 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe NeurIPS 2023 Machine Learning for Audio Workshop: Affective Audio Benchmarks and Novel Data
Paper and Code


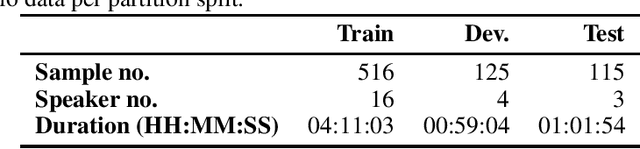

The NeurIPS 2023 Machine Learning for Audio Workshop brings together machine learning (ML) experts from various audio domains. There are several valuable audio-driven ML tasks, from speech emotion recognition to audio event detection, but the community is sparse compared to other ML areas, e.g., computer vision or natural language processing. A major limitation with audio is the available data; with audio being a time-dependent modality, high-quality data collection is time-consuming and costly, making it challenging for academic groups to apply their often state-of-the-art strategies to a larger, more generalizable dataset. In this short white paper, to encourage researchers with limited access to large-datasets, the organizers first outline several open-source datasets that are available to the community, and for the duration of the workshop are making several propriety datasets available. Namely, three vocal datasets, Hume-Prosody, Hume-VocalBurst, an acted emotional speech dataset Modulate-Sonata, and an in-game streamer dataset Modulate-Stream. We outline the current baselines on these datasets but encourage researchers from across audio to utilize them outside of the initial baseline tasks.