 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHR: Momentum Human Rig
Nov 19, 2025We present MHR, a parametric human body model that combines the decoupled skeleton/shape paradigm of ATLAS with a flexible, modern rig and pose corrective system inspired by the Momentum library. Our model enables expressive, anatomically plausible human animation, supporting non-linear pose correctives, and is designed for robust integration in AR/VR and graphics pipelines.
Virtual Elastic Objects
Jan 12, 2022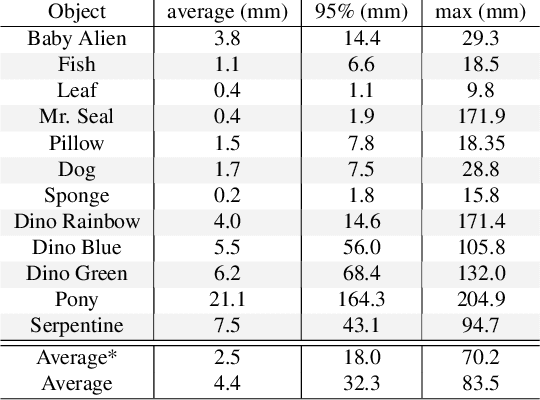

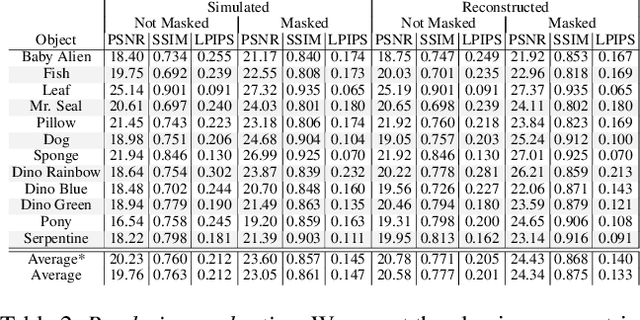

We present Virtual Elastic Objects (VEOs): virtual objects that not only look like their real-world counterparts but also behave like them, even when subject to novel interactions. Achieving this presents multiple challenges: not only do objects have to be captured including the physical forces acting on them, then faithfully reconstructed and rendered, but also plausible material parameters found and simulated. To create VEOs, we built a multi-view capture system that captures objects under the influence of a compressed air stream. Building on recent advances in model-free, dynamic Neural Radiance Fields, we reconstruct the objects and corresponding deformation fields. We propose to use a differentiable, particle-based simulator to use these deformation fields to find representative material parameters, which enable us to run new simulations. To render simulated objects, we devise a method for integrating the simulation results with Neural Radiance Fields. The resulting method is applicable to a wide range of scenarios: it can handle objects composed of inhomogeneous material, with very different shapes, and it can simulate interactions with other virtual objects. We present our results using a newly collected dataset of 12 objects under a variety of force fields, which will be shared with the community.
Leveraging Unsupervised Image Registration for Discovery of Landmark Shape Descriptor
Nov 13, 2021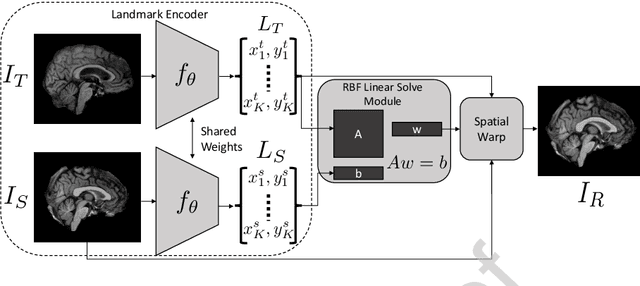
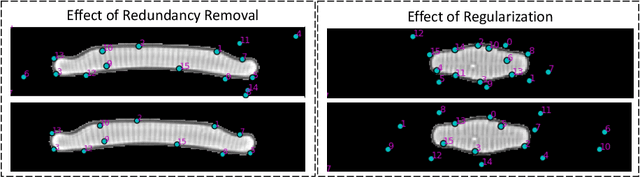
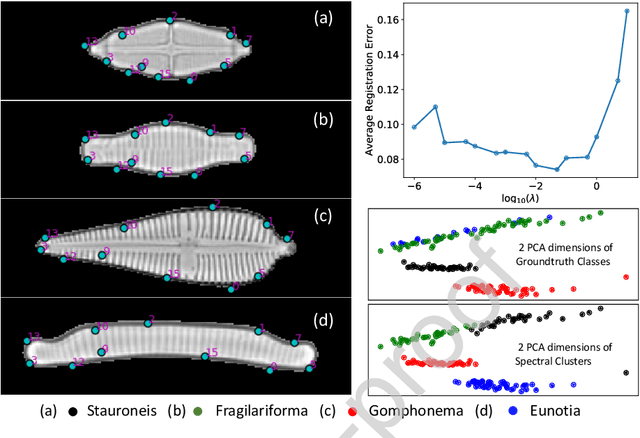
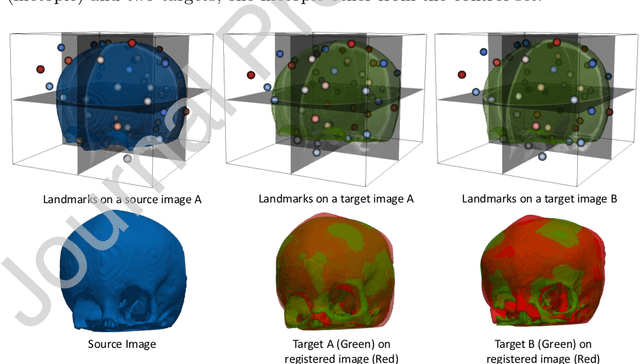
In current biological and medical research, statistical shape modeling (SSM) provides an essential framework for the characterization of anatomy/morphology. Such analysis is often driven by the identification of a relatively small number of geometrically consistent features found across the samples of a population. These features can subsequently provide information about the population shape variation. Dense correspondence models can provide ease of computation and yield an interpretable low-dimensional shape descriptor when followed by dimensionality reduction. However, automatic methods for obtaining such correspondences usually require image segmentation followed by significant preprocessing, which is taxing in terms of both computation as well as human resources. In many cases, the segmentation and subsequent processing require manual guidance and anatomy specific domain expertise. This paper proposes a self-supervised deep learning approach for discovering landmarks from images that can directly be used as a shape descriptor for subsequent analysis. We use landmark-driven image registration as the primary task to force the neural network to discover landmarks that register the images well. We also propose a regularization term that allows for robust optimization of the neural network and ensures that the landmarks uniformly span the image domain. The proposed method circumvents segmentation and preprocessing and directly produces a usable shape descriptor using just 2D or 3D images. In addition, we also propose two variants on the training loss function that allows for prior shape information to be integrated into the model. We apply this framework on several 2D and 3D datasets to obtain their shape descriptors, and analyze their utility for various applications.
DeepSSM: A Blueprint for Image-to-Shape Deep Learning Models
Oct 14, 2021

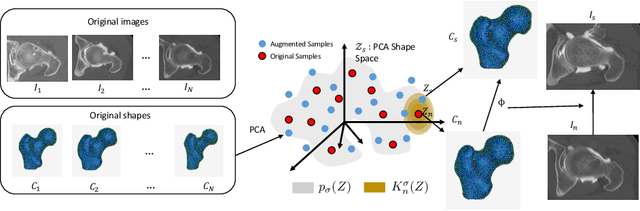
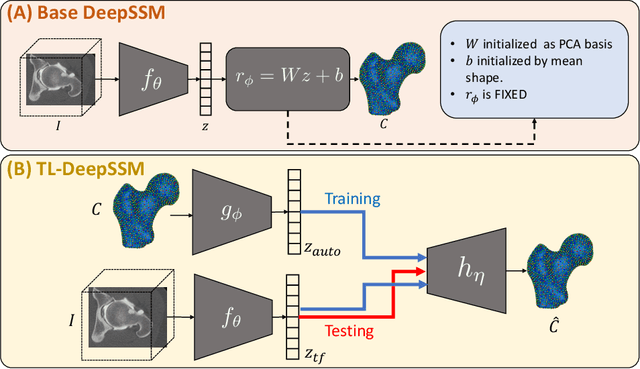
Statistical shape modeling (SSM) characterizes anatomical variations in a population of shapes generated from medical images. SSM requires consistent shape representation across samples in shape cohort. Establishing this representation entails a processing pipeline that includes anatomy segmentation, re-sampling, registration, and non-linear optimization. These shape representations are then used to extract low-dimensional shape descriptors that facilitate subsequent analyses in different applications. However, the current process of obtaining these shape descriptors from imaging data relies on human and computational resources, requiring domain expertise for segmenting anatomies of interest. Moreover, this same taxing pipeline needs to be repeated to infer shape descriptors for new image data using a pre-trained/existing shape model. Here, we propose DeepSSM, a deep learning-based framework for learning the functional mapping from images to low-dimensional shape descriptors and their associated shape representations, thereby inferring statistical representation of anatomy directly from 3D images. Once trained using an existing shape model, DeepSSM circumvents the heavy and manual pre-processing and segmentation and significantly improves the computational time, making it a viable solution for fully end-to-end SSM applications. In addition, we introduce a model-based data-augmentation strategy to address data scarcity. Finally, this paper presents and analyzes two different architectural variants of DeepSSM with different loss functions using three medical datasets and their downstream clinical application. Experiments showcase that DeepSSM performs comparably or better to the state-of-the-art SSM both quantitatively and on application-driven downstream tasks. Therefore, DeepSSM aims to provide a comprehensive blueprint for deep learning-based image-to-shape models.
Capturing Detailed Deformations of Moving Human Bodies
Feb 15, 2021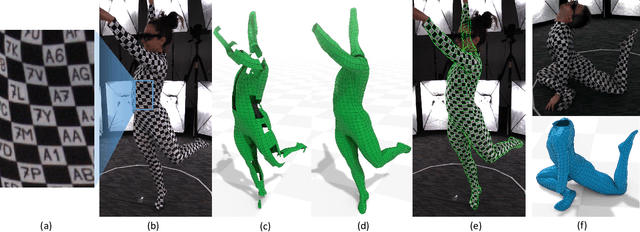

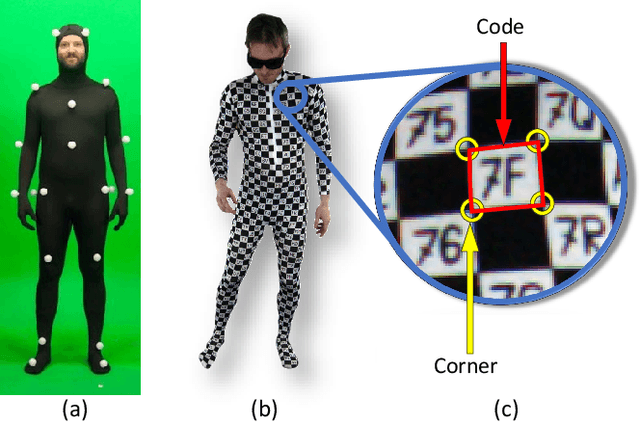
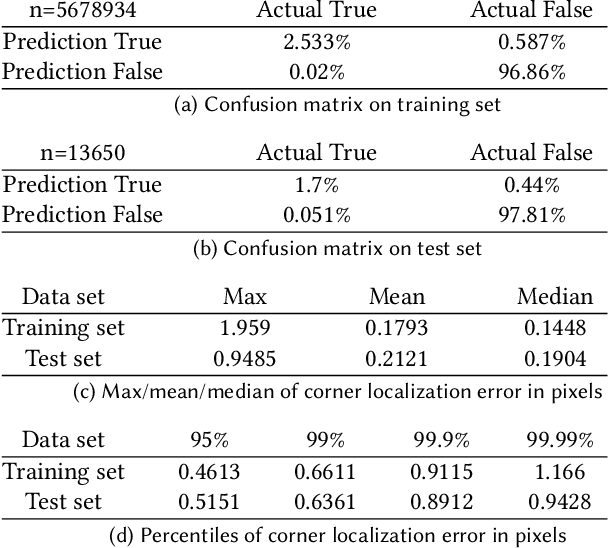
We present a new method to capture detailed human motion, sampling more than 1000 unique points on the body. Our method outputs highly accurate 4D (spatio-temporal) point coordinates and, crucially, automatically assigns a unique label to each of the points. The locations and unique labels of the points are inferred from individual 2D input images only, without relying on temporal tracking or any human body shape or skeletal kinematics models. Therefore, our captured point trajectories contain all of the details from the input images, including motion due to breathing, muscle contractions and flesh deformation, and are well suited to be used as training data to fit advanced models of the human body and its motion. The key idea behind our system is a new type of motion capture suit which contains a special pattern with checkerboard-like corners and two-letter codes. The images from our multi-camera system are processed by a sequence of neural networks which are trained to localize the corners and recognize the codes, while being robust to suit stretching and self-occlusions of the body. Our system relies only on standard RGB or monochrome sensors and fully passive lighting and the passive suit, making our method easy to replicate, deploy and use. Our experiments demonstrate highly accurate captures of a wide variety of human poses, including challenging motions such as yoga, gymnastics, or rolling on the ground.
Differentiable Implicit Soft-Body Physics
Feb 11, 2021We present a differentiable soft-body physics simulator that can be composed with neural networks as a differentiable layer. In contrast to other differentiable physics approaches that use explicit forward models to define state transitions, we focus on implicit state transitions defined via function minimization. Implicit state transitions appear in implicit numerical integration methods, which offer the benefits of large time steps and excellent numerical stability, but require a special treatment to achieve differentiability due to the absence of an explicit differentiable forward pass. In contrast to other implicit differentiation approaches that require explicit formulas for the force function and the force Jacobian matrix, we present an energy-based approach that allows us to compute these derivatives automatically and in a matrix-free fashion via reverse-mode automatic differentiation. This allows for more flexibility and productivity when defining physical models and is particularly important in the context of neural network training, which often relies on reverse-mode automatic differentiation (backpropagation). We demonstrate the effectiveness of our differentiable simulator in policy optimization for locomotion tasks and show that it achieves better sample efficiency than model-free reinforcement learning.
Unsupervised Shape Normality Metric for Severity Quantification
Jul 18, 2020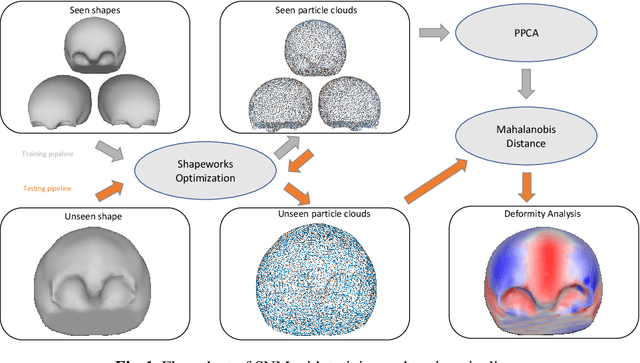
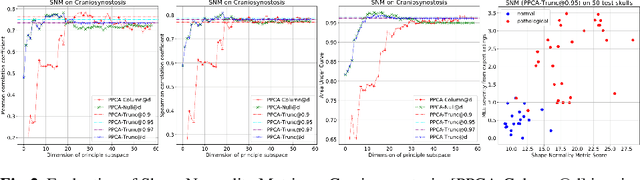

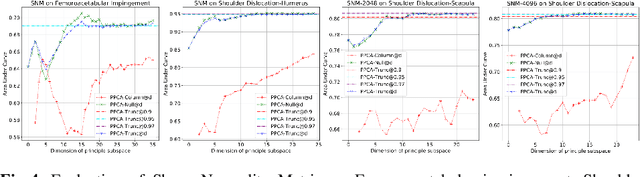
This work describes an unsupervised method to objectively quantify the abnormality of general anatomical shapes. The severity of an anatomical deformity often serves as a determinant in the clinical management of patients. However, experiential bias and distinctive random residuals among specialist individuals bring variability in diagnosis and patient management decisions, irrespective of the objective deformity degree. Therefore, supervised methods are prone to be misled given insufficient labeling of pathological samples that inevitably preserve human bias and inconsistency. Furthermore, subjects demonstrating a specific pathology are naturally rare relative to the normal population. To avoid relying on sufficient pathological samples by fully utilizing the power of normal samples, we propose the shape normality metric (SNM), which requires learning only from normal samples and zero knowledge about the pathology. We represent shapes by landmarks automatically inferred from the data and model the normal group by a multivariate Gaussian distribution. Extensive experiments on different anatomical datasets, including skulls, femurs, scapulae, and humeri, demonstrate that SNM can provide an effective normality measurement, which can significantly detect and indicate pathology. Therefore, SNM offers promising value in a variety of clinical applications.
Self-Supervised Discovery of Anatomical Shape Landmarks
Jun 13, 2020
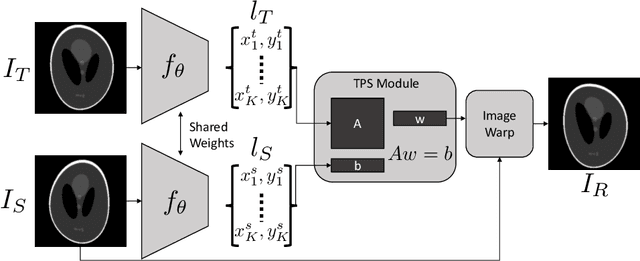


Statistical shape analysis is a very useful tool in a wide range of medical and biological applications. However, it typically relies on the ability to produce a relatively small number of features that can capture the relevant variability in a population. State-of-the-art methods for obtaining such anatomical features rely on either extensive preprocessing or segmentation and/or significant tuning and post-processing. These shortcomings limit the widespread use of shape statistics. We propose that effective shape representations should provide sufficient information to align/register images. Using this assumption we propose a self-supervised, neural network approach for automatically positioning and detecting landmarks in images that can be used for subsequent analysis. The network discovers the landmarks corresponding to anatomical shape features that promote good image registration in the context of a particular class of transformations. In addition, we also propose a regularization for the proposed network which allows for a uniform distribution of these discovered landmarks. In this paper, we present a complete framework, which only takes a set of input images and produces landmarks that are immediately usable for statistical shape analysis. We evaluate the performance on a phantom dataset as well as 2D and 3D images.
A Cooperative Autoencoder for Population-Based Regularization of CNN Image Registration
Aug 19, 2019

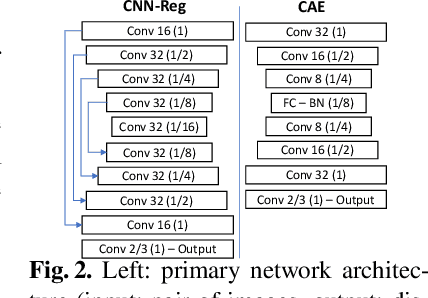
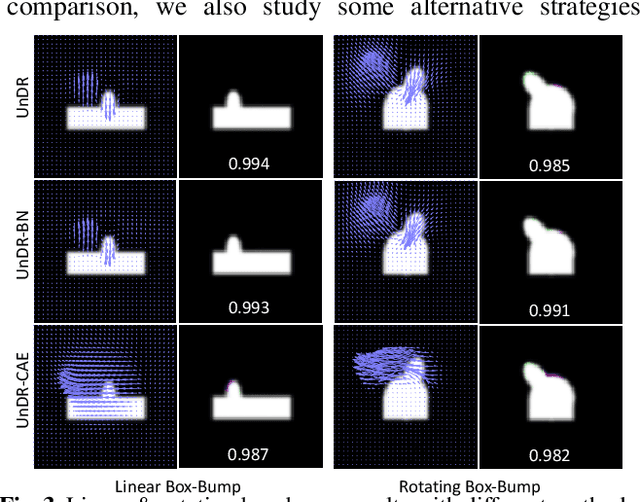
Spatial transformations are enablers in a variety of medical image analysis applications that entail aligning images to a common coordinate systems. Population analysis of such transformations is expected to capture the underlying image and shape variations, and hence these transformations are required to produce anatomically feasible correspondences. This is usually enforced through some smoothness-based generic regularization on deformation field. Alternatively, population-based regularization has been shown to produce anatomically accurate correspondences in cases where anatomically unaware (i.e., data independent) fail. Recently, deep networks have been for unsupervised image registration, these methods are computationally faster and maintains the accuracy of state of the art methods. However, these networks use smoothness penalty on deformation fields and ignores population-level statistics of the transformations. We propose a novel neural network architecture that simultaneously learns and uses the population-level statistics of the spatial transformations to regularize the neural networks for unsupervised image registration. This regularization is in the form of a bottleneck autoencoder, which encodes the population level information of the deformation fields in a low-dimensional manifold. The proposed architecture produces deformation fields that describe the population-level features and associated correspondences in an anatomically relevant manner and are statistically compact relative to the state-of-the-art approaches while maintaining computational efficiency. We demonstrate the efficacy of the proposed architecture on synthetic data sets, as well as 2D and 3D medical data.
CoopSubNet: Cooperating Subnetwork for Data-Driven Regularization of Deep Networks under Limited Training Budgets
Jun 13, 2019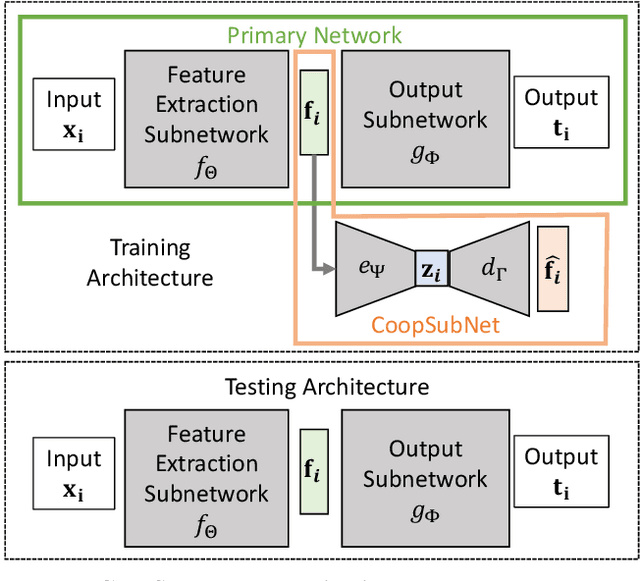
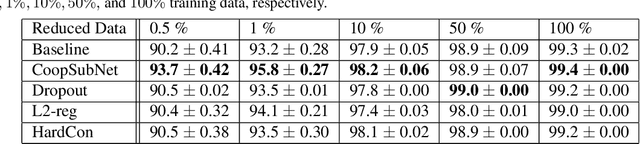
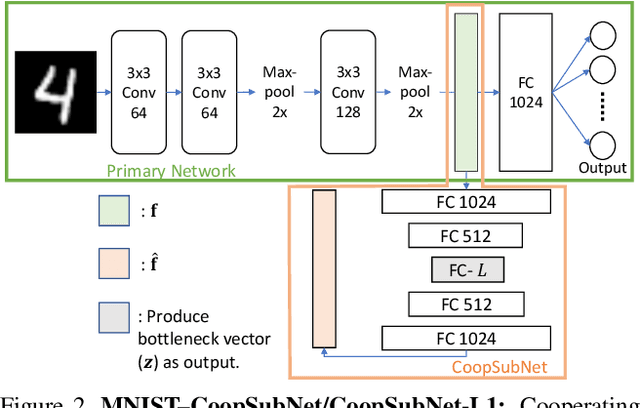

Deep networks are an integral part of the current machine learning paradigm. Their inherent ability to learn complex functional mappings between data and various target variables, while discovering hidden, task-driven features, makes them a powerful technology in a wide variety of applications. Nonetheless, the success of these networks typically relies on the availability of sufficient training data to optimize a large number of free parameters while avoiding overfitting, especially for networks with large capacity. In scenarios with limited training budgets, e.g., supervised tasks with limited labeled samples, several generic and/or task-specific regularization techniques, including data augmentation, have been applied to improve the generalization of deep networks.Typically such regularizations are introduced independently of that data or training scenario, and must therefore be tuned, tested, and modified to meet the needs of a particular network. In this paper, we propose a novel regularization framework that is driven by the population-level statistics of the feature space to be learned. The regularization is in the form of a \textbf{cooperating subnetwork}, which is an auto-encoder architecture attached to the feature space and trained in conjunction with the primary network. We introduce the architecture and training methodology and demonstrate the effectiveness of the proposed cooperative network-based regularization in a variety of tasks and architectures from the literature. Our code is freely available at \url{https://github.com/riddhishb/CoopSubNet