 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Vote Veto: A Self-Training Strategy for Low-Shot Learning of a Task-Invariant Embedding to Diagnose Glaucoma
Jan 19, 2021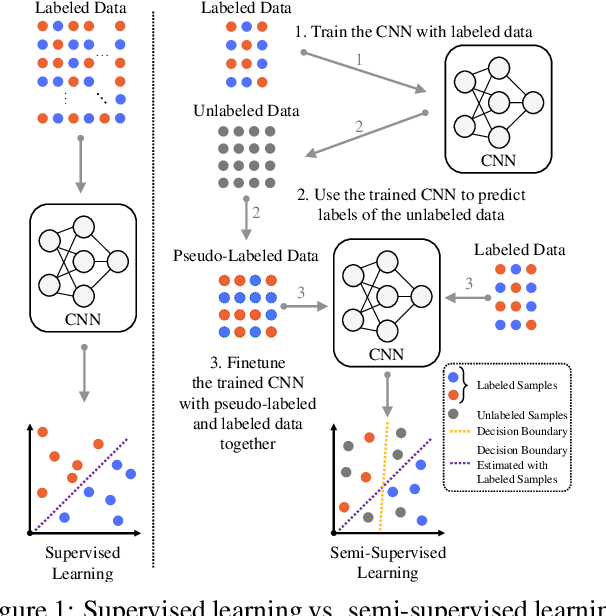

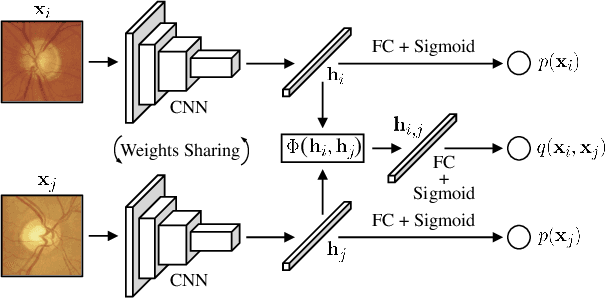
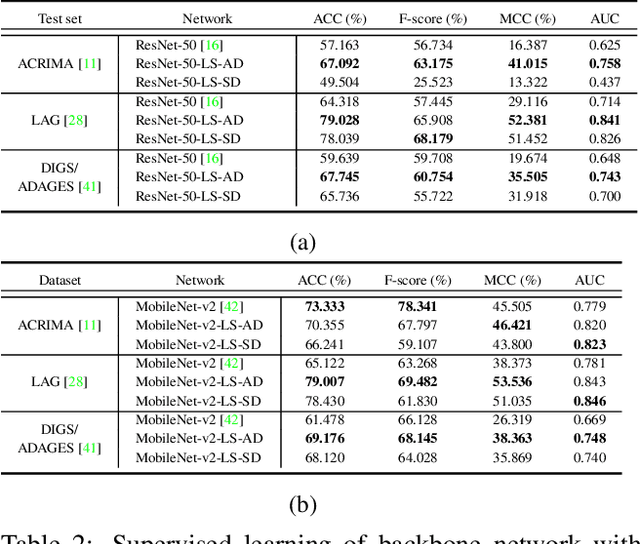
Convolutional neural networks (CNNs) are a promising technique for automated glaucoma diagnosis from images of the fundus, and these images are routinely acquired as part of an ophthalmic exam. Nevertheless, CNNs typically require a large amount of well-labeled data for training, which may not be available in many biomedical image classification applications, especially when diseases are rare and where labeling by experts is costly. This paper makes two contributions to address this issue: (1) It introduces a new network architecture and training method for low-shot learning when labeled data are limited and imbalanced, and (2) it introduces a new semi-supervised learning strategy that uses additional unlabeled training data to achieve great accuracy. Our multi-task twin neural network (MTTNN) can use any backbone CNN, and we demonstrate with ResNet-50 and MobileNet-v2 that its accuracy with limited training data approaches the accuracy of a finetuned backbone trained with a dataset that is 50 times larger. We also introduce One-Vote Veto (OVV) self-training, a semi-supervised learning strategy, that is designed specifically for MTTNNs. By taking both self-predictions and contrastive-predictions of the unlabeled training data into account, OVV self-training provides additional pseudo labels for finetuning a pretrained MTTNN. Using a large dataset with more than 50,000 fundus images acquired over 25 years, extensive experimental results demonstrate the effectiveness of low-shot learning with MTTNN and semi-supervised learning with OVV. Three additional, smaller clinical datasets of fundus images acquired under different conditions (cameras, instruments, locations, populations), are used to demonstrate generalizability of the methods. Source code and pretrained models will be publicly available upon publication.