 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling
Mar 05, 2026Attention, as a core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long-context applications. While FlashAttention-3 optimized attention for Hopper GPUs through asynchronous execution and warp specialization, it primarily targets the H100 architecture. The AI industry has rapidly transitioned to deploying Blackwell-based systems such as the B200 and GB200, which exhibit fundamentally different performance characteristics due to asymmetric hardware scaling: tensor core throughput doubles while other functional units (shared memory bandwidth, exponential units) scale more slowly or remain unchanged. We develop several techniques to address these shifting bottlenecks on Blackwell GPUs: (1) redesigned pipelines that exploit fully asynchronous MMA operations and larger tile sizes, (2) software-emulated exponential and conditional softmax rescaling that reduces non-matmul operations, and (3) leveraging tensor memory and the 2-CTA MMA mode to reduce shared memory traffic and atomic adds in the backward pass. We demonstrate that our method, FlashAttention-4, achieves up to 1.3$\times$ speedup over cuDNN 9.13 and 2.7$\times$ over Triton on B200 GPUs with BF16, reaching up to 1613 TFLOPs/s (71% utilization). Beyond algorithmic innovations, we implement FlashAttention-4 entirely in CuTe-DSL embedded in Python, achieving 20-30$\times$ faster compile times compared to traditional C++ template-based approaches while maintaining full expressivity.
Generalized Neighborhood Attention: Multi-dimensional Sparse Attention at the Speed of Light
Apr 23, 2025Many sparse attention mechanisms such as Neighborhood Attention have typically failed to consistently deliver speedup over the self attention baseline. This is largely due to the level of complexity in attention infrastructure, and the rapid evolution of AI hardware architecture. At the same time, many state-of-the-art foundational models, particularly in computer vision, are heavily bound by attention, and need reliable sparsity to escape the O(n^2) complexity. In this paper, we study a class of promising sparse attention mechanisms that focus on locality, and aim to develop a better analytical model of their performance improvements. We first introduce Generalized Neighborhood Attention (GNA), which can describe sliding window, strided sliding window, and blocked attention. We then consider possible design choices in implementing these approaches, and create a simulator that can provide much more realistic speedup upper bounds for any given setting. Finally, we implement GNA on top of a state-of-the-art fused multi-headed attention (FMHA) kernel designed for the NVIDIA Blackwell architecture in CUTLASS. Our implementation can fully realize the maximum speedup theoretically possible in many perfectly block-sparse cases, and achieves an effective utilization of 1.3 petaFLOPs/second in FP16. In addition, we plug various GNA configurations into off-the-shelf generative models, such as Cosmos-7B, HunyuanVideo, and FLUX, and show that it can deliver 28% to 46% end-to-end speedup on B200 without any fine-tuning. We will open source our simulator and Blackwell kernels directly through the NATTEN project.
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Jul 11, 2024


Attention, as a core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long-context applications. FlashAttention elaborated an approach to speed up attention on GPUs through minimizing memory reads/writes. However, it has yet to take advantage of new capabilities present in recent hardware, with FlashAttention-2 achieving only 35% utilization on the H100 GPU. We develop three main techniques to speed up attention on Hopper GPUs: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) block quantization and incoherent processing that leverages hardware support for FP8 low-precision. We demonstrate that our method, FlashAttention-3, achieves speedup on H100 GPUs by 1.5-2.0$\times$ with FP16 reaching up to 740 TFLOPs/s (75% utilization), and with FP8 reaching close to 1.2 PFLOPs/s. We validate that FP8 FlashAttention-3 achieves 2.6$\times$ lower numerical error than a baseline FP8 attention.
fVDB: A Deep-Learning Framework for Sparse, Large-Scale, and High-Performance Spatial Intelligence
Jul 01, 2024



We present fVDB, a novel GPU-optimized framework for deep learning on large-scale 3D data. fVDB provides a complete set of differentiable primitives to build deep learning architectures for common tasks in 3D learning such as convolution, pooling, attention, ray-tracing, meshing, etc. fVDB simultaneously provides a much larger feature set (primitives and operators) than established frameworks with no loss in efficiency: our operators match or exceed the performance of other frameworks with narrower scope. Furthermore, fVDB can process datasets with much larger footprint and spatial resolution than prior works, while providing a competitive memory footprint on small inputs. To achieve this combination of versatility and performance, fVDB relies on a single novel VDB index grid acceleration structure paired with several key innovations including GPU accelerated sparse grid construction, convolution using tensorcores, fast ray tracing kernels using a Hierarchical Digital Differential Analyzer algorithm (HDDA), and jagged tensors. Our framework is fully integrated with PyTorch enabling interoperability with existing pipelines, and we demonstrate its effectiveness on a number of representative tasks such as large-scale point-cloud segmentation, high resolution 3D generative modeling, unbounded scale Neural Radiance Fields, and large-scale point cloud reconstruction.
Conditioning Deep Generative Raw Audio Models for Structured Automatic Music
Jun 26, 2018
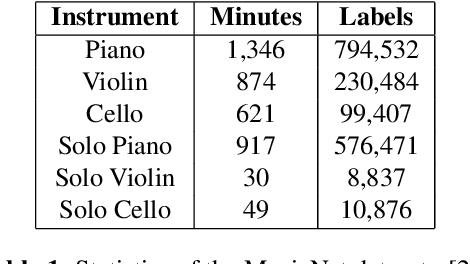
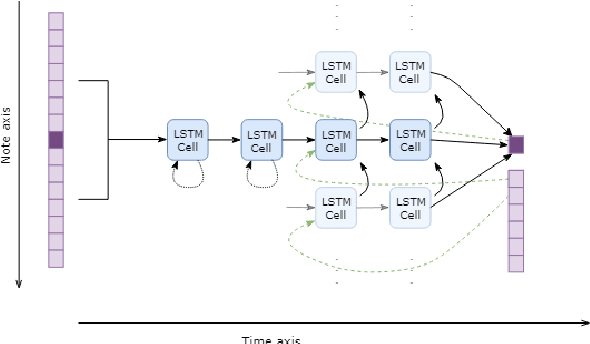
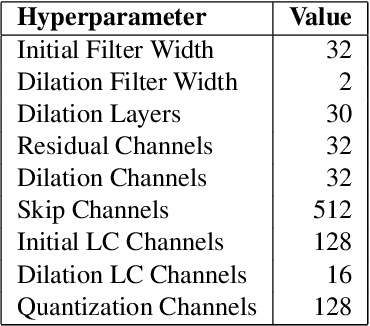
Existing automatic music generation approaches that feature deep learning can be broadly classified into two types: raw audio models and symbolic models. Symbolic models, which train and generate at the note level, are currently the more prevalent approach; these models can capture long-range dependencies of melodic structure, but fail to grasp the nuances and richness of raw audio generations. Raw audio models, such as DeepMind's WaveNet, train directly on sampled audio waveforms, allowing them to produce realistic-sounding, albeit unstructured music. In this paper, we propose an automatic music generation methodology combining both of these approaches to create structured, realistic-sounding compositions. We consider a Long Short Term Memory network to learn the melodic structure of different styles of music, and then use the unique symbolic generations from this model as a conditioning input to a WaveNet-based raw audio generator, creating a model for automatic, novel music. We then evaluate this approach by showcasing results of this work.