 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-realtime Facial Animation by Deep 3D Simulation Super-Resolution
May 05, 2023



We present a neural network-based simulation super-resolution framework that can efficiently and realistically enhance a facial performance produced by a low-cost, realtime physics-based simulation to a level of detail that closely approximates that of a reference-quality off-line simulator with much higher resolution (26x element count in our examples) and accurate physical modeling. Our approach is rooted in our ability to construct - via simulation - a training set of paired frames, from the low- and high-resolution simulators respectively, that are in semantic correspondence with each other. We use face animation as an exemplar of such a simulation domain, where creating this semantic congruence is achieved by simply dialing in the same muscle actuation controls and skeletal pose in the two simulators. Our proposed neural network super-resolution framework generalizes from this training set to unseen expressions, compensates for modeling discrepancies between the two simulations due to limited resolution or cost-cutting approximations in the real-time variant, and does not require any semantic descriptors or parameters to be provided as input, other than the result of the real-time simulation. We evaluate the efficacy of our pipeline on a variety of expressive performances and provide comparisons and ablation experiments for plausible variations and alternatives to our proposed scheme.
Capturing Detailed Deformations of Moving Human Bodies
Feb 15, 2021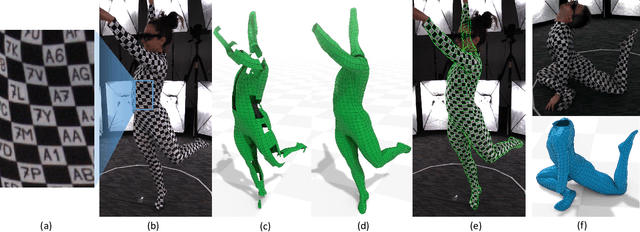

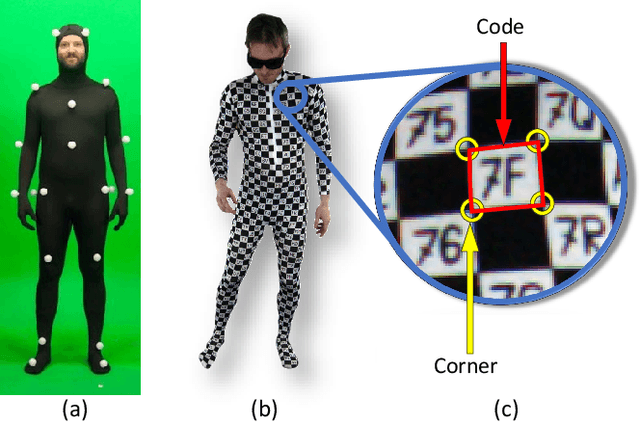
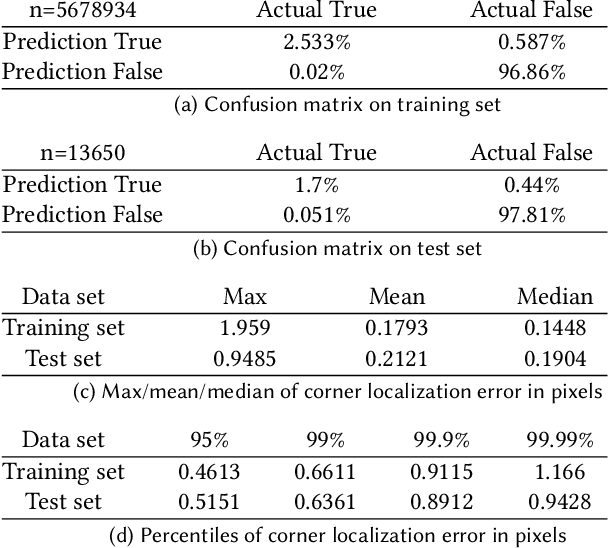
We present a new method to capture detailed human motion, sampling more than 1000 unique points on the body. Our method outputs highly accurate 4D (spatio-temporal) point coordinates and, crucially, automatically assigns a unique label to each of the points. The locations and unique labels of the points are inferred from individual 2D input images only, without relying on temporal tracking or any human body shape or skeletal kinematics models. Therefore, our captured point trajectories contain all of the details from the input images, including motion due to breathing, muscle contractions and flesh deformation, and are well suited to be used as training data to fit advanced models of the human body and its motion. The key idea behind our system is a new type of motion capture suit which contains a special pattern with checkerboard-like corners and two-letter codes. The images from our multi-camera system are processed by a sequence of neural networks which are trained to localize the corners and recognize the codes, while being robust to suit stretching and self-occlusions of the body. Our system relies only on standard RGB or monochrome sensors and fully passive lighting and the passive suit, making our method easy to replicate, deploy and use. Our experiments demonstrate highly accurate captures of a wide variety of human poses, including challenging motions such as yoga, gymnastics, or rolling on the ground.