 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgefVDB: A Deep-Learning Framework for Sparse, Large-Scale, and High-Performance Spatial Intelligence
Jul 01, 2024



We present fVDB, a novel GPU-optimized framework for deep learning on large-scale 3D data. fVDB provides a complete set of differentiable primitives to build deep learning architectures for common tasks in 3D learning such as convolution, pooling, attention, ray-tracing, meshing, etc. fVDB simultaneously provides a much larger feature set (primitives and operators) than established frameworks with no loss in efficiency: our operators match or exceed the performance of other frameworks with narrower scope. Furthermore, fVDB can process datasets with much larger footprint and spatial resolution than prior works, while providing a competitive memory footprint on small inputs. To achieve this combination of versatility and performance, fVDB relies on a single novel VDB index grid acceleration structure paired with several key innovations including GPU accelerated sparse grid construction, convolution using tensorcores, fast ray tracing kernels using a Hierarchical Digital Differential Analyzer algorithm (HDDA), and jagged tensors. Our framework is fully integrated with PyTorch enabling interoperability with existing pipelines, and we demonstrate its effectiveness on a number of representative tasks such as large-scale point-cloud segmentation, high resolution 3D generative modeling, unbounded scale Neural Radiance Fields, and large-scale point cloud reconstruction.
Near-realtime Facial Animation by Deep 3D Simulation Super-Resolution
May 05, 2023



We present a neural network-based simulation super-resolution framework that can efficiently and realistically enhance a facial performance produced by a low-cost, realtime physics-based simulation to a level of detail that closely approximates that of a reference-quality off-line simulator with much higher resolution (26x element count in our examples) and accurate physical modeling. Our approach is rooted in our ability to construct - via simulation - a training set of paired frames, from the low- and high-resolution simulators respectively, that are in semantic correspondence with each other. We use face animation as an exemplar of such a simulation domain, where creating this semantic congruence is achieved by simply dialing in the same muscle actuation controls and skeletal pose in the two simulators. Our proposed neural network super-resolution framework generalizes from this training set to unseen expressions, compensates for modeling discrepancies between the two simulations due to limited resolution or cost-cutting approximations in the real-time variant, and does not require any semantic descriptors or parameters to be provided as input, other than the result of the real-time simulation. We evaluate the efficacy of our pipeline on a variety of expressive performances and provide comparisons and ablation experiments for plausible variations and alternatives to our proposed scheme.
Local Geometric Indexing of High Resolution Data for Facial Reconstruction from Sparse Markers
Mar 01, 2019



When considering sparse motion capture marker data, one typically struggles to balance its overfitting via a high dimensional blendshape system versus underfitting caused by smoothness constraints. With the current trend towards using more and more data, our aim is not to fit the motion capture markers with a parameterized (blendshape) model or to smoothly interpolate a surface through the marker positions, but rather to find an instance in the high resolution dataset that contains local geometry to fit each marker. Just as is true for typical machine learning applications, this approach benefits from a plethora of data, and thus we also consider augmenting the dataset via specially designed physical simulations that target the high resolution dataset such that the simulation output lies on the same so-called manifold as the data targeted.
High-Quality Face Capture Using Anatomical Muscles
Dec 06, 2018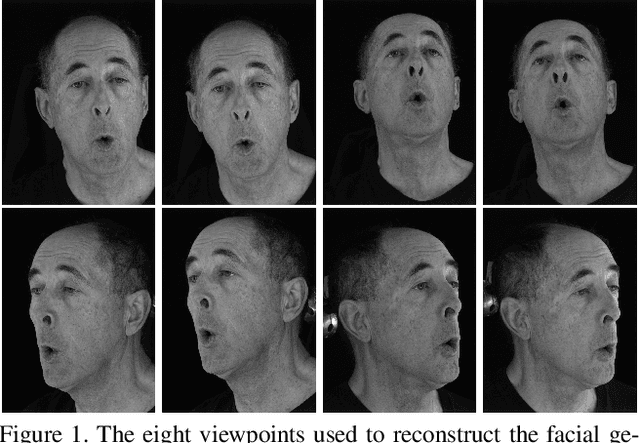
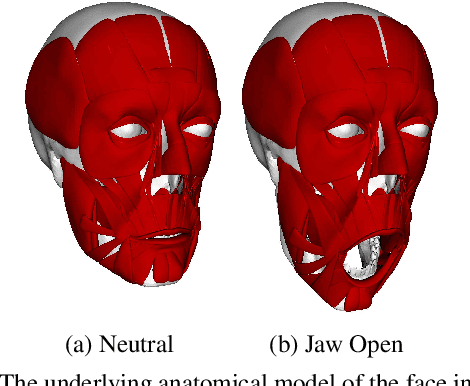
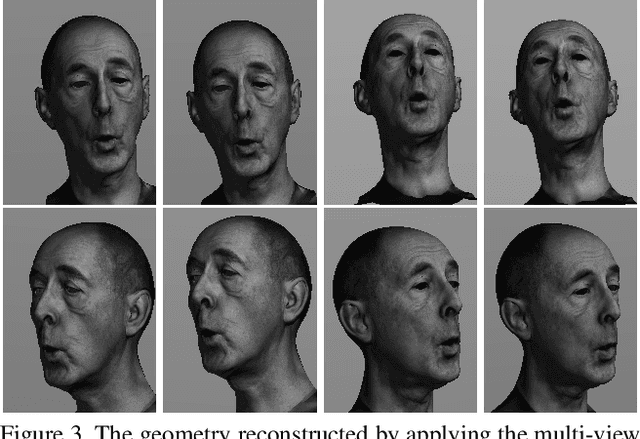
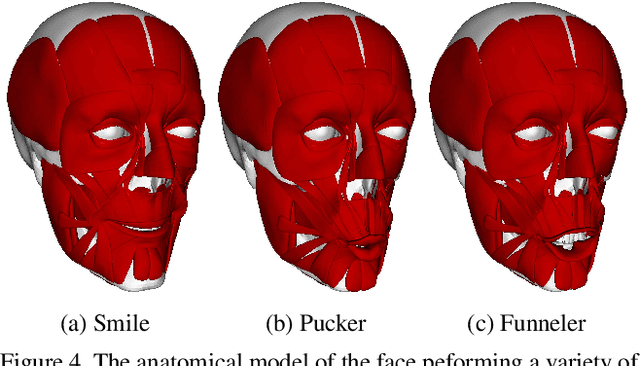
Muscle-based systems have the potential to provide both anatomical accuracy and semantic interpretability as compared to blendshape models; however, a lack of expressivity and differentiability has limited their impact. Thus, we propose modifying a recently developed rather expressive muscle-based system in order to make it fully-differentiable; in fact, our proposed modifications allow this physically robust and anatomically accurate muscle model to conveniently be driven by an underlying blendshape basis. Our formulation is intuitive, natural, as well as monolithically and fully coupled such that one can differentiate the model from end to end, which makes it viable for both optimization and learning-based approaches for a variety of applications. We illustrate this with a number of examples including both shape matching of three-dimensional geometry as as well as the automatic determination of a three-dimensional facial pose from a single two-dimensional RGB image without using markers or depth information.
Inferring 3D Articulated Models for Box Packaging Robot
Jun 23, 2011
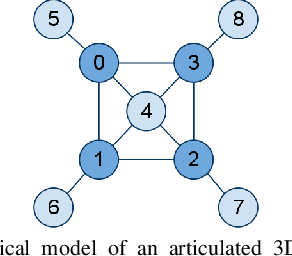


Given a point cloud, we consider inferring kinematic models of 3D articulated objects such as boxes for the purpose of manipulating them. While previous work has shown how to extract a planar kinematic model (often represented as a linear chain), such planar models do not apply to 3D objects that are composed of segments often linked to the other segments in cyclic configurations. We present an approach for building a model that captures the relation between the input point cloud features and the object segment as well as the relation between the neighboring object segments. We use a conditional random field that allows us to model the dependencies between different segments of the object. We test our approach on inferring the kinematic structure from partial and noisy point cloud data for a wide variety of boxes including cake boxes, pizza boxes, and cardboard cartons of several sizes. The inferred structure enables our robot to successfully close these boxes by manipulating the flaps.