 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElecTwit: A Framework for Studying Persuasion in Multi-Agent Social Systems
Jan 02, 2026This paper introduces ElecTwit, a simulation framework designed to study persuasion within multi-agent systems, specifically emulating the interactions on social media platforms during a political election. By grounding our experiments in a realistic environment, we aimed to overcome the limitations of game-based simulations often used in prior research. We observed the comprehensive use of 25 specific persuasion techniques across most tested LLMs, encompassing a wider range than previously reported. The variations in technique usage and overall persuasion output between models highlight how different model architectures and training can impact the dynamics in realistic social simulations. Additionally, we observed unique phenomena such as "kernel of truth" messages and spontaneous developments with an "ink" obsession, where agents collectively demanded written proof. Our study provides a foundation for evaluating persuasive LLM agents in real-world contexts, ensuring alignment and preventing dangerous outcomes.
Deep Energies for Estimating Three-Dimensional Facial Pose and Expression
Dec 07, 2018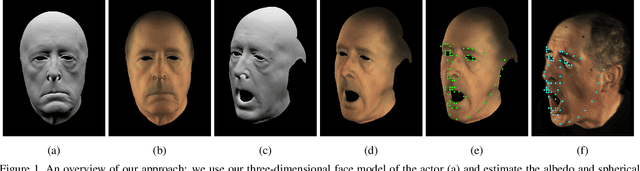


While much progress has been made in capturing high-quality facial performances using motion capture markers and shape-from-shading, high-end systems typically also rely on rotoscope curves hand-drawn on the image. These curves are subjective and difficult to draw consistently; moreover, ad-hoc procedural methods are required for generating matching rotoscope curves on synthetic renders embedded in the optimization used to determine three-dimensional facial pose and expression. We propose an alternative approach whereby these curves and other keypoints are detected automatically on both the image and the synthetic renders using trained neural networks, eliminating artist subjectivity and the ad-hoc procedures meant to mimic it. More generally, we propose using machine learning networks to implicitly define deep energies which when minimized using classical optimization techniques lead to three-dimensional facial pose and expression estimation.
Improved Search Strategies for Determining Facial Expression
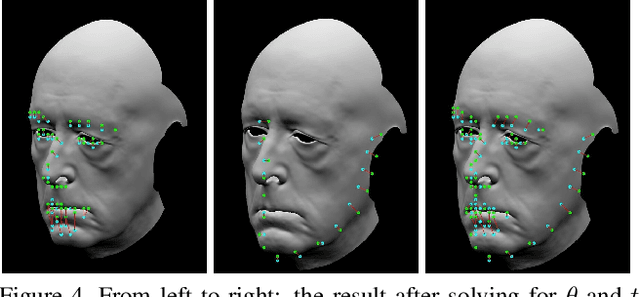
Dec 07, 2018
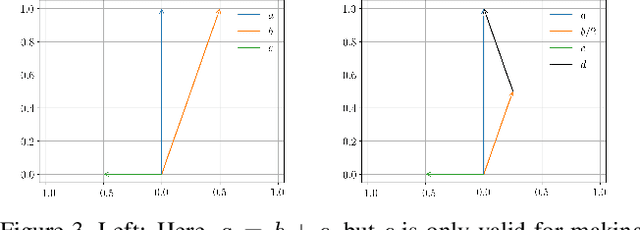
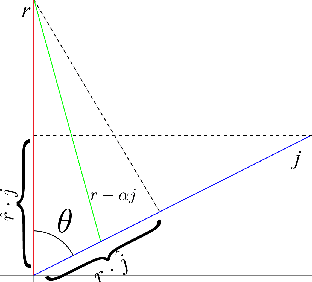
It is well known that popular optimization techniques can lead to overfitting or even a lack of convergence altogether; thus, practitioners often utilize ad hoc regularization terms added to the energy functional. When carefully crafted, these regularizations can produce compelling results. However, regularization changes both the energy landscape and the solution to the optimization problem, which can result in underfitting. Surprisingly, many practitioners both add regularization and claim that their model lacks the expressivity to fit the data. Motivated by a geometric interpretation of the linearized search space, we propose an approach that ameliorates overfitting without the need for regularization terms that restrict the expressiveness of the underlying model. We illustrate the efficacy of our approach on minimization problems related to three-dimensional facial expression estimation where overfitting clouds semantic understanding and regularization may lead to underfitting that misses or misinterprets subtle expressions.
High-Quality Face Capture Using Anatomical Muscles
Dec 06, 2018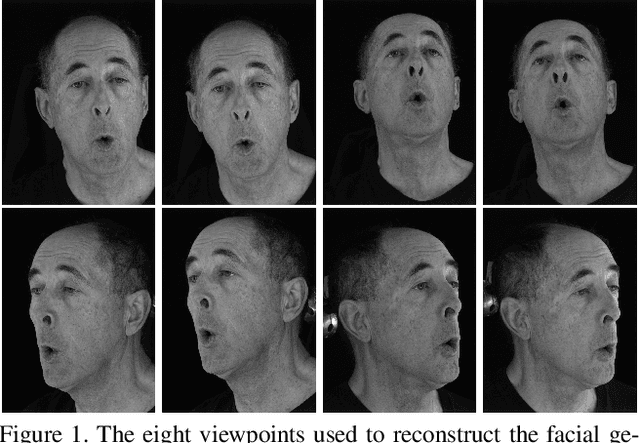
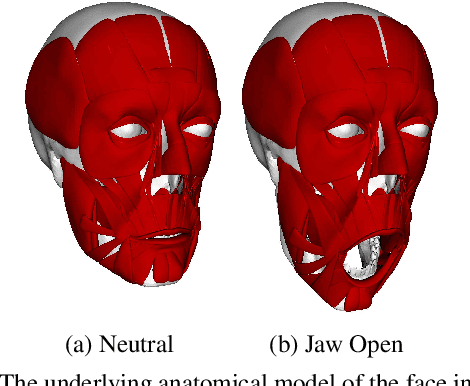
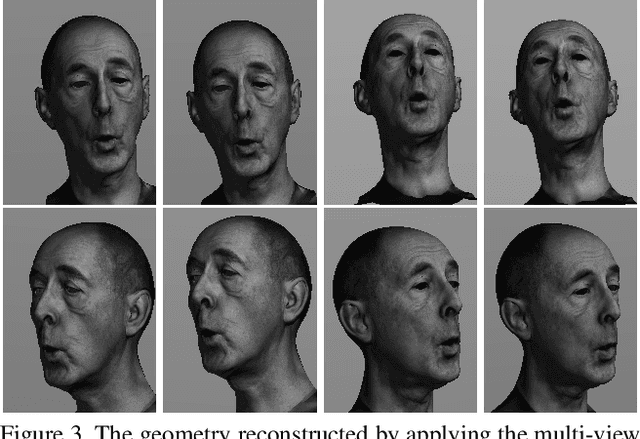
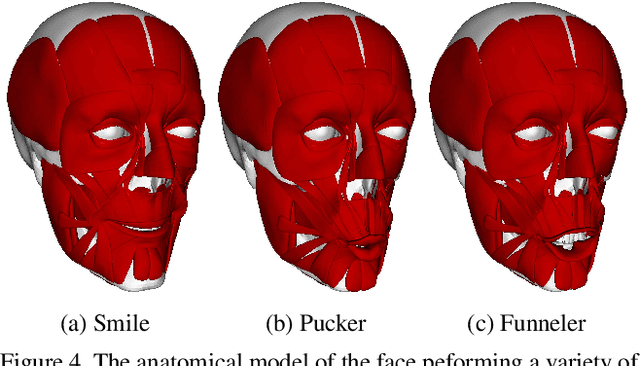
Muscle-based systems have the potential to provide both anatomical accuracy and semantic interpretability as compared to blendshape models; however, a lack of expressivity and differentiability has limited their impact. Thus, we propose modifying a recently developed rather expressive muscle-based system in order to make it fully-differentiable; in fact, our proposed modifications allow this physically robust and anatomically accurate muscle model to conveniently be driven by an underlying blendshape basis. Our formulation is intuitive, natural, as well as monolithically and fully coupled such that one can differentiate the model from end to end, which makes it viable for both optimization and learning-based approaches for a variety of applications. We illustrate this with a number of examples including both shape matching of three-dimensional geometry as as well as the automatic determination of a three-dimensional facial pose from a single two-dimensional RGB image without using markers or depth information.