 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Domain-Invariant Embedding for Unsupervised Domain Adaptation Using Class-Conditioned Distribution Alignment
Jul 04, 2019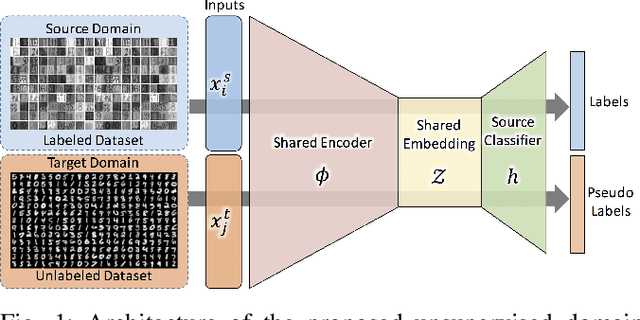

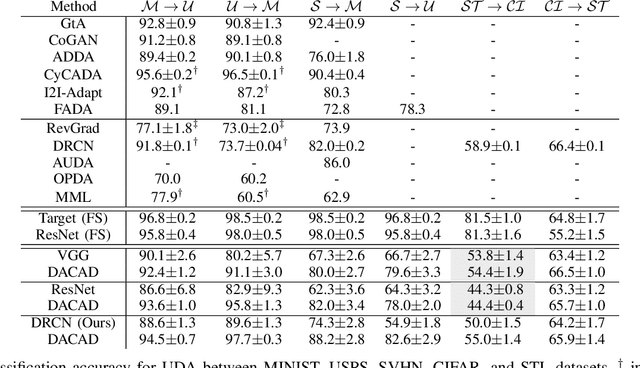
We address the problem of unsupervised domain adaptation (UDA) by learning a cross-domain agnostic embedding space, where the distance between the probability distributions of the two source and target visual domains is minimized. We use the output space of a shared cross-domain deep encoder to model the embedding space anduse the Sliced-Wasserstein Distance (SWD) to measure and minimize the distance between the embedded distributions of two source and target domains to enforce the embedding to be domain-agnostic.Additionally, we use the source domain labeled data to train a deep classifier from the embedding space to the label space to enforce the embedding space to be discriminative.As a result of this training scheme, we provide an effective solution to train the deep classification network on the source domain such that it will generalize well on the target domain, where only unlabeled training data is accessible. To mitigate the challenge of class matching, we also align corresponding classes in the embedding space by using high confidence pseudo-labels for the target domain, i.e. assigning the class for which the source classifier has a high prediction probability. We provide theoretical justification as well as experimental results on UDA benchmark tasks to demonstrate that our method is effective and leads to state-of-the-art performance.
Multi-Agent Distributed Lifelong Learning for Collective Knowledge Acquisition
Feb 20, 2018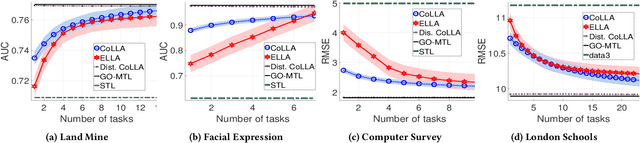
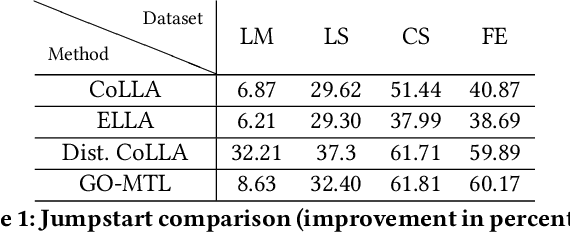
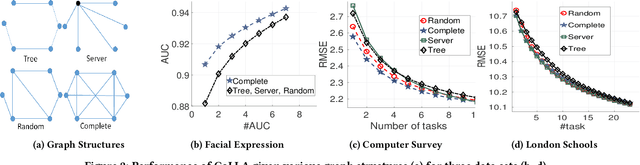
Lifelong machine learning methods acquire knowledge over a series of consecutive tasks, continually building upon their experience. Current lifelong learning algorithms rely upon a single learning agent that has centralized access to all data. In this paper, we extend the idea of lifelong learning from a single agent to a network of multiple agents that collectively learn a series of tasks. Each agent faces some (potentially unique) set of tasks; the key idea is that knowledge learned from these tasks may benefit other agents trying to learn different (but related) tasks. Our Collective Lifelong Learning Algorithm (CoLLA) provides an efficient way for a network of agents to share their learned knowledge in a distributed and decentralized manner, while preserving the privacy of the locally observed data. Note that a decentralized scheme is a subclass of distributed algorithms where a central server does not exist and in addition to data, computations are also distributed among the agents. We provide theoretical guarantees for robust performance of the algorithm and empirically demonstrate that CoLLA outperforms existing approaches for distributed multi-task learning on a variety of data sets.
Image to Image Translation for Domain Adaptation
Dec 01, 2017

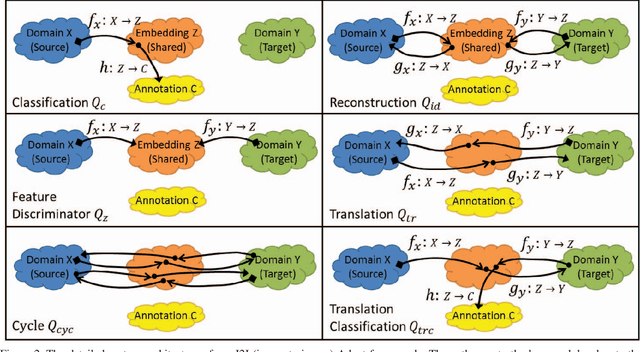
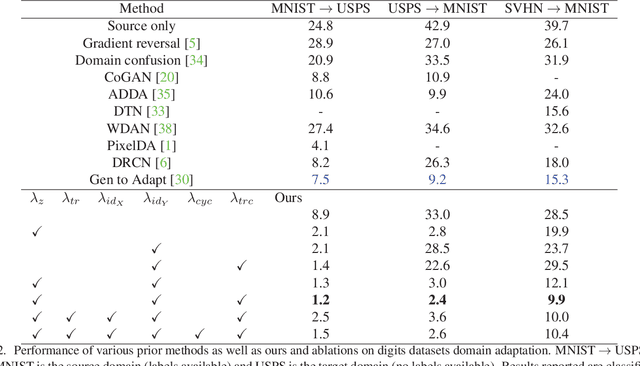
We propose a general framework for unsupervised domain adaptation, which allows deep neural networks trained on a source domain to be tested on a different target domain without requiring any training annotations in the target domain. This is achieved by adding extra networks and losses that help regularize the features extracted by the backbone encoder network. To this end we propose the novel use of the recently proposed unpaired image-toimage translation framework to constrain the features extracted by the encoder network. Specifically, we require that the features extracted are able to reconstruct the images in both domains. In addition we require that the distribution of features extracted from images in the two domains are indistinguishable. Many recent works can be seen as specific cases of our general framework. We apply our method for domain adaptation between MNIST, USPS, and SVHN datasets, and Amazon, Webcam and DSLR Office datasets in classification tasks, and also between GTA5 and Cityscapes datasets for a segmentation task. We demonstrate state of the art performance on each of these datasets.
Joint Dictionaries for Zero-Shot Learning
Sep 12, 2017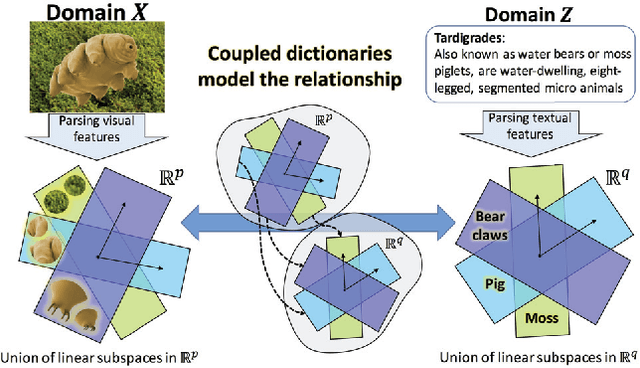
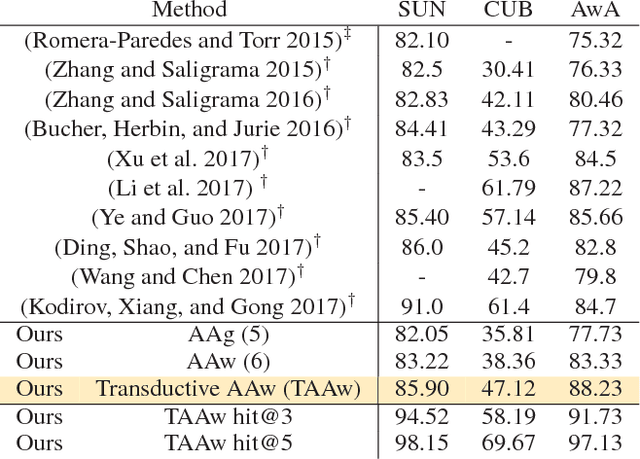
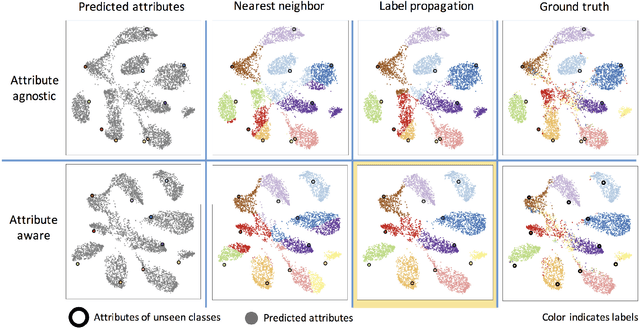
A classic approach toward zero-shot learning (ZSL) is to map the input domain to a set of semantically meaningful attributes that could be used later on to classify unseen classes of data (e.g. visual data). In this paper, we propose to learn a visual feature dictionary that has semantically meaningful atoms. Such dictionary is learned via joint dictionary learning for the visual domain and the attribute domain, while enforcing the same sparse coding for both dictionaries. Our novel attribute aware formulation provides an algorithmic solution to the domain shift/hubness problem in ZSL. Upon learning the joint dictionaries, images from unseen classes can be mapped into the attribute space by finding the attribute aware joint sparse representation using solely the visual data. We demonstrate that our approach provides superior or comparable performance to that of the state of the art on benchmark datasets.