 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Net-Like Spiking Neural Networks for Single Image Dehazing
Dec 30, 2025Image dehazing is a critical challenge in computer vision, essential for enhancing image clarity in hazy conditions. Traditional methods often rely on atmospheric scattering models, while recent deep learning techniques, specifically Convolutional Neural Networks (CNNs) and Transformers, have improved performance by effectively analyzing image features. However, CNNs struggle with long-range dependencies, and Transformers demand significant computational resources. To address these limitations, we propose DehazeSNN, an innovative architecture that integrates a U-Net-like design with Spiking Neural Networks (SNNs). DehazeSNN captures multi-scale image features while efficiently managing local and long-range dependencies. The introduction of the Orthogonal Leaky-Integrate-and-Fire Block (OLIFBlock) enhances cross-channel communication, resulting in superior dehazing performance with reduced computational burden. Our extensive experiments show that DehazeSNN is highly competitive to state-of-the-art methods on benchmark datasets, delivering high-quality haze-free images with a smaller model size and less multiply-accumulate operations. The proposed dehazing method is publicly available at https://github.com/HaoranLiu507/DehazeSNN.
* 9 pages, 4 figures. Accepted at IJCNN 2025 (Rome, Italy). To appear in IEEE/IJCNN 2025 proceedings
Towards High-Fidelity Text-Guided 3D Face Generation and Manipulation Using only Images
Aug 31, 2023
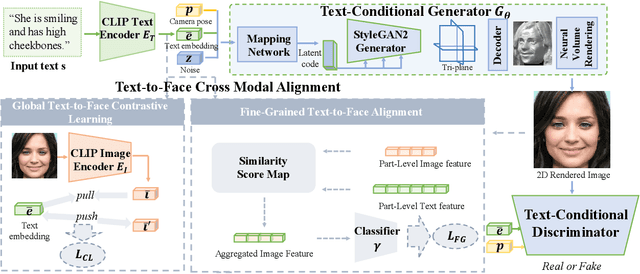
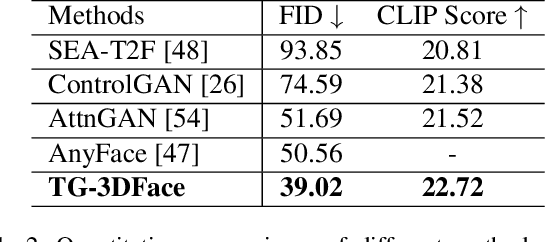

Generating 3D faces from textual descriptions has a multitude of applications, such as gaming, movie, and robotics. Recent progresses have demonstrated the success of unconditional 3D face generation and text-to-3D shape generation. However, due to the limited text-3D face data pairs, text-driven 3D face generation remains an open problem. In this paper, we propose a text-guided 3D faces generation method, refer as TG-3DFace, for generating realistic 3D faces using text guidance. Specifically, we adopt an unconditional 3D face generation framework and equip it with text conditions, which learns the text-guided 3D face generation with only text-2D face data. On top of that, we propose two text-to-face cross-modal alignment techniques, including the global contrastive learning and the fine-grained alignment module, to facilitate high semantic consistency between generated 3D faces and input texts. Besides, we present directional classifier guidance during the inference process, which encourages creativity for out-of-domain generations. Compared to the existing methods, TG-3DFace creates more realistic and aesthetically pleasing 3D faces, boosting 9% multi-view consistency (MVIC) over Latent3D. The rendered face images generated by TG-3DFace achieve higher FID and CLIP score than text-to-2D face/image generation models, demonstrating our superiority in generating realistic and semantic-consistent textures.
Reconstructing A Large Scale 3D Face Dataset for Deep 3D Face Identification
Oct 16, 2020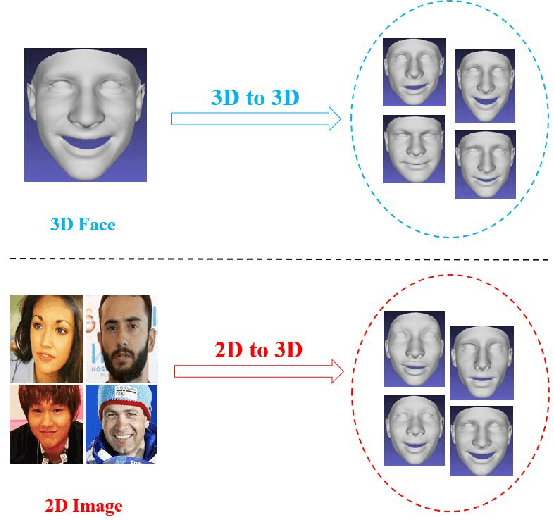
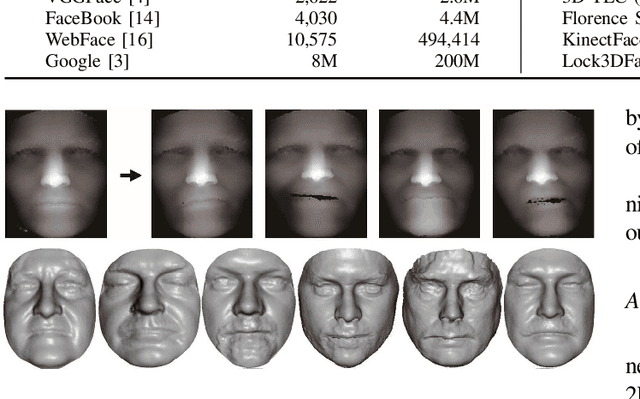


Deep learning methods have brought many breakthroughs to computer vision, especially in 2D face recognition. However, the bottleneck of deep learning based 3D face recognition is that it is difficult to collect millions of 3D faces, whether for industry or academia. In view of this situation, there are many methods to generate more 3D faces from existing 3D faces through 3D face data augmentation, which are used to train deep 3D face recognition models. However, to the best of our knowledge, there is no method to generate 3D faces from 2D face images for training deep 3D face recognition models. This letter focuses on the role of reconstructed 3D facial surfaces in 3D face identification and proposes a framework of 2D-aided deep 3D face identification. In particular, we propose to reconstruct millions of 3D face scans from a large scale 2D face database (i.e.VGGFace2), using a deep learning based 3D face reconstruction method (i.e.ExpNet). Then, we adopt a two-phase training approach: In the first phase, we use millions of face images to pre-train the deep convolutional neural network (DCNN), and in the second phase, we use normal component images (NCI) of reconstructed 3D face scans to train the DCNN. Extensive experimental results illustrate that the proposed approach can greatly improve the rank-1 score of 3D face identification on the FRGC v2.0, the Bosphorus, and the BU-3DFE 3D face databases, compared to the model trained by 2D face images. Finally, our proposed approach achieves state-of-the-art rank-1 scores on the FRGC v2.0 (97.6%), Bosphorus (98.4%), and BU-3DFE (98.8%) databases. The experimental results show that the reconstructed 3D facial surfaces are useful and our 2D-aided deep 3D face identification framework is meaningful, facing the scarcity of 3D faces.
Learning Spectral Transform Network on 3D Surface for Non-rigid Shape Analysis
Oct 21, 2018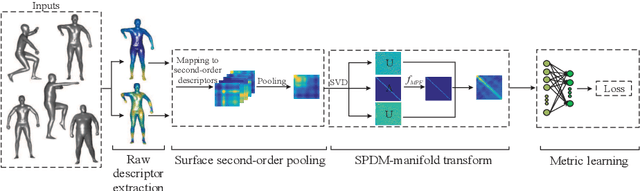
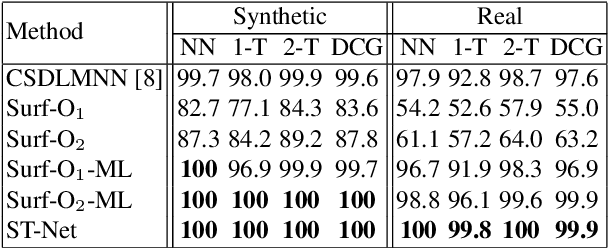

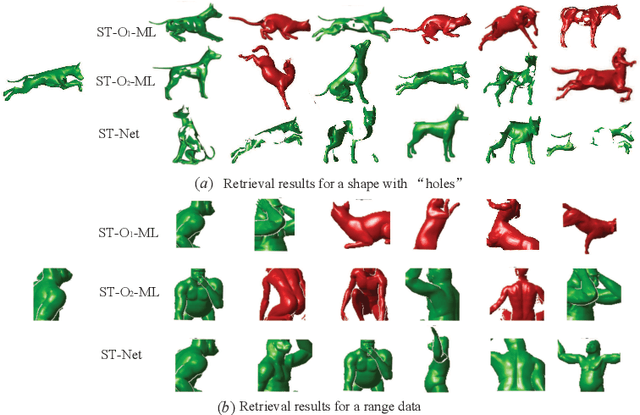
Designing a network on 3D surface for non-rigid shape analysis is a challenging task. In this work, we propose a novel spectral transform network on 3D surface to learn shape descriptors. The proposed network architecture consists of four stages: raw descriptor extraction, surface second-order pooling, mixture of power function-based spectral transform, and metric learning. The proposed network is simple and shallow. Quantitative experiments on challenging benchmarks show its effectiveness for non-rigid shape retrieval and classification, e.g., it achieved the highest accuracies on SHREC14, 15 datasets as well as the Range subset of SHREC17 dataset.
Discovering Influential Factors in Variational Autoencoder
Sep 06, 2018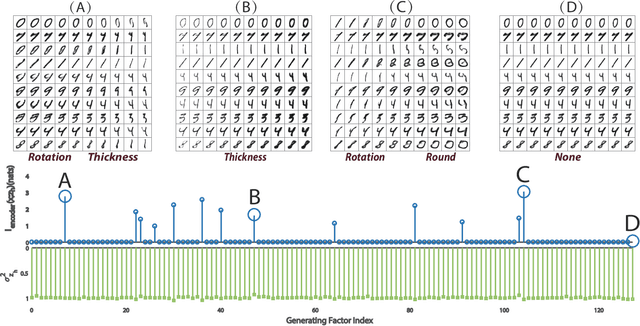

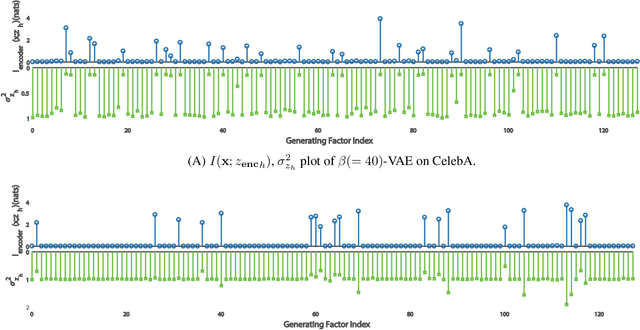
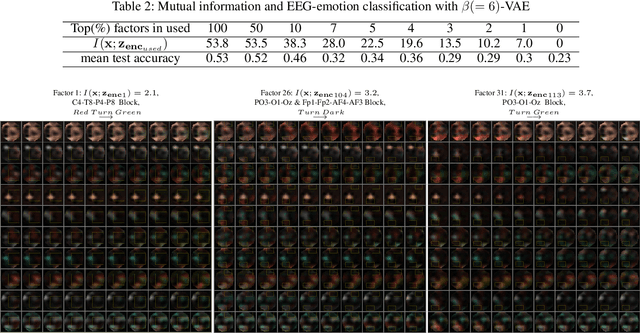
In the field of machine learning, it is still a critical issue to identify and supervise the learned representation without manually intervention or intuition assistance to extract useful knowledge or serve for the latter tasks in machine learning. In this work, we focus on supervising the influential factors extracted by the variational autoencoder(VAE). The VAE is proposed to learn independent low dimension representation while facing the problem that sometimes pre-set factors are ignored. We argue that the mutual information of the input and each learned factor of the representation plays a necessary indicator. We find the VAE objective inclines to induce mutual information sparsity in factor dimension over the data intrinsic dimension and results in some non-influential factors whose function on data reconstruction could be ignored. We show mutual information also influences the lower bound of VAE's reconstruction error and latter classification task. To make such indicator applicable, we design an algorithm on calculating the mutual information for VAE and prove its consistency. Experimental results on Mnist, CelebA and Deap datasets show that mutual information can help determine influential factors, of which some are interpretable and can be used to further generation and classification tasks, and help discover the variant that connects with emotion on Deap dataset.
Neural Multi-Atlas Label Fusion: Application to Cardiac MR Images
Aug 01, 2018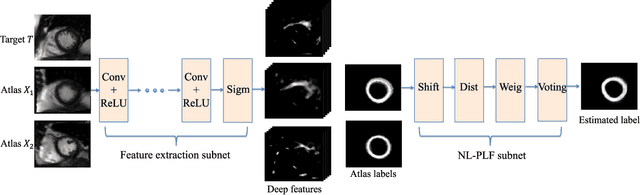


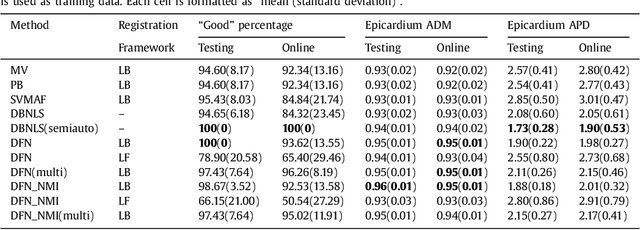
Multi-atlas segmentation approach is one of the most widely-used image segmentation techniques in biomedical applications. There are two major challenges in this category of methods, i.e., atlas selection and label fusion. In this paper, we propose a novel multi-atlas segmentation method that formulates multi-atlas segmentation in a deep learning framework for better solving these challenges. The proposed method, dubbed deep fusion net (DFN), is a deep architecture that integrates a feature extraction subnet and a non-local patch-based label fusion (NL-PLF) subnet in a single network. The network parameters are learned by end-to-end training for automatically learning deep features that enable optimal performance in a NL-PLF framework. The learned deep features are further utilized in defining a similarity measure for atlas selection. By evaluating on two public cardiac MR datasets of SATA-13 and LV-09 for left ventricle segmentation, our approach achieved 0.833 in averaged Dice metric (ADM) on SATA-13 dataset and 0.95 in ADM for epicardium segmentation on LV-09 dataset, comparing favorably with the other automatic left ventricle segmentation methods. We also tested our approach on Cardiac Atlas Project (CAP) testing set of MICCAI 2013 SATA Segmentation Challenge, and our method achieved 0.815 in ADM, ranking highest at the time of writing.
* Medical Image Analysis
Accurate Facial Parts Localization and Deep Learning for 3D Facial Expression Recognition
Mar 04, 2018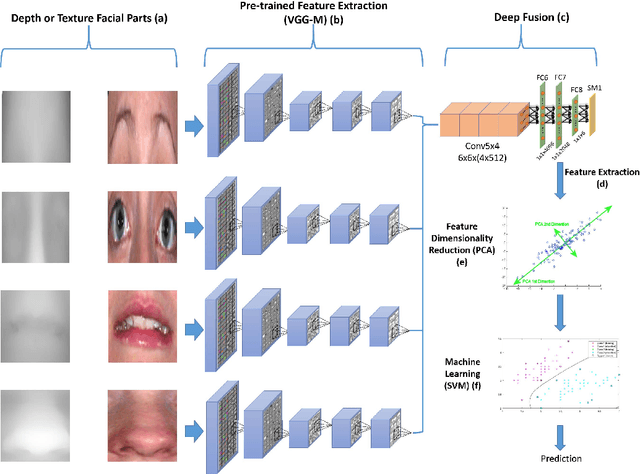

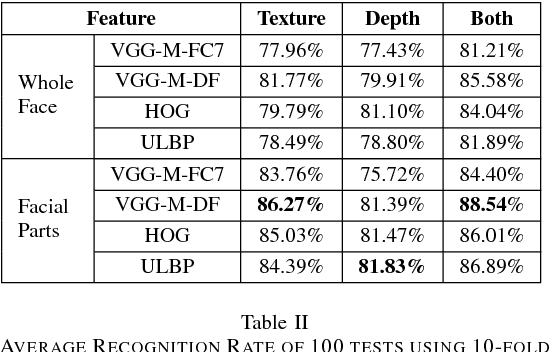
Meaningful facial parts can convey key cues for both facial action unit detection and expression prediction. Textured 3D face scan can provide both detailed 3D geometric shape and 2D texture appearance cues of the face which are beneficial for Facial Expression Recognition (FER). However, accurate facial parts extraction as well as their fusion are challenging tasks. In this paper, a novel system for 3D FER is designed based on accurate facial parts extraction and deep feature fusion of facial parts. In particular, each textured 3D face scan is firstly represented as a 2D texture map and a depth map with one-to-one dense correspondence. Then, the facial parts of both texture map and depth map are extracted using a novel 4-stage process consists of facial landmark localization, facial rotation correction, facial resizing, facial parts bounding box extraction and post-processing procedures. Finally, deep fusion Convolutional Neural Networks (CNNs) features of all facial parts are learned from both texture maps and depth maps, respectively and nonlinear SVMs are used for expression prediction. Experiments are conducted on the BU-3DFE database, demonstrating the effectiveness of combing different facial parts, texture and depth cues and reporting the state-of-the-art results in comparison with all existing methods under the same setting.
ADMM-Net: A Deep Learning Approach for Compressive Sensing MRI
May 19, 2017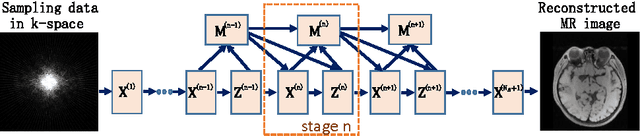

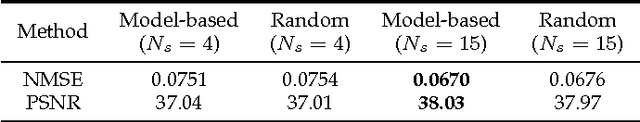
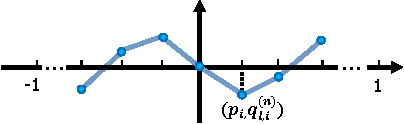
Compressive sensing (CS) is an effective approach for fast Magnetic Resonance Imaging (MRI). It aims at reconstructing MR images from a small number of under-sampled data in k-space, and accelerating the data acquisition in MRI. To improve the current MRI system in reconstruction accuracy and speed, in this paper, we propose two novel deep architectures, dubbed ADMM-Nets in basic and generalized versions. ADMM-Nets are defined over data flow graphs, which are derived from the iterative procedures in Alternating Direction Method of Multipliers (ADMM) algorithm for optimizing a general CS-based MRI model. They take the sampled k-space data as inputs and output reconstructed MR images. Moreover, we extend our network to cope with complex-valued MR images. In the training phase, all parameters of the nets, e.g., transforms, shrinkage functions, etc., are discriminatively trained end-to-end. In the testing phase, they have computational overhead similar to ADMM algorithm but use optimized parameters learned from the data for CS-based reconstruction task. We investigate different configurations in network structures and conduct extensive experiments on MR image reconstruction under different sampling rates. Due to the combination of the advantages in model-based approach and deep learning approach, the ADMM-Nets achieve state-of-the-art reconstruction accuracies with fast computational speed.
Deep Representation of Facial Geometric and Photometric Attributes for Automatic 3D Facial Expression Recognition
Nov 10, 2015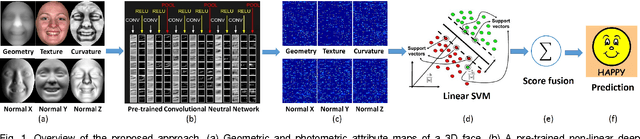
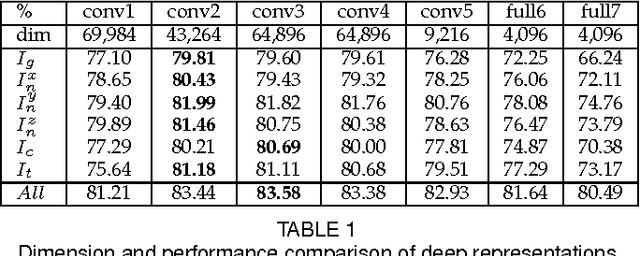
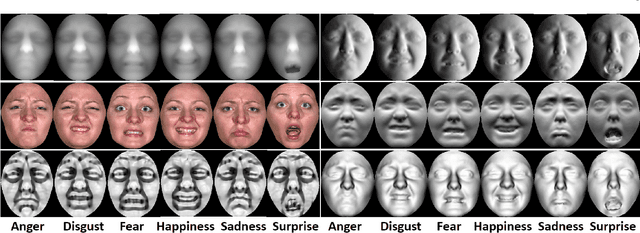
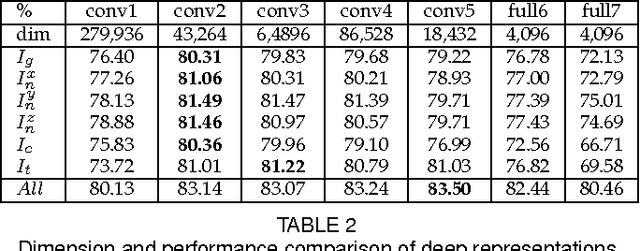
In this paper, we present a novel approach to automatic 3D Facial Expression Recognition (FER) based on deep representation of facial 3D geometric and 2D photometric attributes. A 3D face is firstly represented by its geometric and photometric attributes, including the geometry map, normal maps, normalized curvature map and texture map. These maps are then fed into a pre-trained deep convolutional neural network to generate the deep representation. Then the facial expression prediction is simplyachieved by training linear SVMs over the deep representation for different maps and fusing these SVM scores. The visualizations show that the deep representation provides a complete and highly discriminative coding scheme for 3D faces. Comprehensive experiments on the BU-3DFE database demonstrate that the proposed deep representation can outperform the widely used hand-crafted descriptors (i.e., LBP, SIFT, HOG, Gabor) and the state-of-art approaches under the same experimental protocols.