 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-to-Image Translation Framework Embedded with Rotation Symmetry Priors
Apr 14, 2026Image-to-image translation (I2I) is a fundamental task in computer vision, focused on mapping an input image from a source domain to a corresponding image in a target domain while preserving domain-invariant features and adapting domain-specific attributes. Despite the remarkable success of deep learning-based I2I approaches, the lack of paired data and unsupervised learning framework still hinder their effectiveness. In this work, we address the challenge by incorporating transformation symmetry priors into image-to-image translation networks. Specifically, we introduce rotation group equivariant convolutions to achieve rotation equivariant I2I framework, a novel contribution, to the best of our knowledge, along this research direction. This design ensures the preservation of rotation symmetry, one of the most intrinsic and domain-invariant properties of natural and scientific images, throughout the network. Furthermore, we conduct a systematic study on image symmetry priors on real dataset and propose a novel transformation learnable equivariant convolutions (TL-Conv) that adaptively learns transformation groups, enhancing symmetry preservation across diverse datasets. We also provide a theoretical analysis of the equivariance error of TL-Conv, proving that it maintains exact equivariance in continuous domains and provide a bound for the error in discrete cases. Through extensive experiments across a range of I2I tasks, we validate the effectiveness and superior performance of our approach, highlighting the potential of equivariant networks in enhancing generation quality and its broad applicability. Our code is available at https://github.com/tanfy929/Equivariant-I2I
M-ArtAgent: Evidence-Based Multimodal Agent for Implicit Art Influence Discovery
Apr 08, 2026Implicit artistic influence, although visually plausible, is often undocumented and thus poses a historically constrained attribution problem: resemblance is necessary but not sufficient evidence. Most prior systems reduce influence discovery to embedding similarity or label-driven graph completion, while recent multimodal large language models (LLMs) remain vulnerable to temporal inconsistency and unverified attributions. This paper introduces M-ArtAgent, an evidence-based multimodal agent that reframes implicit influence discovery as probabilistic adjudication. It follows a four-phase protocol consisting of Investigation, Corroboration, Falsification, and Verdict governed by a Reasoning and Acting (ReAct)-style controller that assembles verifiable evidence chains from images and biographies, enforces art-historical axioms, and subjects each hypothesis to adversarial falsification via a prompt-isolated critic. Two theory-grounded operators, StyleComparator for Wolfflin formal analysis and ConceptRetriever for ICONCLASS-based iconographic grounding, ensure that intermediate claims are formally auditable. On the balanced WikiArt Influence Benchmark-100 (WIB-100) of 100 artists and 2,000 directed pairs, M-ArtAgent achieves 83.7% positive-class F1, 0.666 Matthews correlation coefficient (MCC), and 0.910 area under the receiver operating characteristic curve (ROC-AUC), with leakage-control and robustness checks confirming that the gains persist when explicit influence phrases are masked. By coupling multimodal perception with domain-constrained falsification, M-ArtAgent demonstrates that implicit influence analysis benefits from historically grounded adjudication rather than pattern matching alone.
A Unified Hyper-GAN Model for Unpaired Multi-contrast MR Image Translation
Jul 26, 2021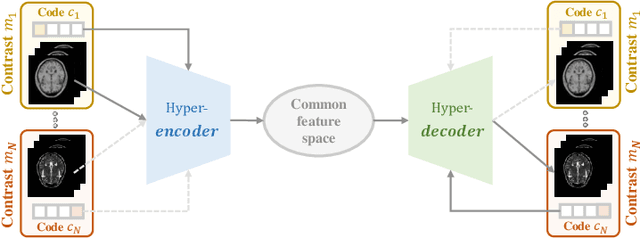
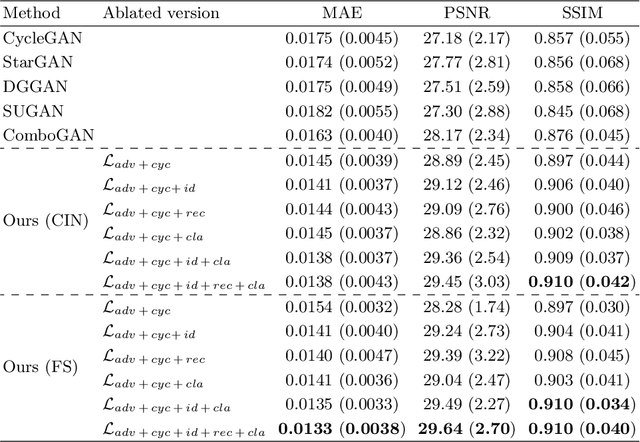
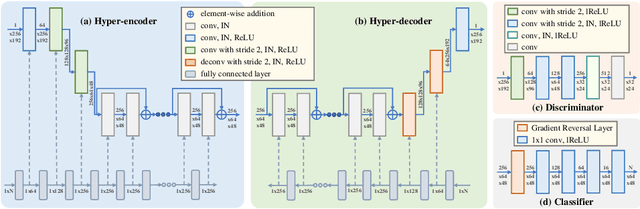
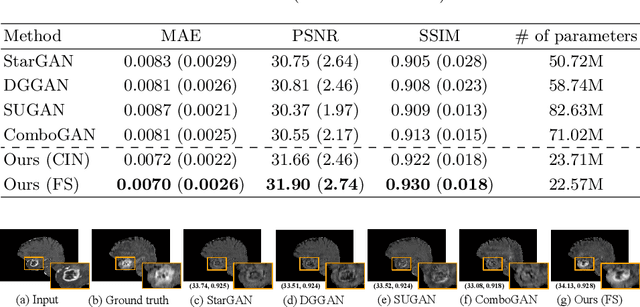
Cross-contrast image translation is an important task for completing missing contrasts in clinical diagnosis. However, most existing methods learn separate translator for each pair of contrasts, which is inefficient due to many possible contrast pairs in real scenarios. In this work, we propose a unified Hyper-GAN model for effectively and efficiently translating between different contrast pairs. Hyper-GAN consists of a pair of hyper-encoder and hyper-decoder to first map from the source contrast to a common feature space, and then further map to the target contrast image. To facilitate the translation between different contrast pairs, contrast-modulators are designed to tune the hyper-encoder and hyper-decoder adaptive to different contrasts. We also design a common space loss to enforce that multi-contrast images of a subject share a common feature space, implicitly modeling the shared underlying anatomical structures. Experiments on two datasets of IXI and BraTS 2019 show that our Hyper-GAN achieves state-of-the-art results in both accuracy and efficiency, e.g., improving more than 1.47 and 1.09 dB in PSNR on two datasets with less than half the amount of parameters.
Unpaired Brain MR-to-CT Synthesis using a Structure-Constrained CycleGAN
Sep 12, 2018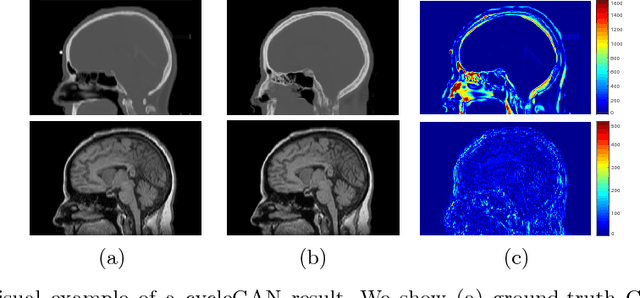
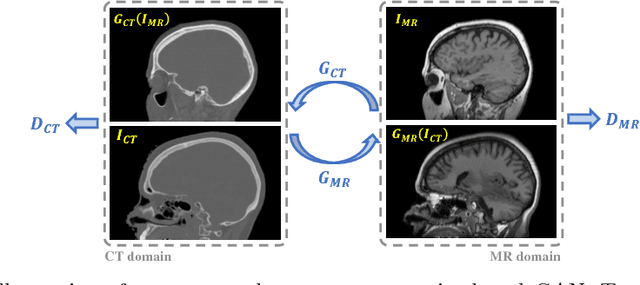
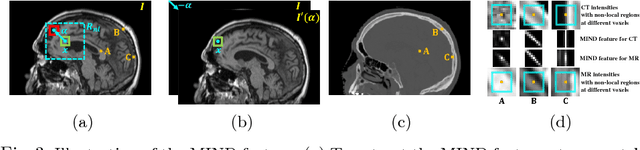
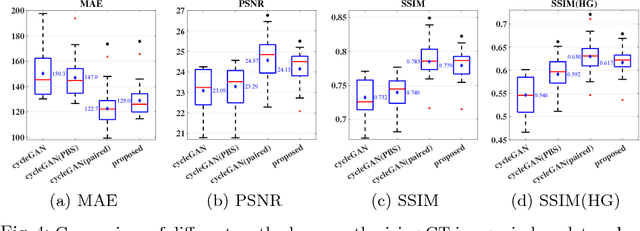
The cycleGAN is becoming an influential method in medical image synthesis. However, due to a lack of direct constraints between input and synthetic images, the cycleGAN cannot guarantee structural consistency between these two images, and such consistency is of extreme importance in medical imaging. To overcome this, we propose a structure-constrained cycleGAN for brain MR-to-CT synthesis using unpaired data that defines an extra structure-consistency loss based on the modality independent neighborhood descriptor to constrain structural consistency. Additionally, we use a position-based selection strategy for selecting training images instead of a completely random selection scheme. Experimental results on synthesizing CT images from brain MR images demonstrate that our method is better than the conventional cycleGAN and approximates the cycleGAN trained with paired data.
Neural Multi-Atlas Label Fusion: Application to Cardiac MR Images
Aug 01, 2018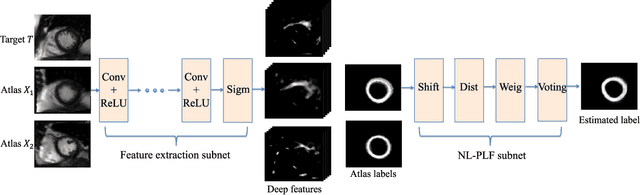


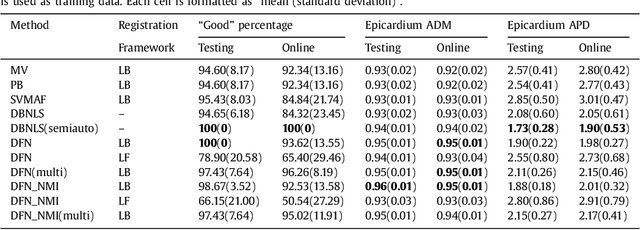
Multi-atlas segmentation approach is one of the most widely-used image segmentation techniques in biomedical applications. There are two major challenges in this category of methods, i.e., atlas selection and label fusion. In this paper, we propose a novel multi-atlas segmentation method that formulates multi-atlas segmentation in a deep learning framework for better solving these challenges. The proposed method, dubbed deep fusion net (DFN), is a deep architecture that integrates a feature extraction subnet and a non-local patch-based label fusion (NL-PLF) subnet in a single network. The network parameters are learned by end-to-end training for automatically learning deep features that enable optimal performance in a NL-PLF framework. The learned deep features are further utilized in defining a similarity measure for atlas selection. By evaluating on two public cardiac MR datasets of SATA-13 and LV-09 for left ventricle segmentation, our approach achieved 0.833 in averaged Dice metric (ADM) on SATA-13 dataset and 0.95 in ADM for epicardium segmentation on LV-09 dataset, comparing favorably with the other automatic left ventricle segmentation methods. We also tested our approach on Cardiac Atlas Project (CAP) testing set of MICCAI 2013 SATA Segmentation Challenge, and our method achieved 0.815 in ADM, ranking highest at the time of writing.
* Medical Image Analysis
Inferring 3D Articulated Models for Box Packaging Robot
Jun 23, 2011
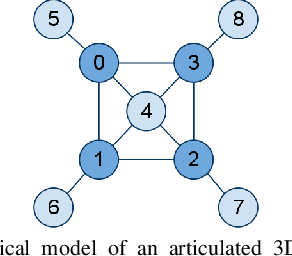


Given a point cloud, we consider inferring kinematic models of 3D articulated objects such as boxes for the purpose of manipulating them. While previous work has shown how to extract a planar kinematic model (often represented as a linear chain), such planar models do not apply to 3D objects that are composed of segments often linked to the other segments in cyclic configurations. We present an approach for building a model that captures the relation between the input point cloud features and the object segment as well as the relation between the neighboring object segments. We use a conditional random field that allows us to model the dependencies between different segments of the object. We test our approach on inferring the kinematic structure from partial and noisy point cloud data for a wide variety of boxes including cake boxes, pizza boxes, and cardboard cartons of several sizes. The inferred structure enables our robot to successfully close these boxes by manipulating the flaps.