 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe NeurIPS 2023 Machine Learning for Audio Workshop: Affective Audio Benchmarks and Novel Data
Mar 21, 2024

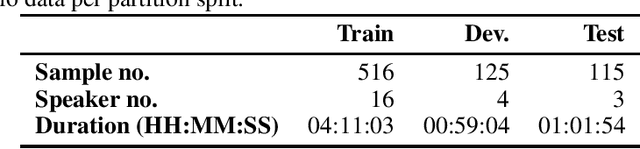

The NeurIPS 2023 Machine Learning for Audio Workshop brings together machine learning (ML) experts from various audio domains. There are several valuable audio-driven ML tasks, from speech emotion recognition to audio event detection, but the community is sparse compared to other ML areas, e.g., computer vision or natural language processing. A major limitation with audio is the available data; with audio being a time-dependent modality, high-quality data collection is time-consuming and costly, making it challenging for academic groups to apply their often state-of-the-art strategies to a larger, more generalizable dataset. In this short white paper, to encourage researchers with limited access to large-datasets, the organizers first outline several open-source datasets that are available to the community, and for the duration of the workshop are making several propriety datasets available. Namely, three vocal datasets, Hume-Prosody, Hume-VocalBurst, an acted emotional speech dataset Modulate-Sonata, and an in-game streamer dataset Modulate-Stream. We outline the current baselines on these datasets but encourage researchers from across audio to utilize them outside of the initial baseline tasks.
Deep Divergence Learning
May 06, 2020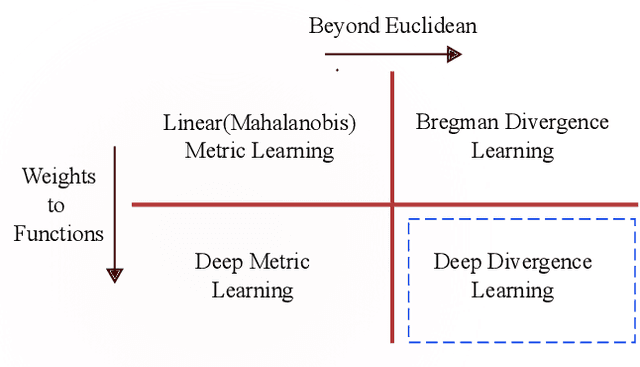

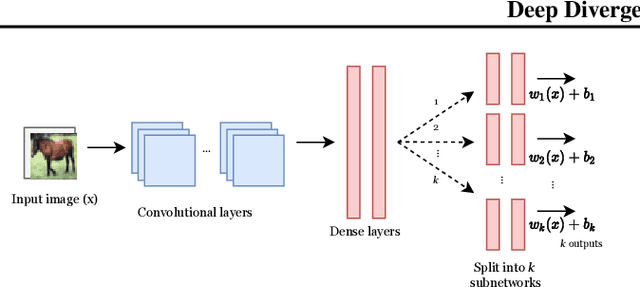
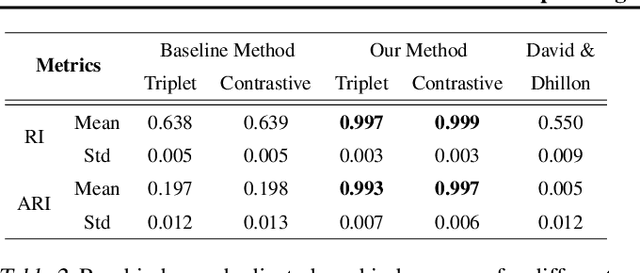
Classical linear metric learning methods have recently been extended along two distinct lines: deep metric learning methods for learning embeddings of the data using neural networks, and Bregman divergence learning approaches for extending learning Euclidean distances to more general divergence measures such as divergences over distributions. In this paper, we introduce deep Bregman divergences, which are based on learning and parameterizing functional Bregman divergences using neural networks, and which unify and extend these existing lines of work. We show in particular how deep metric learning formulations, kernel metric learning, Mahalanobis metric learning, and moment-matching functions for comparing distributions arise as special cases of these divergences in the symmetric setting. We then describe a deep learning framework for learning general functional Bregman divergences, and show in experiments that this method yields superior performance on benchmark datasets as compared to existing deep metric learning approaches. We also discuss novel applications, including a semi-supervised distributional clustering problem, and a new loss function for unsupervised data generation.
Conditioning Deep Generative Raw Audio Models for Structured Automatic Music
Jun 26, 2018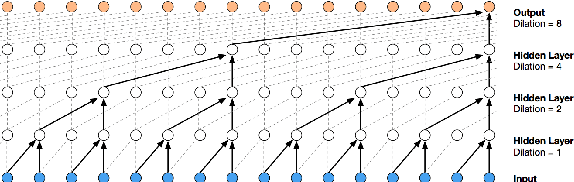
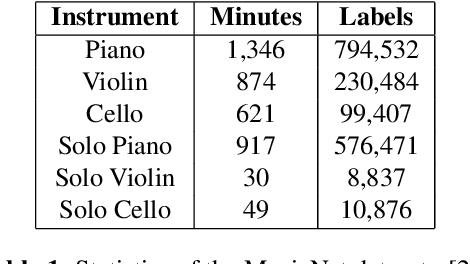
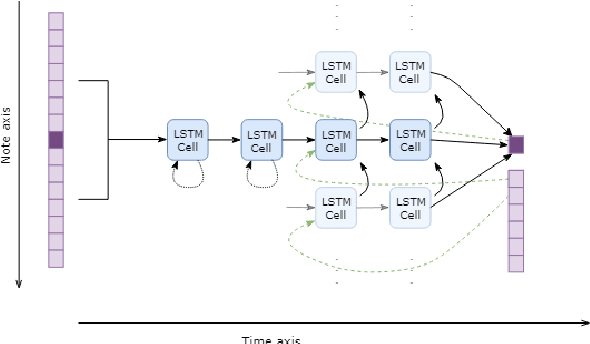
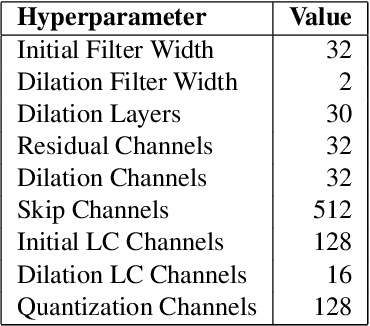
Existing automatic music generation approaches that feature deep learning can be broadly classified into two types: raw audio models and symbolic models. Symbolic models, which train and generate at the note level, are currently the more prevalent approach; these models can capture long-range dependencies of melodic structure, but fail to grasp the nuances and richness of raw audio generations. Raw audio models, such as DeepMind's WaveNet, train directly on sampled audio waveforms, allowing them to produce realistic-sounding, albeit unstructured music. In this paper, we propose an automatic music generation methodology combining both of these approaches to create structured, realistic-sounding compositions. We consider a Long Short Term Memory network to learn the melodic structure of different styles of music, and then use the unique symbolic generations from this model as a conditioning input to a WaveNet-based raw audio generator, creating a model for automatic, novel music. We then evaluate this approach by showcasing results of this work.