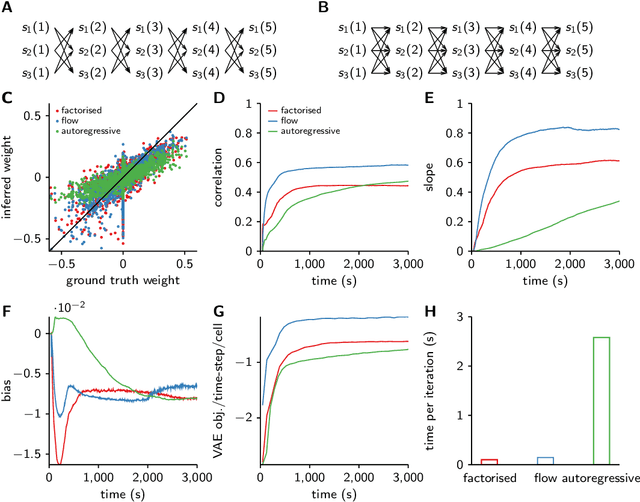
Each training step for a variational autoencoder (VAE) requires us to sample from the approximate posterior, so we usually choose simple (e.g. factorised) approximate posteriors in which sampling is an efficient computation that fully exploits GPU parallelism. However, such simple approximate posteriors are often insufficient, as they eliminate statistical dependencies in the posterior. While it is possible to use normalizing flow approximate posteriors for continuous latents, some problems have discrete latents and strong statistical dependencies. The most natural approach to model these dependencies is an autoregressive distribution, but sampling from such distributions is inherently sequential and thus slow. We develop a fast, parallel sampling procedure for autoregressive distributions based on fixed-point iterations which enables efficient and accurate variational inference in discrete state-space latent variable dynamical systems. To optimize the variational bound, we considered two ways to evaluate probabilities: inserting the relaxed samples directly into the pmf for the discrete distribution, or converting to continuous logistic latent variables and interpreting the K-step fixed-point iterations as a normalizing flow. We found that converting to continuous latent variables gave considerable additional scope for mismatch between the true and approximate posteriors, which resulted in biased inferences, we thus used the former approach. Using our fast sampling procedure, we were able to realize the benefits of correlated posteriors, including accurate uncertainty estimates for one cell, and accurate connectivity estimates for multiple cells, in an order of magnitude less time.
Extracting low-dimensional dynamics from multiple large-scale neural population recordings by learning to predict correlations
Nov 06, 2017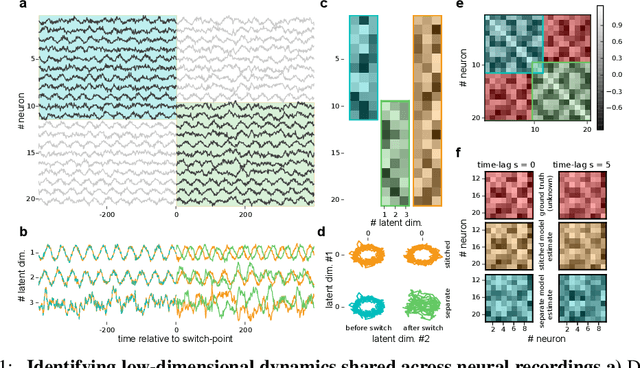
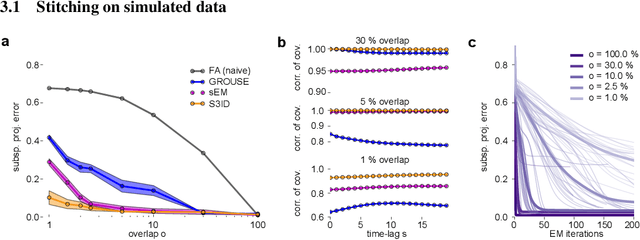
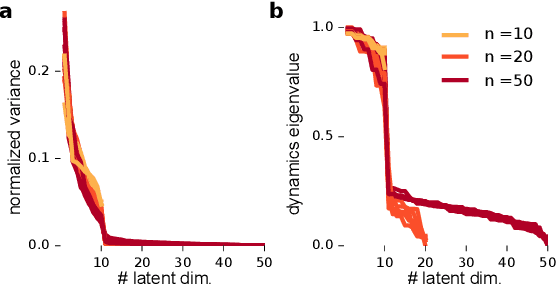
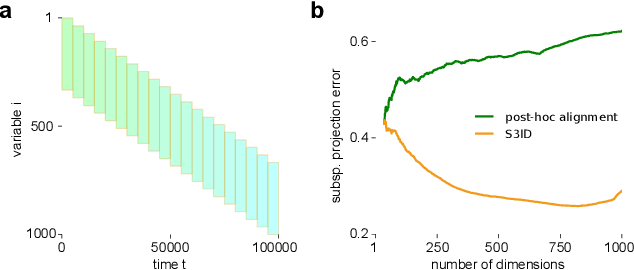
A powerful approach for understanding neural population dynamics is to extract low-dimensional trajectories from population recordings using dimensionality reduction methods. Current approaches for dimensionality reduction on neural data are limited to single population recordings, and can not identify dynamics embedded across multiple measurements. We propose an approach for extracting low-dimensional dynamics from multiple, sequential recordings. Our algorithm scales to data comprising millions of observed dimensions, making it possible to access dynamics distributed across large populations or multiple brain areas. Building on subspace-identification approaches for dynamical systems, we perform parameter estimation by minimizing a moment-matching objective using a scalable stochastic gradient descent algorithm: The model is optimized to predict temporal covariations across neurons and across time. We show how this approach naturally handles missing data and multiple partial recordings, and can identify dynamics and predict correlations even in the presence of severe subsampling and small overlap between recordings. We demonstrate the effectiveness of the approach both on simulated data and a whole-brain larval zebrafish imaging dataset.
Fast amortized inference of neural activity from calcium imaging data with variational autoencoders
Nov 06, 2017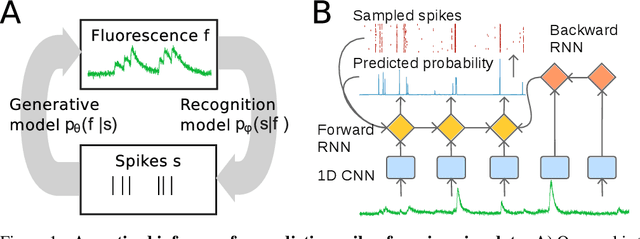
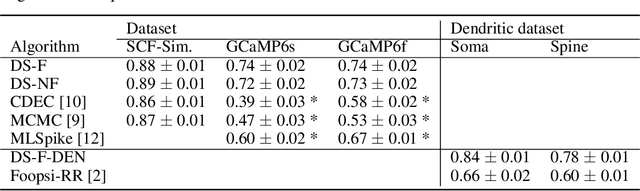
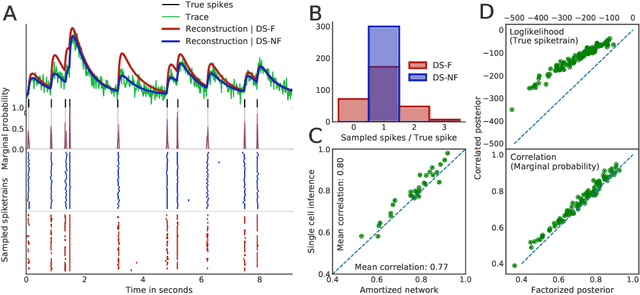
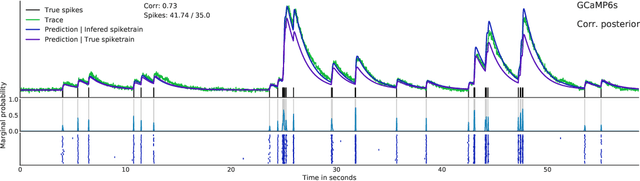
Calcium imaging permits optical measurement of neural activity. Since intracellular calcium concentration is an indirect measurement of neural activity, computational tools are necessary to infer the true underlying spiking activity from fluorescence measurements. Bayesian model inversion can be used to solve this problem, but typically requires either computationally expensive MCMC sampling, or faster but approximate maximum-a-posteriori optimization. Here, we introduce a flexible algorithmic framework for fast, efficient and accurate extraction of neural spikes from imaging data. Using the framework of variational autoencoders, we propose to amortize inference by training a deep neural network to perform model inversion efficiently. The recognition network is trained to produce samples from the posterior distribution over spike trains. Once trained, performing inference amounts to a fast single forward pass through the network, without the need for iterative optimization or sampling. We show that amortization can be applied flexibly to a wide range of nonlinear generative models and significantly improves upon the state of the art in computation time, while achieving competitive accuracy. Our framework is also able to represent posterior distributions over spike-trains. We demonstrate the generality of our method by proposing the first probabilistic approach for separating backpropagating action potentials from putative synaptic inputs in calcium imaging of dendritic spines.
A Deep Structured Learning Approach Towards Automating Connectome Reconstruction from 3D Electron Micrographs
Sep 24, 2017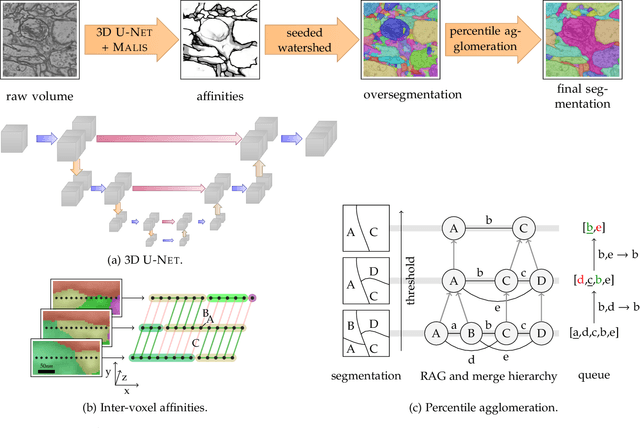


We present a deep structured learning method for neuron segmentation from 3D electron microscopy (EM) which improves significantly upon the state of the art in terms of accuracy and scalability. Our method consists of a 3D U-Net classifier predicting affinity graphs on voxels, followed by iterative region agglomeration. We train the U-Net using a new structured loss based on MALIS that encourages topological correctness. Our extension consists of two parts: First, an $O(n\log(n))$ method to compute the loss gradient, improving over the originally proposed $O(n^2)$ algorithm. Second, we compute the gradient in two separate passes to avoid spurious contributions in early training stages. Our affinity predictions are accurate enough that simple agglomeration outperforms more involved methods used earlier on inferior predictions. We present results on three datasets (CREMI, FIB, and SegEM) of different imaging techniques and animals and achieve improvements over previous results of 27%, 15%, and 250%. Our findings suggest that a single 3D segmentation strategy can be applied to both isotropic and anisotropic EM data. The runtime of our method scales with $O(n)$ in the size of the volume and achieves a throughput of about 2.6 seconds per megavoxel, allowing processing of very large datasets.
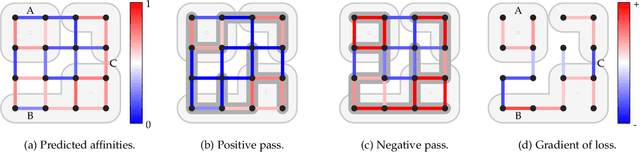
Maximin affinity learning of image segmentation
Nov 28, 2009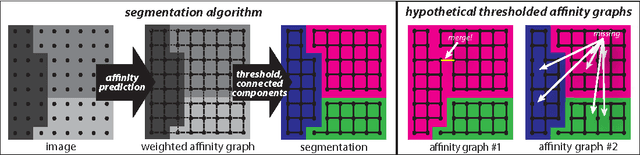
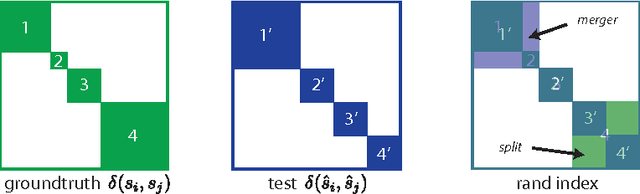
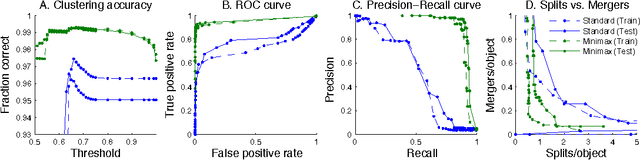

Images can be segmented by first using a classifier to predict an affinity graph that reflects the degree to which image pixels must be grouped together and then partitioning the graph to yield a segmentation. Machine learning has been applied to the affinity classifier to produce affinity graphs that are good in the sense of minimizing edge misclassification rates. However, this error measure is only indirectly related to the quality of segmentations produced by ultimately partitioning the affinity graph. We present the first machine learning algorithm for training a classifier to produce affinity graphs that are good in the sense of producing segmentations that directly minimize the Rand index, a well known segmentation performance measure. The Rand index measures segmentation performance by quantifying the classification of the connectivity of image pixel pairs after segmentation. By using the simple graph partitioning algorithm of finding the connected components of the thresholded affinity graph, we are able to train an affinity classifier to directly minimize the Rand index of segmentations resulting from the graph partitioning. Our learning algorithm corresponds to the learning of maximin affinities between image pixel pairs, which are predictive of the pixel-pair connectivity.