 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Jul 11, 2024

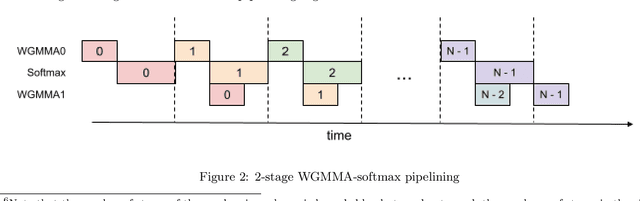

Attention, as a core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long-context applications. FlashAttention elaborated an approach to speed up attention on GPUs through minimizing memory reads/writes. However, it has yet to take advantage of new capabilities present in recent hardware, with FlashAttention-2 achieving only 35% utilization on the H100 GPU. We develop three main techniques to speed up attention on Hopper GPUs: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) block quantization and incoherent processing that leverages hardware support for FP8 low-precision. We demonstrate that our method, FlashAttention-3, achieves speedup on H100 GPUs by 1.5-2.0$\times$ with FP16 reaching up to 740 TFLOPs/s (75% utilization), and with FP8 reaching close to 1.2 PFLOPs/s. We validate that FP8 FlashAttention-3 achieves 2.6$\times$ lower numerical error than a baseline FP8 attention.
A Case Study in CUDA Kernel Fusion: Implementing FlashAttention-2 on NVIDIA Hopper Architecture using the CUTLASS Library
Dec 19, 2023We provide an optimized implementation of the forward pass of FlashAttention-2, a popular memory-aware scaled dot-product attention algorithm, as a custom fused CUDA kernel targeting NVIDIA Hopper architecture and written using the open-source CUTLASS library. In doing so, we explain the challenges and techniques involved in fusing online-softmax with back-to-back GEMM kernels, utilizing the Hopper-specific Tensor Memory Accelerator (TMA) and Warpgroup Matrix-Multiply-Accumulate (WGMMA) instructions, defining and transforming CUTLASS Layouts and Tensors, overlapping copy and GEMM operations, and choosing optimal tile sizes for the Q, K and V attention matrices while balancing the register pressure and shared memory utilization. In head-to-head benchmarks on a single H100 PCIe GPU for some common choices of hyperparameters, we observe 20-50% higher FLOPs/s over a version of FlashAttention-2 optimized for last-generation NVIDIA Ampere architecture.