 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEG-DBNet: A Dual-Branch Network for Temporal-Spectral Decoding in Motor-Imagery Brain-Computer Interfaces
May 30, 2024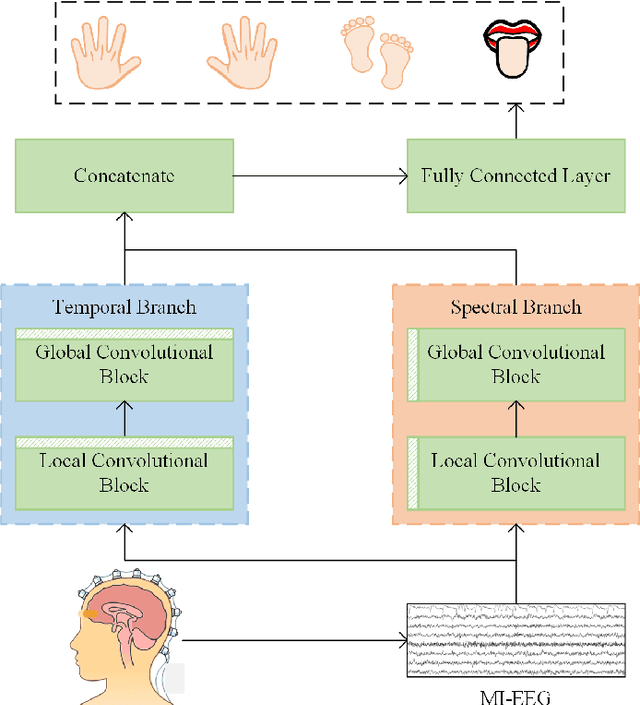
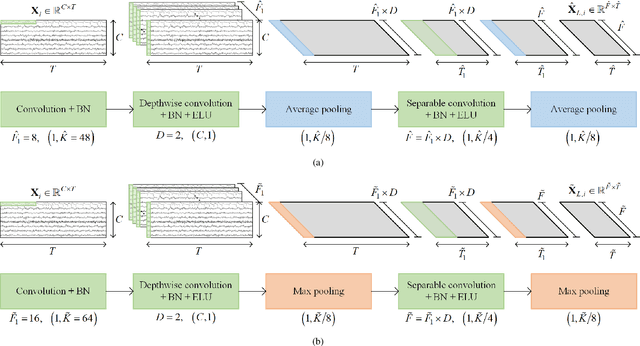
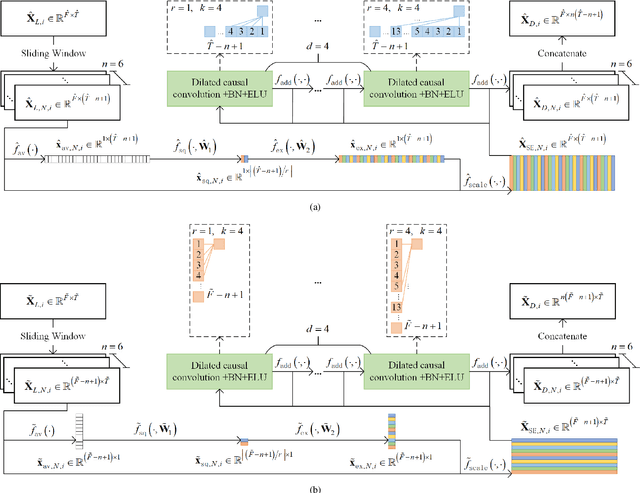

Motor imagery electroencephalogram (EEG)-based brain-computer interfaces (BCIs) offer significant advantages for individuals with restricted limb mobility. However, challenges such as low signal-to-noise ratio and limited spatial resolution impede accurate feature extraction from EEG signals, thereby affecting the classification accuracy of different actions. To address these challenges, this study proposes an end-to-end dual-branch network (EEG-DBNet) that decodes the temporal and spectral sequences of EEG signals in parallel through two distinct network branches. Each branch comprises a local convolutional block and a global convolutional block. The local convolutional block transforms the source signal from the temporal-spatial domain to the temporal-spectral domain. By varying the number of filters and convolution kernel sizes, the local convolutional blocks in different branches adjust the length of their respective dimension sequences. Different types of pooling layers are then employed to emphasize the features of various dimension sequences, setting the stage for subsequent global feature extraction. The global convolution block splits and reconstructs the feature of the signal sequence processed by the local convolution block in the same branch and further extracts features through the dilated causal convolutional neural networks. Finally, the outputs from the two branches are concatenated, and signal classification is completed via a fully connected layer. Our proposed method achieves classification accuracies of 85.84% and 91.60% on the BCI Competition 4-2a and BCI Competition 4-2b datasets, respectively, surpassing existing state-of-the-art models. The source code is available at https://github.com/xicheng105/EEG-DBNet.
PracticalDG: Perturbation Distillation on Vision-Language Models for Hybrid Domain Generalization
Apr 13, 2024



Domain Generalization (DG) aims to resolve distribution shifts between source and target domains, and current DG methods are default to the setting that data from source and target domains share identical categories. Nevertheless, there exists unseen classes from target domains in practical scenarios. To address this issue, Open Set Domain Generalization (OSDG) has emerged and several methods have been exclusively proposed. However, most existing methods adopt complex architectures with slight improvement compared with DG methods. Recently, vision-language models (VLMs) have been introduced in DG following the fine-tuning paradigm, but consume huge training overhead with large vision models. Therefore, in this paper, we innovate to transfer knowledge from VLMs to lightweight vision models and improve the robustness by introducing Perturbation Distillation (PD) from three perspectives, including Score, Class and Instance (SCI), named SCI-PD. Moreover, previous methods are oriented by the benchmarks with identical and fixed splits, ignoring the divergence between source domains. These methods are revealed to suffer from sharp performance decay with our proposed new benchmark Hybrid Domain Generalization (HDG) and a novel metric $H^{2}$-CV, which construct various splits to comprehensively assess the robustness of algorithms. Extensive experiments demonstrate that our method outperforms state-of-the-art algorithms on multiple datasets, especially improving the robustness when confronting data scarcity.
Word for Person: Zero-shot Composed Person Retrieval
Nov 25, 2023



Searching for specific person has great security value and social benefits, and it often involves a combination of visual and textual information. Conventional person retrieval methods, whether image-based or text-based, usually fall short in effectively harnessing both types of information, leading to the loss of accuracy. In this paper, a whole new task called Composed Person Retrieval (CPR) is proposed to jointly utilize both image and text information for target person retrieval. However, the supervised CPR must depend on very costly manual annotation dataset, while there are currently no available resources. To mitigate this issue, we firstly introduce the Zero-shot Composed Person Retrieval (ZS-CPR), which leverages existing domain-related data to resolve the CPR problem without reliance on expensive annotations. Secondly, to learn ZS-CPR model, we propose a two-stage learning framework, Word4Per, where a lightweight Textual Inversion Network (TINet) and a text-based person retrieval model based on fine-tuned Contrastive Language-Image Pre-training (CLIP) network are learned without utilizing any CPR data. Thirdly, a finely annotated Image-Text Composed Person Retrieval dataset (ITCPR) is built as the benchmark to assess the performance of the proposed Word4Per framework. Extensive experiments under both Rank-1 and mAP demonstrate the effectiveness of Word4Per for the ZS-CPR task, surpassing the comparative methods by over 10%. The code and ITCPR dataset will be publicly available at https://github.com/Delong-liu-bupt/Word4Per.
Lightweight Facial Attractiveness Prediction Using Dual Label Distribution
Dec 04, 2022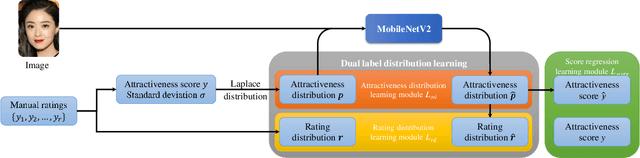
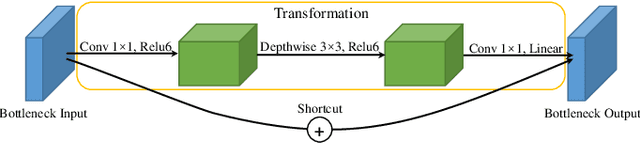
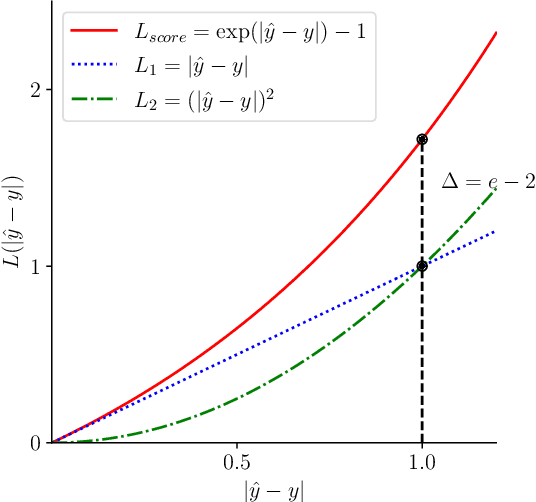
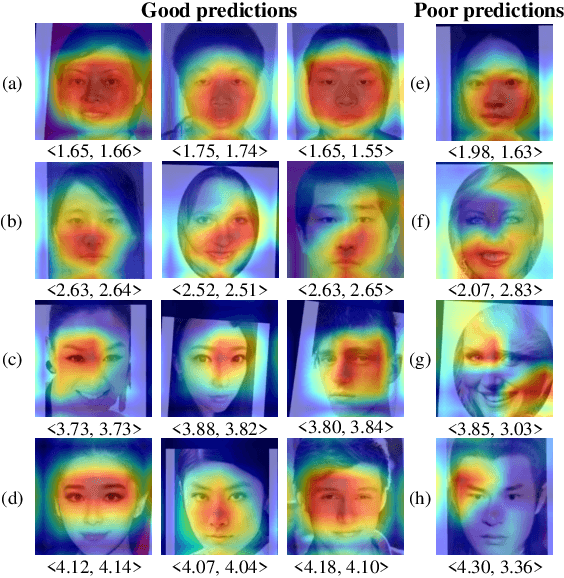
Facial attractiveness prediction (FAP) aims to assess the facial attractiveness automatically based on human aesthetic perception. Previous methods using deep convolutional neural networks have boosted the performance, but their giant models lead to a deficiency in flexibility. Besides, most of them fail to take full advantage of the dataset. In this paper, we present a novel end-to-end FAP approach integrating dual label distribution and lightweight design. To make the best use of the dataset, the manual ratings, attractiveness score, and standard deviation are aggregated explicitly to construct a dual label distribution, including the attractiveness distribution and the rating distribution. Such distributions, as well as the attractiveness score, are optimized under a joint learning framework based on the label distribution learning (LDL) paradigm. As for the lightweight design, the data processing is simplified to minimum, and MobileNetV2 is selected as our backbone. Extensive experiments are conducted on two benchmark datasets, where our approach achieves promising results and succeeds in striking a balance between performance and efficiency. Ablation studies demonstrate that our delicately designed learning modules are indispensable and correlated. Additionally, the visualization indicates that our approach is capable of perceiving facial attractiveness and capturing attractive facial regions to facilitate semantic predictions.
Medical Image Segmentation Using Deep Learning: A Survey
Sep 28, 2020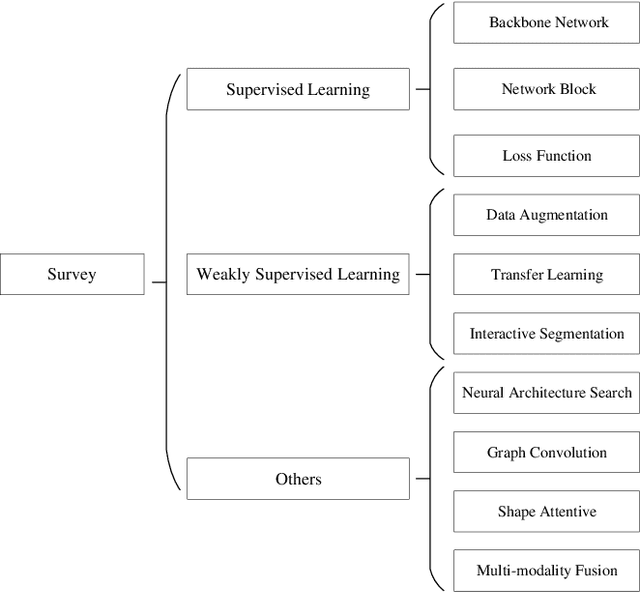
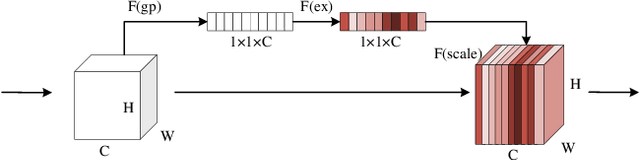
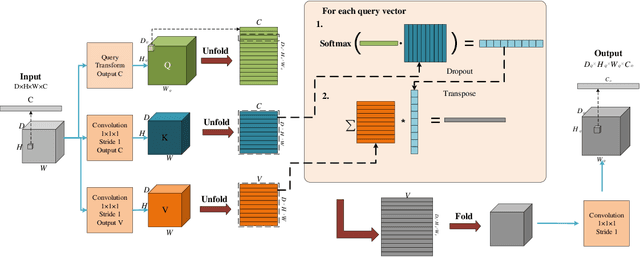
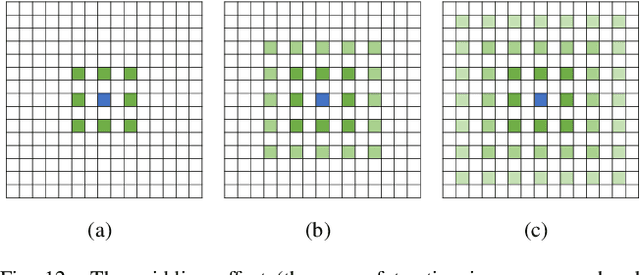
Deep learning has been widely used for medical image segmentation and a large number of papers has been presented recording the success of deep learning in the field. In this paper, we present a comprehensive thematic survey on medical image segmentation using deep learning techniques. This paper makes two original contributions. Firstly, compared to traditional surveys that directly divide literatures of deep learning on medical image segmentation into many groups and introduce literatures in detail for each group, we classify currently popular literatures according to a multi-level structure from coarse to fine. Secondly, this paper focuses on supervised and weakly supervised learning approaches, without including unsupervised approaches since they have been introduced in many old surveys and they are not popular currently. For supervised learning approaches, we analyze literatures in three aspects: the selection of backbone networks, the design of network blocks, and the improvement of loss functions. For weakly supervised learning approaches, we investigate literature according to data augmentation, transfer learning, and interactive segmentation, separately. Compared to existing surveys, this survey classifies the literatures very differently from before and is more convenient for readers to understand the relevant rationale and will guide them to think of appropriate improvements in medical image segmentation based on deep learning approaches.
Adaptive Morphological Reconstruction for Seeded Image Segmentation
Apr 08, 2019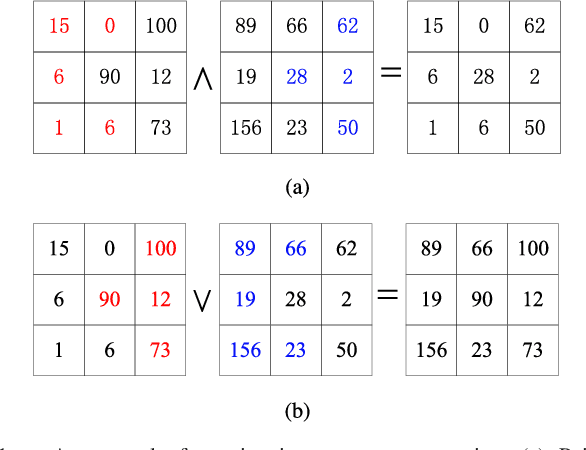
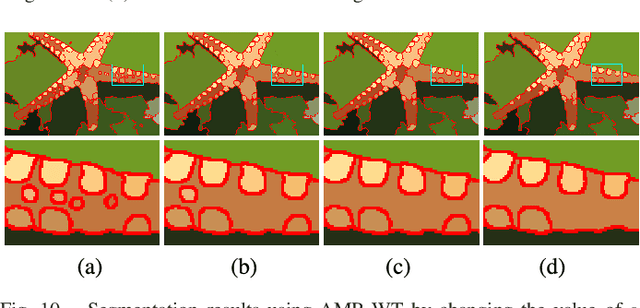
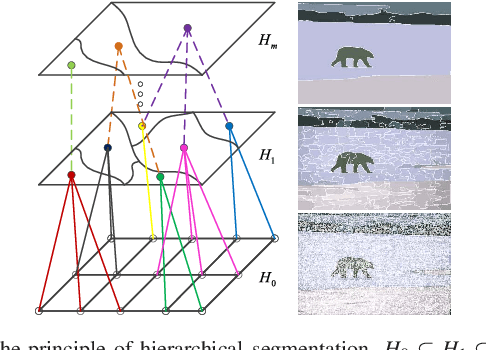

Morphological reconstruction (MR) is often employed by seeded image segmentation algorithms such as watershed transform and power watershed as it is able to filter seeds (regional minima) to reduce over-segmentation. However, MR might mistakenly filter meaningful seeds that are required for generating accurate segmentation and it is also sensitive to the scale because a single-scale structuring element is employed. In this paper, a novel adaptive morphological reconstruction (AMR) operation is proposed that has three advantages. Firstly, AMR can adaptively filter useless seeds while preserving meaningful ones. Secondly, AMR is insensitive to the scale of structuring elements because multiscale structuring elements are employed. Finally, AMR has two attractive properties: monotonic increasingness and convergence that help seeded segmentation algorithms to achieve a hierarchical segmentation. Experiments clearly demonstrate that AMR is useful for improving algorithms of seeded image segmentation and seed-based spectral segmentation. Compared to several state-of-the-art algorithms, the proposed algorithms provide better segmentation results requiring less computing time. Source code is available at https://github.com/SUST-reynole/AMR.
Discovering Influential Factors in Variational Autoencoder
Sep 06, 2018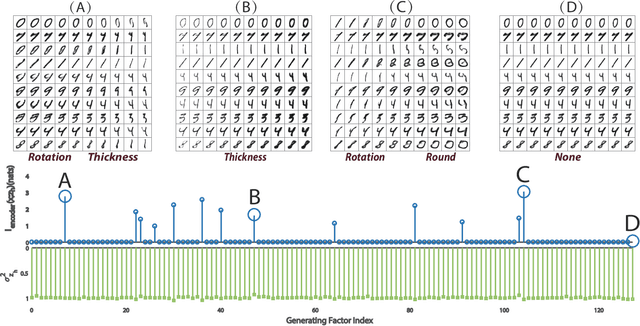

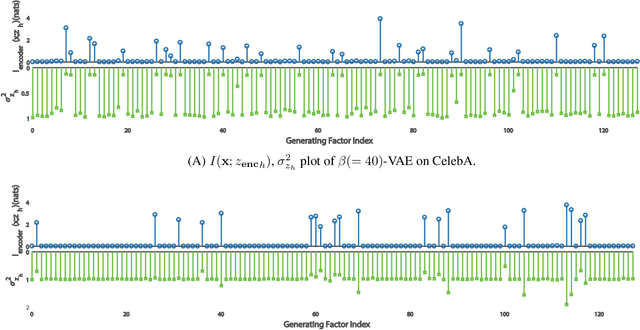
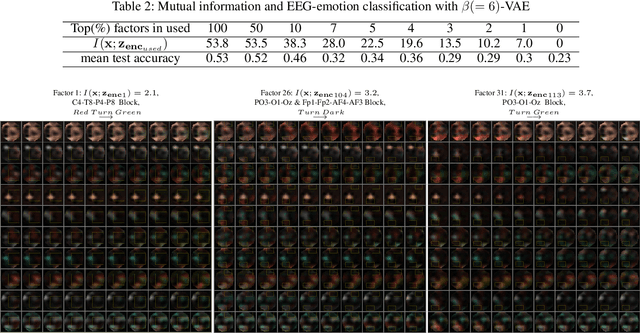
In the field of machine learning, it is still a critical issue to identify and supervise the learned representation without manually intervention or intuition assistance to extract useful knowledge or serve for the latter tasks in machine learning. In this work, we focus on supervising the influential factors extracted by the variational autoencoder(VAE). The VAE is proposed to learn independent low dimension representation while facing the problem that sometimes pre-set factors are ignored. We argue that the mutual information of the input and each learned factor of the representation plays a necessary indicator. We find the VAE objective inclines to induce mutual information sparsity in factor dimension over the data intrinsic dimension and results in some non-influential factors whose function on data reconstruction could be ignored. We show mutual information also influences the lower bound of VAE's reconstruction error and latter classification task. To make such indicator applicable, we design an algorithm on calculating the mutual information for VAE and prove its consistency. Experimental results on Mnist, CelebA and Deap datasets show that mutual information can help determine influential factors, of which some are interpretable and can be used to further generation and classification tasks, and help discover the variant that connects with emotion on Deap dataset.
Accurate Facial Parts Localization and Deep Learning for 3D Facial Expression Recognition
Mar 04, 2018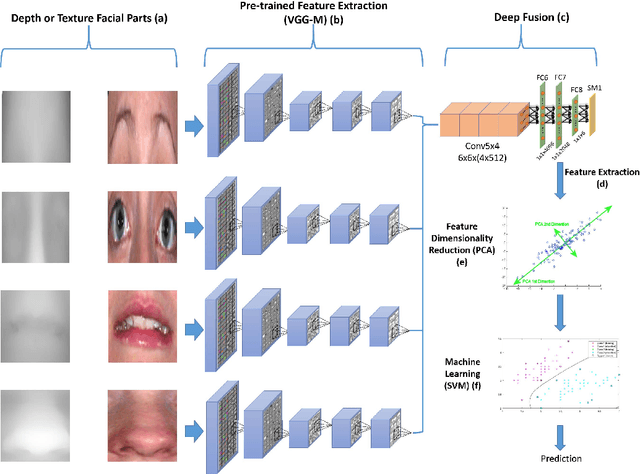

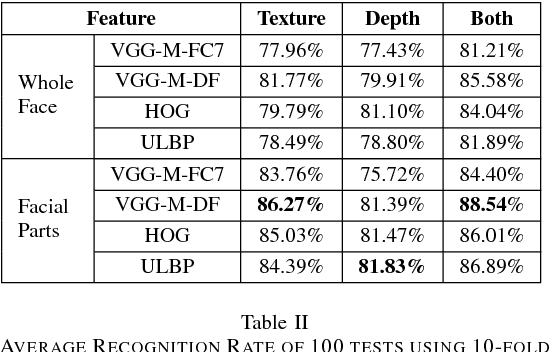
Meaningful facial parts can convey key cues for both facial action unit detection and expression prediction. Textured 3D face scan can provide both detailed 3D geometric shape and 2D texture appearance cues of the face which are beneficial for Facial Expression Recognition (FER). However, accurate facial parts extraction as well as their fusion are challenging tasks. In this paper, a novel system for 3D FER is designed based on accurate facial parts extraction and deep feature fusion of facial parts. In particular, each textured 3D face scan is firstly represented as a 2D texture map and a depth map with one-to-one dense correspondence. Then, the facial parts of both texture map and depth map are extracted using a novel 4-stage process consists of facial landmark localization, facial rotation correction, facial resizing, facial parts bounding box extraction and post-processing procedures. Finally, deep fusion Convolutional Neural Networks (CNNs) features of all facial parts are learned from both texture maps and depth maps, respectively and nonlinear SVMs are used for expression prediction. Experiments are conducted on the BU-3DFE database, demonstrating the effectiveness of combing different facial parts, texture and depth cues and reporting the state-of-the-art results in comparison with all existing methods under the same setting.