 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation metrics for behaviour modeling
Jul 23, 2020
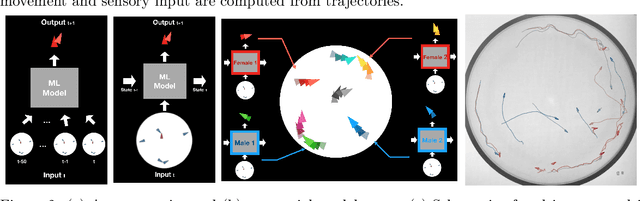
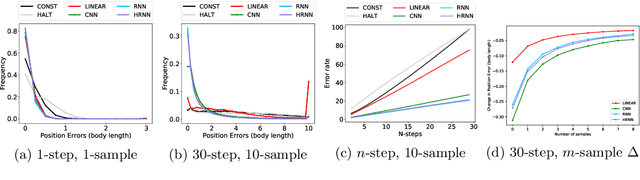

A primary difficulty with unsupervised discovery of structure in large data sets is a lack of quantitative evaluation criteria. In this work, we propose and investigate several metrics for evaluating and comparing generative models of behavior learned using imitation learning. Compared to the commonly-used model log-likelihood, these criteria look at longer temporal relationships in behavior, are relevant if behavior has some properties that are inherently unpredictable, and highlight biases in the overall distribution of behaviors produced by the model. Pointwise metrics compare real to model-predicted trajectories given true past information. Distribution metrics compare statistics of the model simulating behavior in open loop, and are inspired by how experimental biologists evaluate the effects of manipulations on animal behavior. We show that the proposed metrics correspond with biologists' intuitions about behavior, and allow us to evaluate models, understand their biases, and enable us to propose new research directions.