 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoTaDual: Modality-Task Dual Alignment for Enhanced Zero-shot Composed Image Retrieval
Oct 31, 2024



Composed Image Retrieval (CIR) is a challenging vision-language task, utilizing bi-modal (image+text) queries to retrieve target images. Despite the impressive performance of supervised CIR, the dependence on costly, manually-labeled triplets limits its scalability and zero-shot capability. To address this issue, zero-shot composed image retrieval (ZS-CIR) is presented along with projection-based approaches. However, such methods face two major problems, i.e., task discrepancy between pre-training (image $\leftrightarrow$ text) and inference (image+text $\rightarrow$ image), and modality discrepancy. The latter pertains to approaches based on text-only projection training due to the necessity of feature extraction from the reference image during inference. In this paper, we propose a two-stage framework to tackle both discrepancies. First, to ensure efficiency and scalability, a textual inversion network is pre-trained on large-scale caption datasets. Subsequently, we put forward Modality-Task Dual Alignment (MoTaDual) as the second stage, where large-language models (LLMs) generate triplet data for fine-tuning, and additionally, prompt learning is introduced in a multi-modal context to effectively alleviate both modality and task discrepancies. The experimental results show that our MoTaDual achieves the state-of-the-art performance across four widely used ZS-CIR benchmarks, while maintaining low training time and computational cost. The code will be released soon.
MindShot: Brain Decoding Framework Using Only One Image
May 24, 2024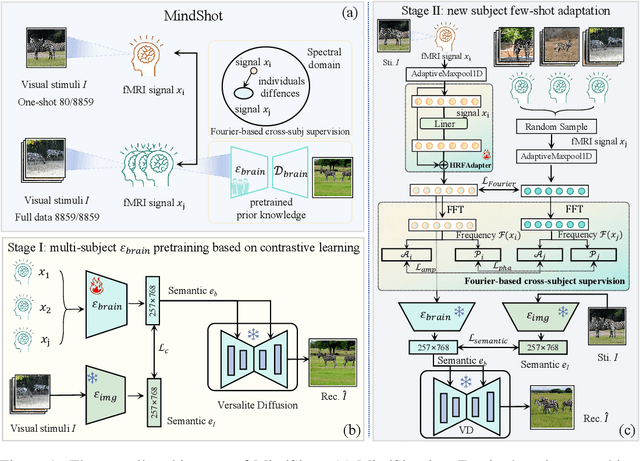
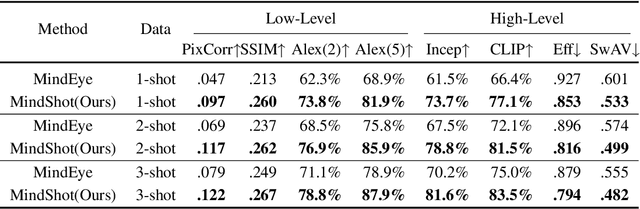
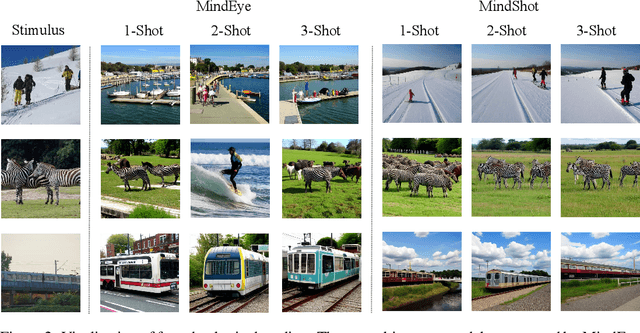
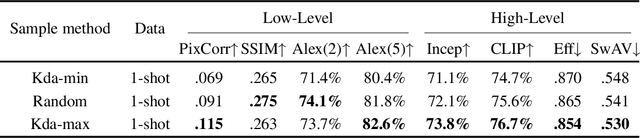
Brain decoding, which aims at reconstructing visual stimuli from brain signals, primarily utilizing functional magnetic resonance imaging (fMRI), has recently made positive progress. However, it is impeded by significant challenges such as the difficulty of acquiring fMRI-image pairs and the variability of individuals, etc. Most methods have to adopt the per-subject-per-model paradigm, greatly limiting their applications. To alleviate this problem, we introduce a new and meaningful task, few-shot brain decoding, while it will face two inherent difficulties: 1) the scarcity of fMRI-image pairs and the noisy signals can easily lead to overfitting; 2) the inadequate guidance complicates the training of a robust encoder. Therefore, a novel framework named MindShot, is proposed to achieve effective few-shot brain decoding by leveraging cross-subject prior knowledge. Firstly, inspired by the hemodynamic response function (HRF), the HRF adapter is applied to eliminate unexplainable cognitive differences between subjects with small trainable parameters. Secondly, a Fourier-based cross-subject supervision method is presented to extract additional high-level and low-level biological guidance information from signals of other subjects. Under the MindShot, new subjects and pretrained individuals only need to view images of the same semantic class, significantly expanding the model's applicability. Experimental results demonstrate MindShot's ability of reconstructing semantically faithful images in few-shot scenarios and outperforms methods based on the per-subject-per-model paradigm. The promising results of the proposed method not only validate the feasibility of few-shot brain decoding but also provide the possibility for the learning of large models under the condition of reducing data dependence.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024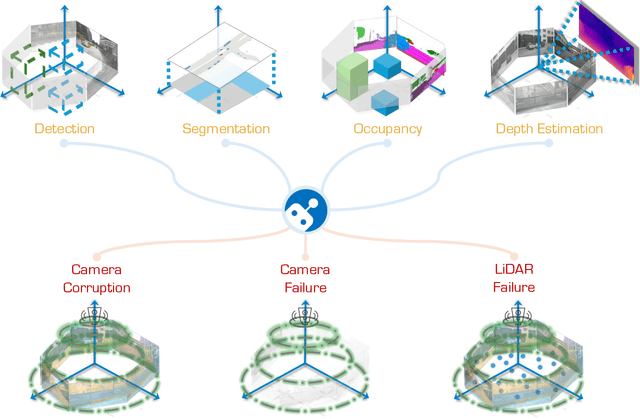


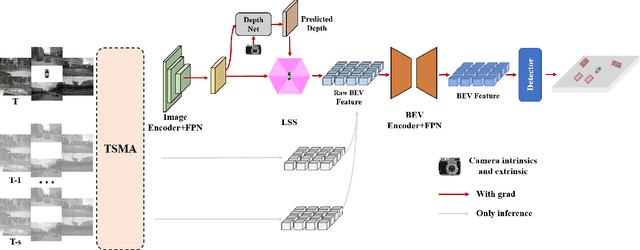
In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
Word for Person: Zero-shot Composed Person Retrieval
Nov 25, 2023



Searching for specific person has great security value and social benefits, and it often involves a combination of visual and textual information. Conventional person retrieval methods, whether image-based or text-based, usually fall short in effectively harnessing both types of information, leading to the loss of accuracy. In this paper, a whole new task called Composed Person Retrieval (CPR) is proposed to jointly utilize both image and text information for target person retrieval. However, the supervised CPR must depend on very costly manual annotation dataset, while there are currently no available resources. To mitigate this issue, we firstly introduce the Zero-shot Composed Person Retrieval (ZS-CPR), which leverages existing domain-related data to resolve the CPR problem without reliance on expensive annotations. Secondly, to learn ZS-CPR model, we propose a two-stage learning framework, Word4Per, where a lightweight Textual Inversion Network (TINet) and a text-based person retrieval model based on fine-tuned Contrastive Language-Image Pre-training (CLIP) network are learned without utilizing any CPR data. Thirdly, a finely annotated Image-Text Composed Person Retrieval dataset (ITCPR) is built as the benchmark to assess the performance of the proposed Word4Per framework. Extensive experiments under both Rank-1 and mAP demonstrate the effectiveness of Word4Per for the ZS-CPR task, surpassing the comparative methods by over 10%. The code and ITCPR dataset will be publicly available at https://github.com/Delong-liu-bupt/Word4Per.
Unleashing the Imagination of Text: A Novel Framework for Text-to-image Person Retrieval via Exploring the Power of Words
Jul 18, 2023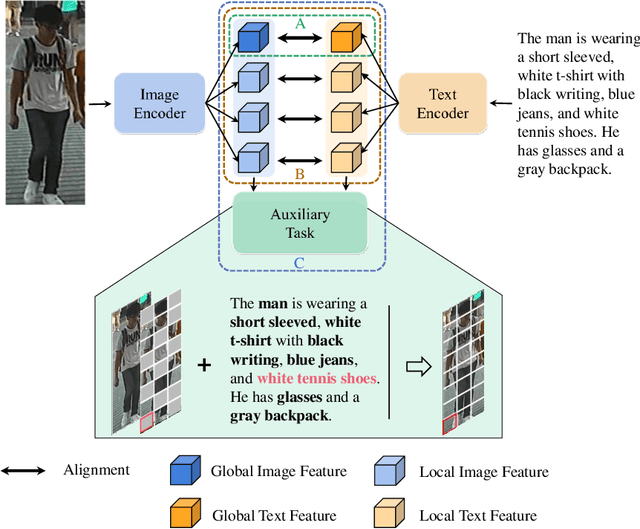
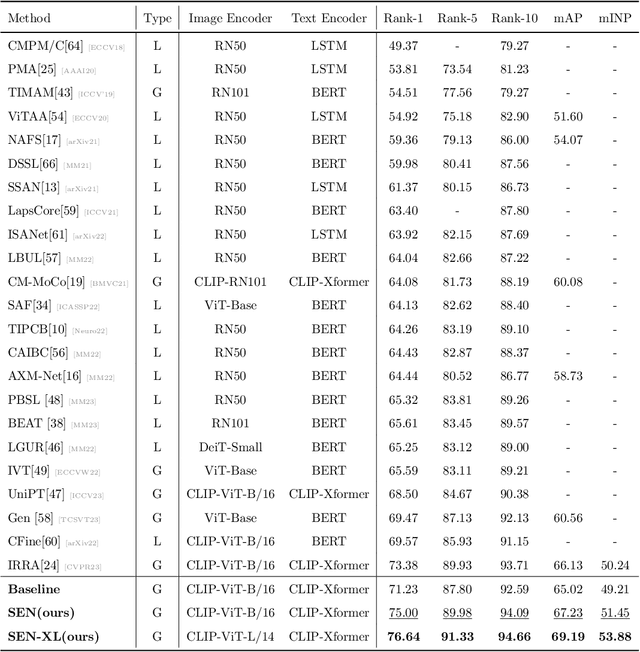
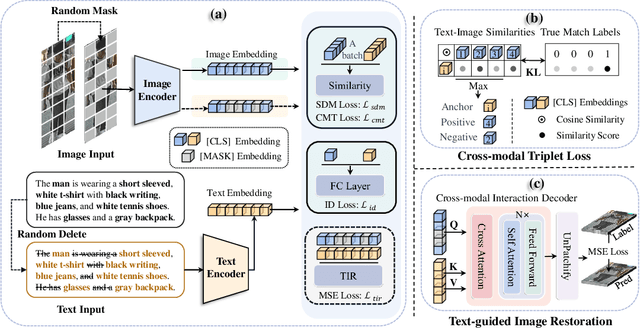
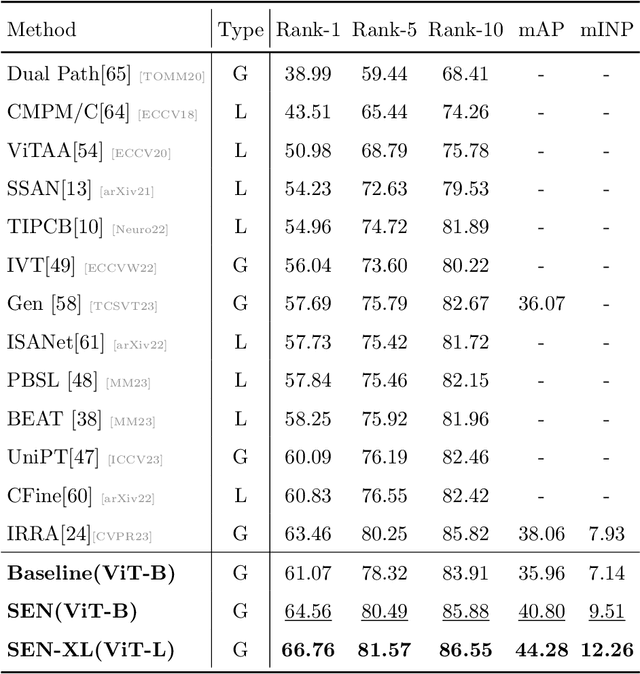
The goal of Text-to-image person retrieval is to retrieve person images from a large gallery that match the given textual descriptions. The main challenge of this task lies in the significant differences in information representation between the visual and textual modalities. The textual modality conveys abstract and precise information through vocabulary and grammatical structures, while the visual modality conveys concrete and intuitive information through images. To fully leverage the expressive power of textual representations, it is essential to accurately map abstract textual descriptions to specific images. To address this issue, we propose a novel framework to Unleash the Imagination of Text (UIT) in text-to-image person retrieval, aiming to fully explore the power of words in sentences. Specifically, the framework employs the pre-trained full CLIP model as a dual encoder for the images and texts , taking advantage of prior cross-modal alignment knowledge. The Text-guided Image Restoration auxiliary task is proposed with the aim of implicitly mapping abstract textual entities to specific image regions, facilitating alignment between textual and visual embeddings. Additionally, we introduce a cross-modal triplet loss tailored for handling hard samples, enhancing the model's ability to distinguish minor differences. To focus the model on the key components within sentences, we propose a novel text data augmentation technique. Our proposed methods achieve state-of-the-art results on three popular benchmark datasets, and the source code will be made publicly available shortly.
1st Workshop on Maritime Computer Vision 2023: Challenge Results
Nov 28, 2022

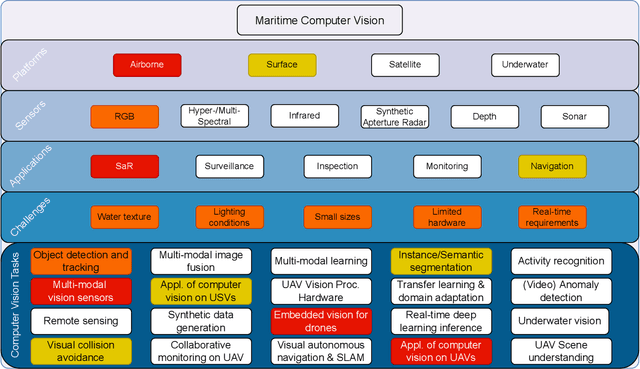
The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.