 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBolt3D: Generating 3D Scenes in Seconds
Mar 18, 2025We present a latent diffusion model for fast feed-forward 3D scene generation. Given one or more images, our model Bolt3D directly samples a 3D scene representation in less than seven seconds on a single GPU. We achieve this by leveraging powerful and scalable existing 2D diffusion network architectures to produce consistent high-fidelity 3D scene representations. To train this model, we create a large-scale multiview-consistent dataset of 3D geometry and appearance by applying state-of-the-art dense 3D reconstruction techniques to existing multiview image datasets. Compared to prior multiview generative models that require per-scene optimization for 3D reconstruction, Bolt3D reduces the inference cost by a factor of up to 300 times.
CAT3D: Create Anything in 3D with Multi-View Diffusion Models
May 16, 2024



Advances in 3D reconstruction have enabled high-quality 3D capture, but require a user to collect hundreds to thousands of images to create a 3D scene. We present CAT3D, a method for creating anything in 3D by simulating this real-world capture process with a multi-view diffusion model. Given any number of input images and a set of target novel viewpoints, our model generates highly consistent novel views of a scene. These generated views can be used as input to robust 3D reconstruction techniques to produce 3D representations that can be rendered from any viewpoint in real-time. CAT3D can create entire 3D scenes in as little as one minute, and outperforms existing methods for single image and few-view 3D scene creation. See our project page for results and interactive demos at https://cat3d.github.io .
Generative Powers of Ten
Dec 04, 2023We present a method that uses a text-to-image model to generate consistent content across multiple image scales, enabling extreme semantic zooms into a scene, e.g., ranging from a wide-angle landscape view of a forest to a macro shot of an insect sitting on one of the tree branches. We achieve this through a joint multi-scale diffusion sampling approach that encourages consistency across different scales while preserving the integrity of each individual sampling process. Since each generated scale is guided by a different text prompt, our method enables deeper levels of zoom than traditional super-resolution methods that may struggle to create new contextual structure at vastly different scales. We compare our method qualitatively with alternative techniques in image super-resolution and outpainting, and show that our method is most effective at generating consistent multi-scale content.
VQ3D: Learning a 3D-Aware Generative Model on ImageNet
Feb 14, 2023


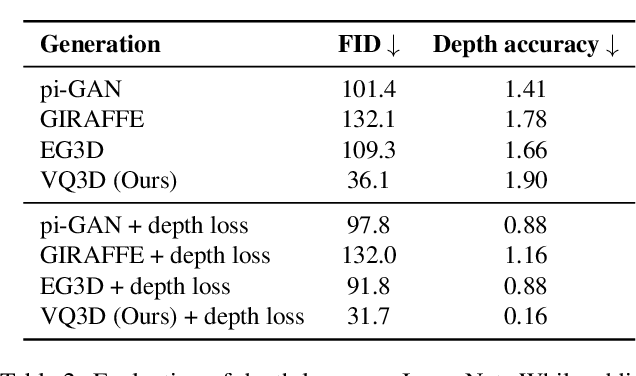
Recent work has shown the possibility of training generative models of 3D content from 2D image collections on small datasets corresponding to a single object class, such as human faces, animal faces, or cars. However, these models struggle on larger, more complex datasets. To model diverse and unconstrained image collections such as ImageNet, we present VQ3D, which introduces a NeRF-based decoder into a two-stage vector-quantized autoencoder. Our Stage 1 allows for the reconstruction of an input image and the ability to change the camera position around the image, and our Stage 2 allows for the generation of new 3D scenes. VQ3D is capable of generating and reconstructing 3D-aware images from the 1000-class ImageNet dataset of 1.2 million training images. We achieve an ImageNet generation FID score of 16.8, compared to 69.8 for the next best baseline method.
NeRF in the Dark: High Dynamic Range View Synthesis from Noisy Raw Images
Nov 26, 2021
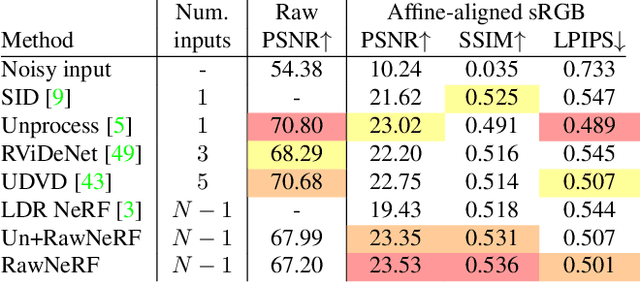
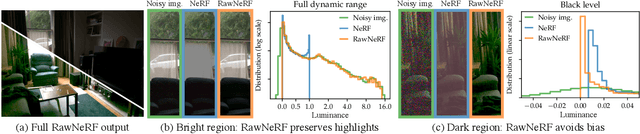
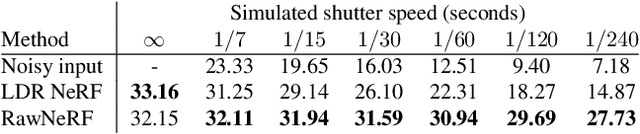
Neural Radiance Fields (NeRF) is a technique for high quality novel view synthesis from a collection of posed input images. Like most view synthesis methods, NeRF uses tonemapped low dynamic range (LDR) as input; these images have been processed by a lossy camera pipeline that smooths detail, clips highlights, and distorts the simple noise distribution of raw sensor data. We modify NeRF to instead train directly on linear raw images, preserving the scene's full dynamic range. By rendering raw output images from the resulting NeRF, we can perform novel high dynamic range (HDR) view synthesis tasks. In addition to changing the camera viewpoint, we can manipulate focus, exposure, and tonemapping after the fact. Although a single raw image appears significantly more noisy than a postprocessed one, we show that NeRF is highly robust to the zero-mean distribution of raw noise. When optimized over many noisy raw inputs (25-200), NeRF produces a scene representation so accurate that its rendered novel views outperform dedicated single and multi-image deep raw denoisers run on the same wide baseline input images. As a result, our method, which we call RawNeRF, can reconstruct scenes from extremely noisy images captured in near-darkness.
Advances in Neural Rendering
Nov 10, 2021Synthesizing photo-realistic images and videos is at the heart of computer graphics and has been the focus of decades of research. Traditionally, synthetic images of a scene are generated using rendering algorithms such as rasterization or ray tracing, which take specifically defined representations of geometry and material properties as input. Collectively, these inputs define the actual scene and what is rendered, and are referred to as the scene representation (where a scene consists of one or more objects). Example scene representations are triangle meshes with accompanied textures (e.g., created by an artist), point clouds (e.g., from a depth sensor), volumetric grids (e.g., from a CT scan), or implicit surface functions (e.g., truncated signed distance fields). The reconstruction of such a scene representation from observations using differentiable rendering losses is known as inverse graphics or inverse rendering. Neural rendering is closely related, and combines ideas from classical computer graphics and machine learning to create algorithms for synthesizing images from real-world observations. Neural rendering is a leap forward towards the goal of synthesizing photo-realistic image and video content. In recent years, we have seen immense progress in this field through hundreds of publications that show different ways to inject learnable components into the rendering pipeline. This state-of-the-art report on advances in neural rendering focuses on methods that combine classical rendering principles with learned 3D scene representations, often now referred to as neural scene representations. A key advantage of these methods is that they are 3D-consistent by design, enabling applications such as novel viewpoint synthesis of a captured scene. In addition to methods that handle static scenes, we cover neural scene representations for modeling non-rigidly deforming objects...
IBRNet: Learning Multi-View Image-Based Rendering
Feb 25, 2021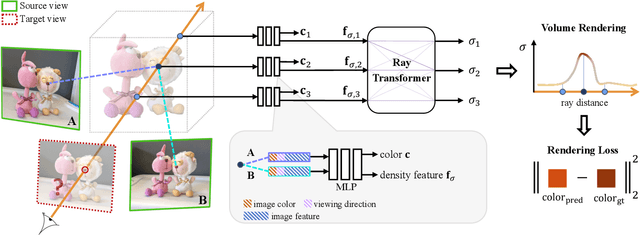
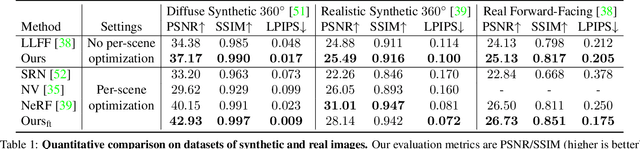
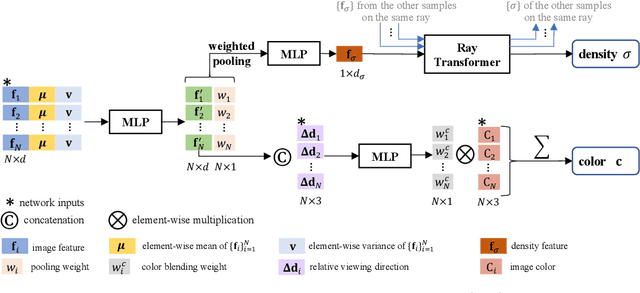
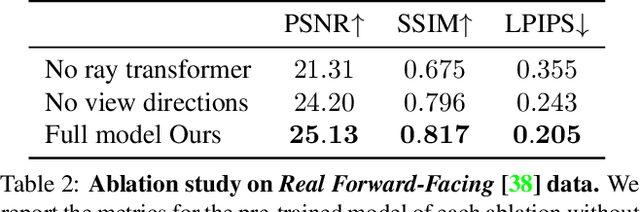
We present a method that synthesizes novel views of complex scenes by interpolating a sparse set of nearby views. The core of our method is a network architecture that includes a multilayer perceptron and a ray transformer that estimates radiance and volume density at continuous 5D locations (3D spatial locations and 2D viewing directions), drawing appearance information on the fly from multiple source views. By drawing on source views at render time, our method hearkens back to classic work on image-based rendering (IBR), and allows us to render high-resolution imagery. Unlike neural scene representation work that optimizes per-scene functions for rendering, we learn a generic view interpolation function that generalizes to novel scenes. We render images using classic volume rendering, which is fully differentiable and allows us to train using only multi-view posed images as supervision. Experiments show that our method outperforms recent novel view synthesis methods that also seek to generalize to novel scenes. Further, if fine-tuned on each scene, our method is competitive with state-of-the-art single-scene neural rendering methods.
Neural Reflectance Fields for Appearance Acquisition
Aug 16, 2020
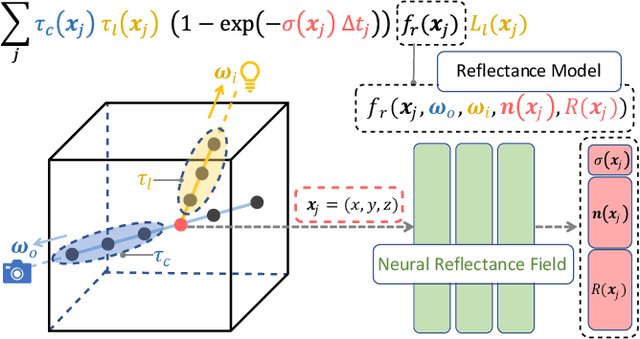
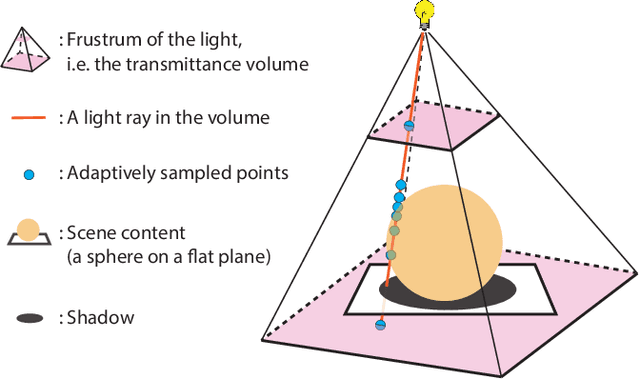
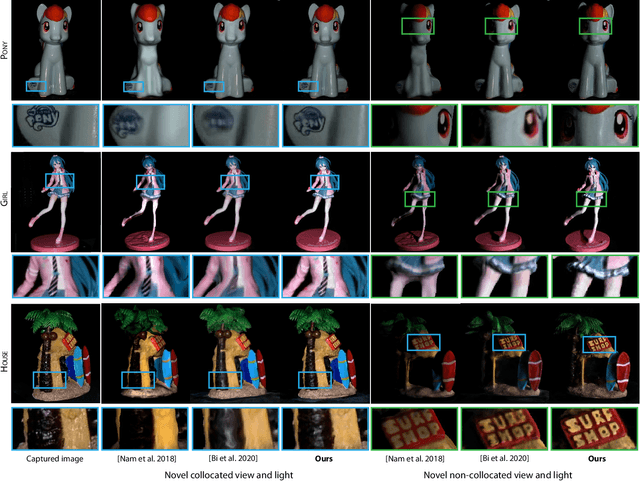
We present Neural Reflectance Fields, a novel deep scene representation that encodes volume density, normal and reflectance properties at any 3D point in a scene using a fully-connected neural network. We combine this representation with a physically-based differentiable ray marching framework that can render images from a neural reflectance field under any viewpoint and light. We demonstrate that neural reflectance fields can be estimated from images captured with a simple collocated camera-light setup, and accurately model the appearance of real-world scenes with complex geometry and reflectance. Once estimated, they can be used to render photo-realistic images under novel viewpoint and (non-collocated) lighting conditions and accurately reproduce challenging effects like specularities, shadows and occlusions. This allows us to perform high-quality view synthesis and relighting that is significantly better than previous methods. We also demonstrate that we can compose the estimated neural reflectance field of a real scene with traditional scene models and render them using standard Monte Carlo rendering engines. Our work thus enables a complete pipeline from high-quality and practical appearance acquisition to 3D scene composition and rendering.