 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Elastic Objects
Jan 12, 2022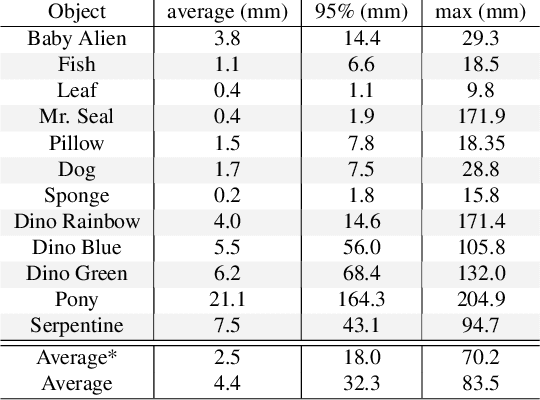

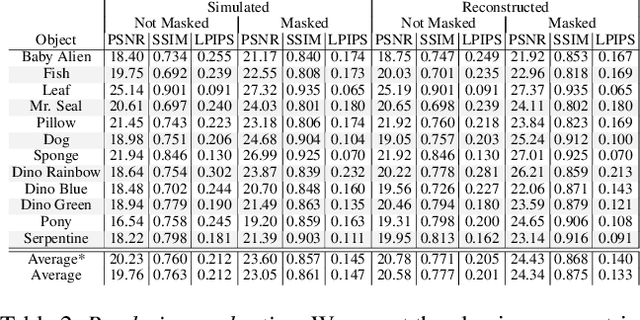

We present Virtual Elastic Objects (VEOs): virtual objects that not only look like their real-world counterparts but also behave like them, even when subject to novel interactions. Achieving this presents multiple challenges: not only do objects have to be captured including the physical forces acting on them, then faithfully reconstructed and rendered, but also plausible material parameters found and simulated. To create VEOs, we built a multi-view capture system that captures objects under the influence of a compressed air stream. Building on recent advances in model-free, dynamic Neural Radiance Fields, we reconstruct the objects and corresponding deformation fields. We propose to use a differentiable, particle-based simulator to use these deformation fields to find representative material parameters, which enable us to run new simulations. To render simulated objects, we devise a method for integrating the simulation results with Neural Radiance Fields. The resulting method is applicable to a wide range of scenarios: it can handle objects composed of inhomogeneous material, with very different shapes, and it can simulate interactions with other virtual objects. We present our results using a newly collected dataset of 12 objects under a variety of force fields, which will be shared with the community.
Advances in Neural Rendering
Nov 10, 2021Synthesizing photo-realistic images and videos is at the heart of computer graphics and has been the focus of decades of research. Traditionally, synthetic images of a scene are generated using rendering algorithms such as rasterization or ray tracing, which take specifically defined representations of geometry and material properties as input. Collectively, these inputs define the actual scene and what is rendered, and are referred to as the scene representation (where a scene consists of one or more objects). Example scene representations are triangle meshes with accompanied textures (e.g., created by an artist), point clouds (e.g., from a depth sensor), volumetric grids (e.g., from a CT scan), or implicit surface functions (e.g., truncated signed distance fields). The reconstruction of such a scene representation from observations using differentiable rendering losses is known as inverse graphics or inverse rendering. Neural rendering is closely related, and combines ideas from classical computer graphics and machine learning to create algorithms for synthesizing images from real-world observations. Neural rendering is a leap forward towards the goal of synthesizing photo-realistic image and video content. In recent years, we have seen immense progress in this field through hundreds of publications that show different ways to inject learnable components into the rendering pipeline. This state-of-the-art report on advances in neural rendering focuses on methods that combine classical rendering principles with learned 3D scene representations, often now referred to as neural scene representations. A key advantage of these methods is that they are 3D-consistent by design, enabling applications such as novel viewpoint synthesis of a captured scene. In addition to methods that handle static scenes, we cover neural scene representations for modeling non-rigidly deforming objects...
Non-Rigid Neural Radiance Fields: Reconstruction and Novel View Synthesis of a Deforming Scene from Monocular Video
Dec 23, 2020



In this tech report, we present the current state of our ongoing work on reconstructing Neural Radiance Fields (NERF) of general non-rigid scenes via ray bending. Non-rigid NeRF (NR-NeRF) takes RGB images of a deforming object (e.g., from a monocular video) as input and then learns a geometry and appearance representation that not only allows to reconstruct the input sequence but also to re-render any time step into novel camera views with high fidelity. In particular, we show that a consumer-grade camera is sufficient to synthesize convincing bullet-time videos of short and simple scenes. In addition, the resulting representation enables correspondence estimation across views and time, and provides rigidity scores for each point in the scene. We urge the reader to watch the supplemental videos for qualitative results. We will release our code.
PatchNets: Patch-Based Generalizable Deep Implicit 3D Shape Representations
Aug 04, 2020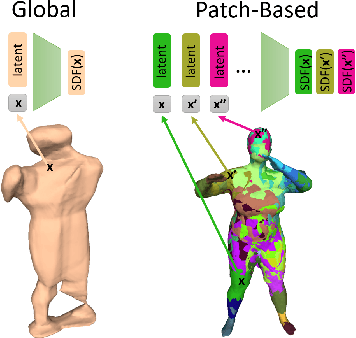
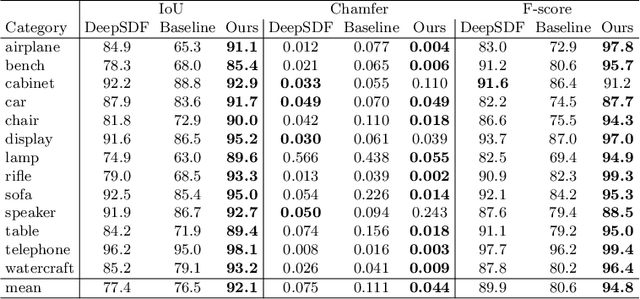

Implicit surface representations, such as signed-distance functions, combined with deep learning have led to impressive models which can represent detailed shapes of objects with arbitrary topology. Since a continuous function is learned, the reconstructions can also be extracted at any arbitrary resolution. However, large datasets such as ShapeNet are required to train such models. In this paper, we present a new mid-level patch-based surface representation. At the level of patches, objects across different categories share similarities, which leads to more generalizable models. We then introduce a novel method to learn this patch-based representation in a canonical space, such that it is as object-agnostic as possible. We show that our representation trained on one category of objects from ShapeNet can also well represent detailed shapes from any other category. In addition, it can be trained using much fewer shapes, compared to existing approaches. We show several applications of our new representation, including shape interpolation and partial point cloud completion. Due to explicit control over positions, orientations and scales of patches, our representation is also more controllable compared to object-level representations, which enables us to deform encoded shapes non-rigidly.
DispVoxNets: Non-Rigid Point Set Alignment with Supervised Learning Proxies
Aug 06, 2019
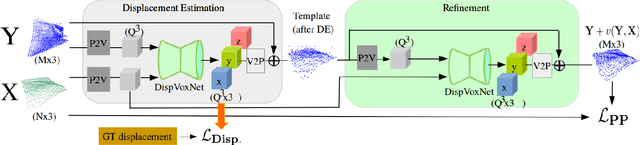
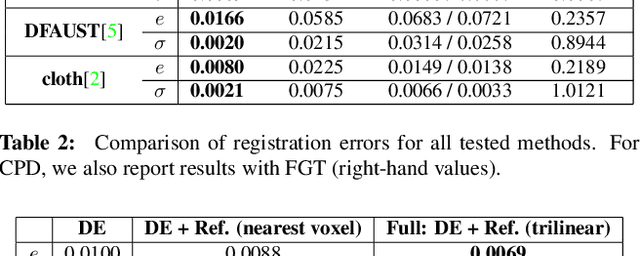
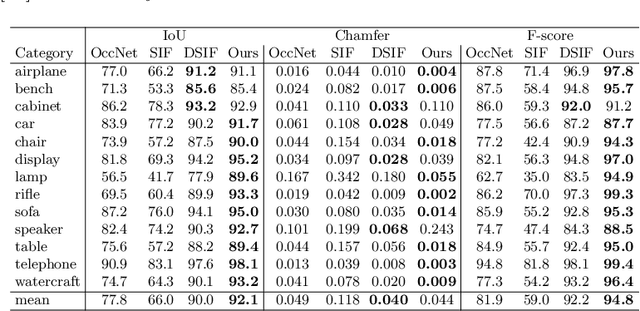
We introduce a supervised-learning framework for non-rigid point set alignment of a new kind - Displacements on Voxels Networks (DispVoxNets) - which abstracts away from the point set representation and regresses 3D displacement fields on regularly sampled proxy 3D voxel grids. Thanks to recently released collections of deformable objects with known intra-state correspondences, DispVoxNets learn a deformation model and further priors (e.g., weak point topology preservation) for different object categories such as cloths, human bodies and faces. DispVoxNets cope with large deformations, noise and clustered outliers more robustly than the state-of-the-art. At test time, our approach runs orders of magnitude faster than previous techniques. All properties of DispVoxNets are ascertained numerically and qualitatively in extensive experiments and comparisons to several previous methods.
DEMEA: Deep Mesh Autoencoders for Non-Rigidly Deforming Objects
May 24, 2019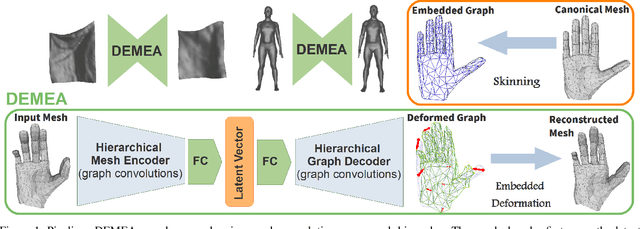
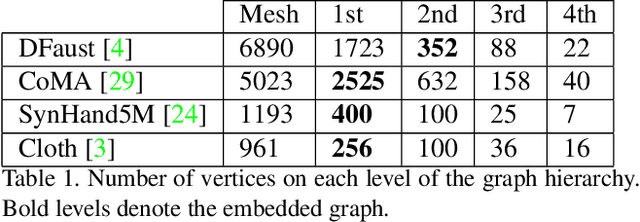
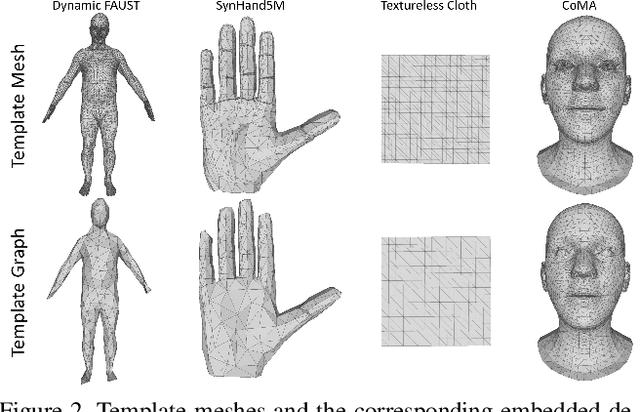

Mesh autoencoders are commonly used for dimensionality reduction, sampling and mesh modeling. We propose a general-purpose DEep MEsh Autoencoder (DEMEA) which adds a novel embedded deformation layer to a graph-convolutional mesh autoencoder. The embedded deformation layer (EDL) is a differentiable deformable geometric proxy which explicitly models point displacements of non-rigid deformations in a lower dimensional space and serves as a local rigidity regularizer. DEMEA decouples the parameterization of the deformation from the final mesh resolution since the deformation is defined over a lower dimensional embedded deformation graph. We perform a large-scale study on four different datasets of deformable objects. Reasoning about the local rigidity of meshes using EDL allows us to achieve higher-quality results for highly deformable objects, compared to directly regressing vertex positions. We demonstrate multiple applications of DEMEA, including non-rigid 3D reconstruction from depth and shading cues, non-rigid surface tracking, as well as the transfer of deformations over different meshes.
Sequential Attacks on Agents for Long-Term Adversarial Goals
Jul 05, 2018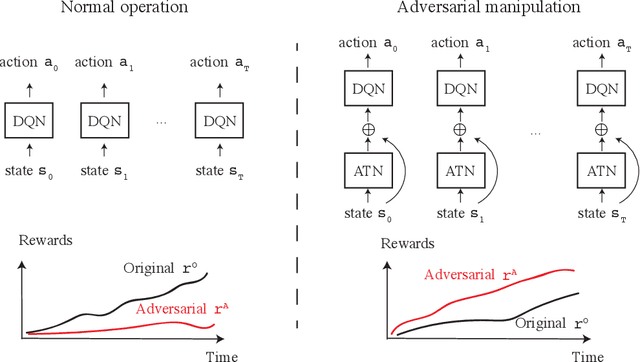
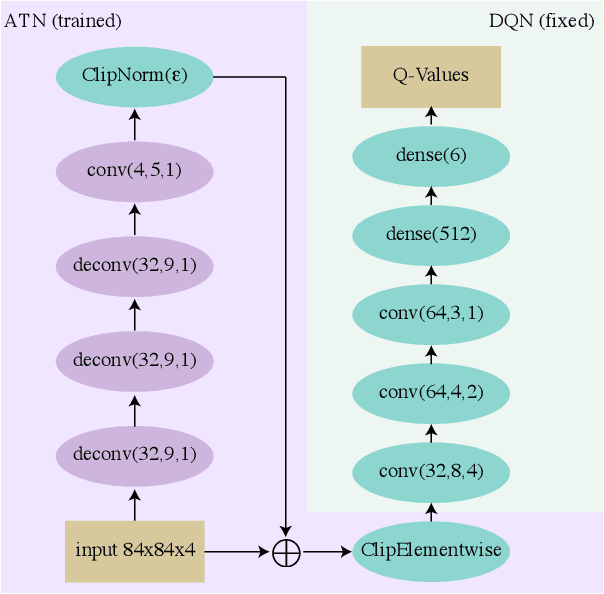
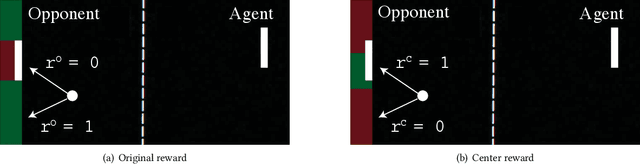
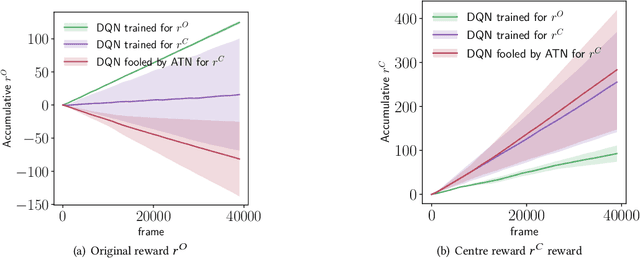
Reinforcement learning (RL) has advanced greatly in the past few years with the employment of effective deep neural networks (DNNs) on the policy networks. With the great effectiveness came serious vulnerability issues with DNNs that small adversarial perturbations on the input can change the output of the network. Several works have pointed out that learned agents with a DNN policy network can be manipulated against achieving the original task through a sequence of small perturbations on the input states. In this paper, we demonstrate furthermore that it is also possible to impose an arbitrary adversarial reward on the victim policy network through a sequence of attacks. Our method involves the latest adversarial attack technique, Adversarial Transformer Network (ATN), that learns to generate the attack and is easy to integrate into the policy network. As a result of our attack, the victim agent is misguided to optimise for the adversarial reward over time. Our results expose serious security threats for RL applications in safety-critical systems including drones, medical analysis, and self-driving cars.