 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Influential Factors in Variational Autoencoder
Paper and Code
Sep 06, 2018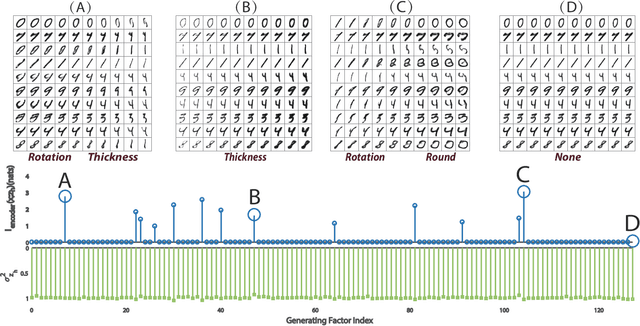

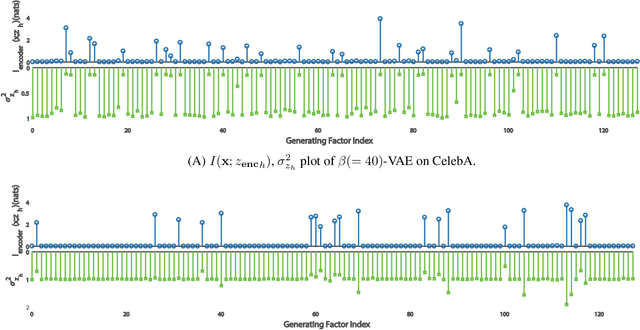
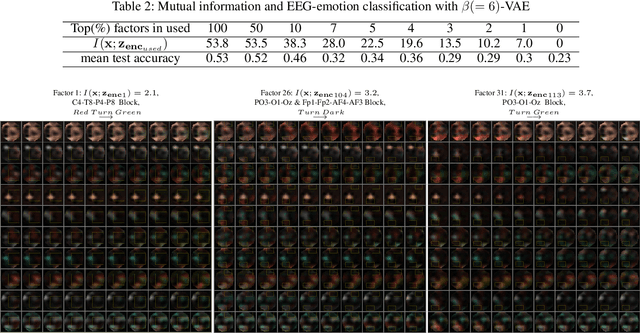
In the field of machine learning, it is still a critical issue to identify and supervise the learned representation without manually intervention or intuition assistance to extract useful knowledge or serve for the latter tasks in machine learning. In this work, we focus on supervising the influential factors extracted by the variational autoencoder(VAE). The VAE is proposed to learn independent low dimension representation while facing the problem that sometimes pre-set factors are ignored. We argue that the mutual information of the input and each learned factor of the representation plays a necessary indicator. We find the VAE objective inclines to induce mutual information sparsity in factor dimension over the data intrinsic dimension and results in some non-influential factors whose function on data reconstruction could be ignored. We show mutual information also influences the lower bound of VAE's reconstruction error and latter classification task. To make such indicator applicable, we design an algorithm on calculating the mutual information for VAE and prove its consistency. Experimental results on Mnist, CelebA and Deap datasets show that mutual information can help determine influential factors, of which some are interpretable and can be used to further generation and classification tasks, and help discover the variant that connects with emotion on Deap dataset.