 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable PyTorch Abstraction for Multi-GPU Gaussian Splatting
Jun 09, 2026Gaussian splatting methods have become increasingly popular for neural reconstruction of the real world. However, they are often limited in scale and resolution due to compute and memory constraints. We present a multi-GPU Gaussian splatting approach that scales reconstruction to higher resolutions and larger scenes while abstracting away the code complexity typically associated with distributing a model. To accomplish this, we propose a PyTorch backend that distributes the Gaussian parameters and splatting operators across GPUs via CUDA unified memory and NVLink. Because distribution occurs at the operator level, the model code requires no explicit cross-device communication. More broadly, the backend exposes multiple GPUs as an aggregate PyTorch device and supports other PyTorch operators. We demonstrate city-scale reconstructions with street-level detail consisting of over 1 billion Gaussian splats, more than 25 times as many as the current state of the art.
fVDB: A Deep-Learning Framework for Sparse, Large-Scale, and High-Performance Spatial Intelligence
Jul 01, 2024



We present fVDB, a novel GPU-optimized framework for deep learning on large-scale 3D data. fVDB provides a complete set of differentiable primitives to build deep learning architectures for common tasks in 3D learning such as convolution, pooling, attention, ray-tracing, meshing, etc. fVDB simultaneously provides a much larger feature set (primitives and operators) than established frameworks with no loss in efficiency: our operators match or exceed the performance of other frameworks with narrower scope. Furthermore, fVDB can process datasets with much larger footprint and spatial resolution than prior works, while providing a competitive memory footprint on small inputs. To achieve this combination of versatility and performance, fVDB relies on a single novel VDB index grid acceleration structure paired with several key innovations including GPU accelerated sparse grid construction, convolution using tensorcores, fast ray tracing kernels using a Hierarchical Digital Differential Analyzer algorithm (HDDA), and jagged tensors. Our framework is fully integrated with PyTorch enabling interoperability with existing pipelines, and we demonstrate its effectiveness on a number of representative tasks such as large-scale point-cloud segmentation, high resolution 3D generative modeling, unbounded scale Neural Radiance Fields, and large-scale point cloud reconstruction.
XCube ($\mathcal{X}^3$): Large-Scale 3D Generative Modeling using Sparse Voxel Hierarchies
Dec 06, 2023We present $\mathcal{X}^3$ (pronounced XCube), a novel generative model for high-resolution sparse 3D voxel grids with arbitrary attributes. Our model can generate millions of voxels with a finest effective resolution of up to $1024^3$ in a feed-forward fashion without time-consuming test-time optimization. To achieve this, we employ a hierarchical voxel latent diffusion model which generates progressively higher resolution grids in a coarse-to-fine manner using a custom framework built on the highly efficient VDB data structure. Apart from generating high-resolution objects, we demonstrate the effectiveness of XCube on large outdoor scenes at scales of 100m$\times$100m with a voxel size as small as 10cm. We observe clear qualitative and quantitative improvements over past approaches. In addition to unconditional generation, we show that our model can be used to solve a variety of tasks such as user-guided editing, scene completion from a single scan, and text-to-3D. More results and details can be found at https://research.nvidia.com/labs/toronto-ai/xcube/.
Near-realtime Facial Animation by Deep 3D Simulation Super-Resolution
May 05, 2023



We present a neural network-based simulation super-resolution framework that can efficiently and realistically enhance a facial performance produced by a low-cost, realtime physics-based simulation to a level of detail that closely approximates that of a reference-quality off-line simulator with much higher resolution (26x element count in our examples) and accurate physical modeling. Our approach is rooted in our ability to construct - via simulation - a training set of paired frames, from the low- and high-resolution simulators respectively, that are in semantic correspondence with each other. We use face animation as an exemplar of such a simulation domain, where creating this semantic congruence is achieved by simply dialing in the same muscle actuation controls and skeletal pose in the two simulators. Our proposed neural network super-resolution framework generalizes from this training set to unseen expressions, compensates for modeling discrepancies between the two simulations due to limited resolution or cost-cutting approximations in the real-time variant, and does not require any semantic descriptors or parameters to be provided as input, other than the result of the real-time simulation. We evaluate the efficacy of our pipeline on a variety of expressive performances and provide comparisons and ablation experiments for plausible variations and alternatives to our proposed scheme.
NeuralVDB: High-resolution Sparse Volume Representation using Hierarchical Neural Networks
Aug 08, 2022

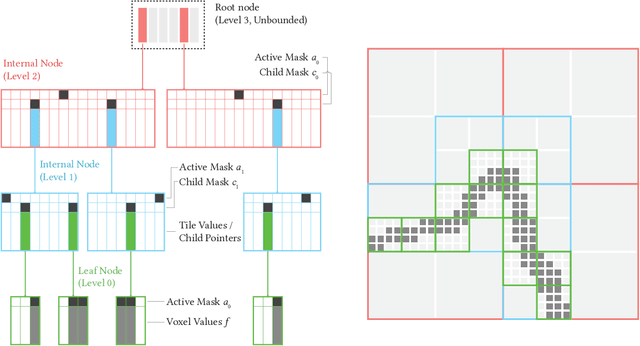
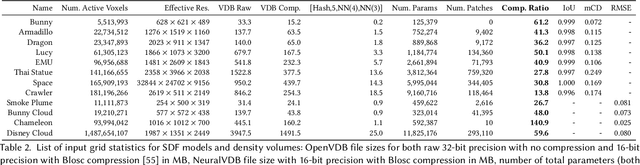
We introduce NeuralVDB, which improves on an existing industry standard for efficient storage of sparse volumetric data, denoted VDB, by leveraging recent advancements in machine learning. Our novel hybrid data structure can reduce the memory footprints of VDB volumes by orders of magnitude, while maintaining its flexibility and only incurring a small (user-controlled) compression errors. Specifically, NeuralVDB replaces the lower nodes of a shallow and wide VDB tree structure with multiple hierarchy neural networks that separately encode topology and value information by means of neural classifiers and regressors respectively. This approach has proven to maximize the compression ratio while maintaining the spatial adaptivity offered by the higher-level VDB data structure. For sparse signed distance fields and density volumes, we have observed compression ratios on the order of $10\times$ to more than $100\times$ from already compressed VDB inputs, with little to no visual artifacts. We also demonstrate how its application to animated sparse volumes can both accelerate training and generate temporally coherent neural networks.