 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuon in Vision Transformers: Optimizer-Recipe Interactions and Gradient Spectra
May 23, 2026Muon is a recently developed matrix-aware optimizer that has shown strong results in transformer training, but its behavior in vision transformers (ViTs) is not yet well understood. We study Muon for ViT training, largely on ImageNet-100 and Pl@ntNet-300K, comparing against AdamW under standard vision recipes involving mixup, cutmix, smoothing, and random augmentation and erasing. Muon consistently outperforms AdamW, with especially large gains on long-tailed Pl@ntNet macro top-1. These gains are also recipe-dependent, where Muon benefits much more than AdamW from advanced and significant data augmentation techniques. To understand this interaction, we analyze the singular-value structure of matrix gradients throughout the ViT. Within Muon training runs, removing heavy data augmentation induces a late-training spectral concentration and mode collapse in gradient matrices, primarily in deep MLP-down blocks. Under a fixed "full" augmentation recipe, the clearest Muon-AdamW contrast appears instead in QKV gradients, where AdamW gradient energy remains concentrated in a much narrower basis while Muon spreads energy across substantially more singular modes. Muon in ViTs is therefore best understood as an optimizer-recipe interaction. Under a fixed recipe, Muon differs from AdamW most clearly in attention projections, where its gradients consist of a broader spectral basis. Within Muon, a full training recipe is important for preventing late spectral concentration and mode collapse in deep feedforward blocks. We further demonstrate efficacy in training ViTs on image segmentation and masked autoencoder models, where Muon outperforms AdamW in all settings considered.
OpenVTON-Bench: A Large-Scale High-Resolution Benchmark for Controllable Virtual Try-On Evaluation
Jan 30, 2026Recent advances in diffusion models have significantly elevated the visual fidelity of Virtual Try-On (VTON) systems, yet reliable evaluation remains a persistent bottleneck. Traditional metrics struggle to quantify fine-grained texture details and semantic consistency, while existing datasets fail to meet commercial standards in scale and diversity. We present OpenVTON-Bench, a large-scale benchmark comprising approximately 100K high-resolution image pairs (up to $1536 \times 1536$). The dataset is constructed using DINOv3-based hierarchical clustering for semantically balanced sampling and Gemini-powered dense captioning, ensuring a uniform distribution across 20 fine-grained garment categories. To support reliable evaluation, we propose a multi-modal protocol that measures VTON quality along five interpretable dimensions: background consistency, identity fidelity, texture fidelity, shape plausibility, and overall realism. The protocol integrates VLM-based semantic reasoning with a novel Multi-Scale Representation Metric based on SAM3 segmentation and morphological erosion, enabling the separation of boundary alignment errors from internal texture artifacts. Experimental results show strong agreement with human judgments (Kendall's $τ$ of 0.833 vs. 0.611 for SSIM), establishing a robust benchmark for VTON evaluation.
Layer-Parallel Training for Transformers
Jan 13, 2026We present a new training methodology for transformers using a multilevel, layer-parallel approach. Through a neural ODE formulation of transformers, our application of a multilevel parallel-in-time algorithm for the forward and backpropagation phases of training achieves parallel acceleration over the layer dimension. This dramatically enhances parallel scalability as the network depth increases, which is particularly useful for increasingly large foundational models. However, achieving this introduces errors that cause systematic bias in the gradients, which in turn reduces convergence when closer to the minima. We develop an algorithm to detect this critical transition and either switch to serial training or systematically increase the accuracy of layer-parallel training. Results, including BERT, GPT2, ViT, and machine translation architectures, demonstrate parallel-acceleration as well as accuracy commensurate with serial pre-training while fine-tuning is unaffected.
On the Convergence Behavior of Preconditioned Gradient Descent Toward the Rich Learning Regime
Jan 06, 2026Spectral bias, the tendency of neural networks to learn low frequencies first, can be both a blessing and a curse. While it enhances the generalization capabilities by suppressing high-frequency noise, it can be a limitation in scientific tasks that require capturing fine-scale structures. The delayed generalization phenomenon known as grokking is another barrier to rapid training of neural networks. Grokking has been hypothesized to arise as learning transitions from the NTK to the feature-rich regime. This paper explores the impact of preconditioned gradient descent (PGD), such as Gauss-Newton, on spectral bias and grokking phenomena. We demonstrate through theoretical and empirical results how PGD can mitigate issues associated with spectral bias. Additionally, building on the rich learning regime grokking hypothesis, we study how PGD can be used to reduce delays associated with grokking. Our conjecture is that PGD, without the impediment of spectral bias, enables uniform exploration of the parameter space in the NTK regime. Our experimental results confirm this prediction, providing strong evidence that grokking represents a transitional behavior between the lazy regime characterized by the NTK and the rich regime. These findings deepen our understanding of the interplay between optimization dynamics, spectral bias, and the phases of neural network learning.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
Interpretability and Generalization Bounds for Learning Spatial Physics
Jun 18, 2025While there are many applications of ML to scientific problems that look promising, visuals can be deceiving. For scientific applications, actual quantitative accuracy is crucial. This work applies the rigor of numerical analysis for differential equations to machine learning by specifically quantifying the accuracy of applying different ML techniques to the elementary 1D Poisson differential equation. Beyond the quantity and discretization of data, we identify that the function space of the data is critical to the generalization of the model. We prove generalization bounds and convergence rates under finite data discretizations and restricted training data subspaces by analyzing the training dynamics and deriving optimal parameters for both a white-box differential equation discovery method and a black-box linear model. The analytically derived generalization bounds are replicated empirically. Similar lack of generalization is empirically demonstrated for deep linear models, shallow neural networks, and physics-specific DeepONets and Neural Operators. We theoretically and empirically demonstrate that generalization to the true physical equation is not guaranteed in each explored case. Surprisingly, we find that different classes of models can exhibit opposing generalization behaviors. Based on our theoretical analysis, we also demonstrate a new mechanistic interpretability lens on scientific models whereby Green's function representations can be extracted from the weights of black-box models. Our results inform a new cross-validation technique for measuring generalization in physical systems. We propose applying it to the Poisson equation as an evaluation benchmark of future methods.
Transformer-Based Representation Learning for Robust Gene Expression Modeling and Cancer Prognosis
Apr 13, 2025Transformer-based models have achieved remarkable success in natural language and vision tasks, but their application to gene expression analysis remains limited due to data sparsity, high dimensionality, and missing values. We present GexBERT, a transformer-based autoencoder framework for robust representation learning of gene expression data. GexBERT learns context-aware gene embeddings by pretraining on large-scale transcriptomic profiles with a masking and restoration objective that captures co-expression relationships among thousands of genes. We evaluate GexBERT across three critical tasks in cancer research: pan-cancer classification, cancer-specific survival prediction, and missing value imputation. GexBERT achieves state-of-the-art classification accuracy from limited gene subsets, improves survival prediction by restoring expression of prognostic anchor genes, and outperforms conventional imputation methods under high missingness. Furthermore, its attention-based interpretability reveals biologically meaningful gene patterns across cancer types. These findings demonstrate the utility of GexBERT as a scalable and effective tool for gene expression modeling, with translational potential in settings where gene coverage is limited or incomplete.
Improving Colorectal Cancer Screening and Risk Assessment through Predictive Modeling on Medical Images and Records
Oct 13, 2024



Colonoscopy screening is an effective method to find and remove colon polyps before they can develop into colorectal cancer (CRC). Current follow-up recommendations, as outlined by the U.S. Multi-Society Task Force for individuals found to have polyps, primarily rely on histopathological characteristics, neglecting other significant CRC risk factors. Moreover, the considerable variability in colorectal polyp characterization among pathologists poses challenges in effective colonoscopy follow-up or surveillance. The evolution of digital pathology and recent advancements in deep learning provide a unique opportunity to investigate the added benefits of including the additional medical record information and automatic processing of pathology slides using computer vision techniques in the calculation of future CRC risk. Leveraging the New Hampshire Colonoscopy Registry's extensive dataset, many with longitudinal colonoscopy follow-up information, we adapted our recently developed transformer-based model for histopathology image analysis in 5-year CRC risk prediction. Additionally, we investigated various multimodal fusion techniques, combining medical record information with deep learning derived risk estimates. Our findings reveal that training a transformer model to predict intermediate clinical variables contributes to enhancing 5-year CRC risk prediction performance, with an AUC of 0.630 comparing to direct prediction. Furthermore, the fusion of imaging and non-imaging features, while not requiring manual inspection of microscopy images, demonstrates improved predictive capabilities for 5-year CRC risk comparing to variables extracted from colonoscopy procedure and microscopy findings. This study signifies the potential of integrating diverse data sources and advanced computational techniques in transforming the accuracy and effectiveness of future CRC risk assessments.
MindShot: Brain Decoding Framework Using Only One Image
May 24, 2024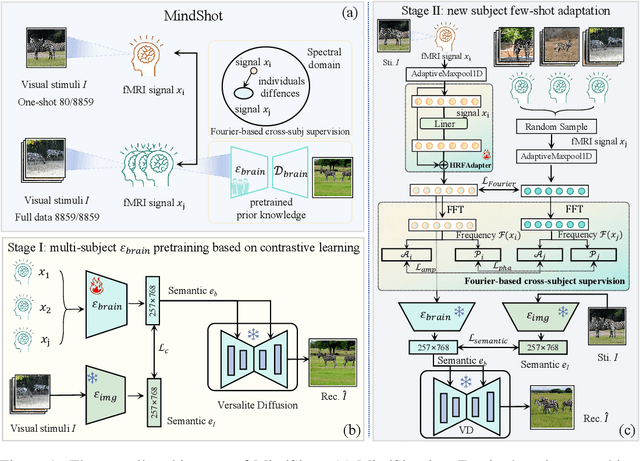
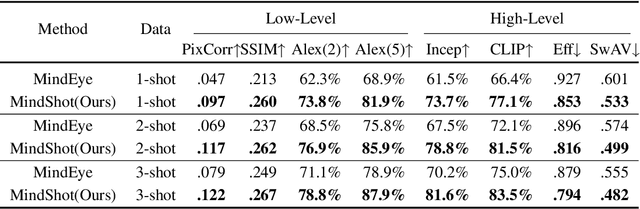
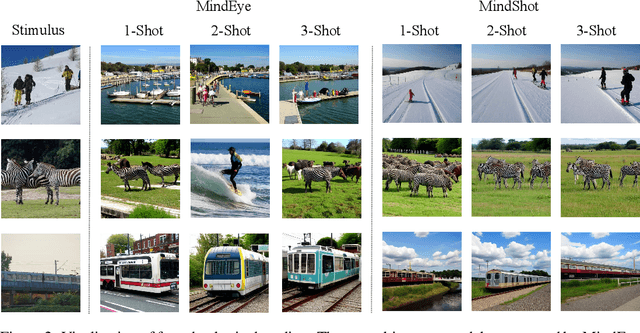
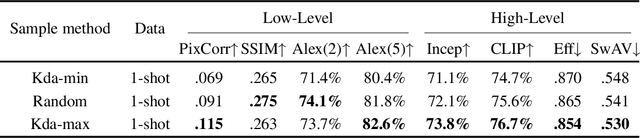
Brain decoding, which aims at reconstructing visual stimuli from brain signals, primarily utilizing functional magnetic resonance imaging (fMRI), has recently made positive progress. However, it is impeded by significant challenges such as the difficulty of acquiring fMRI-image pairs and the variability of individuals, etc. Most methods have to adopt the per-subject-per-model paradigm, greatly limiting their applications. To alleviate this problem, we introduce a new and meaningful task, few-shot brain decoding, while it will face two inherent difficulties: 1) the scarcity of fMRI-image pairs and the noisy signals can easily lead to overfitting; 2) the inadequate guidance complicates the training of a robust encoder. Therefore, a novel framework named MindShot, is proposed to achieve effective few-shot brain decoding by leveraging cross-subject prior knowledge. Firstly, inspired by the hemodynamic response function (HRF), the HRF adapter is applied to eliminate unexplainable cognitive differences between subjects with small trainable parameters. Secondly, a Fourier-based cross-subject supervision method is presented to extract additional high-level and low-level biological guidance information from signals of other subjects. Under the MindShot, new subjects and pretrained individuals only need to view images of the same semantic class, significantly expanding the model's applicability. Experimental results demonstrate MindShot's ability of reconstructing semantically faithful images in few-shot scenarios and outperforms methods based on the per-subject-per-model paradigm. The promising results of the proposed method not only validate the feasibility of few-shot brain decoding but also provide the possibility for the learning of large models under the condition of reducing data dependence.
Automatic laminectomy cutting plane planning based on artificial intelligence in robot assisted laminectomy surgery
Dec 26, 2023Objective: This study aims to use artificial intelligence to realize the automatic planning of laminectomy, and verify the method. Methods: We propose a two-stage approach for automatic laminectomy cutting plane planning. The first stage was the identification of key points. 7 key points were manually marked on each CT image. The Spatial Pyramid Upsampling Network (SPU-Net) algorithm developed by us was used to accurately locate the 7 key points. In the second stage, based on the identification of key points, a personalized coordinate system was generated for each vertebra. Finally, the transverse and longitudinal cutting planes of laminectomy were generated under the coordinate system. The overall effect of planning was evaluated. Results: In the first stage, the average localization error of the SPU-Net algorithm for the seven key points was 0.65mm. In the second stage, a total of 320 transverse cutting planes and 640 longitudinal cutting planes were planned by the algorithm. Among them, the number of horizontal plane planning effects of grade A, B, and C were 318(99.38%), 1(0.31%), and 1(0.31%), respectively. The longitudinal planning effects of grade A, B, and C were 622(97.18%), 1(0.16%), and 17(2.66%), respectively. Conclusions: In this study, we propose a method for automatic surgical path planning of laminectomy based on the localization of key points in CT images. The results showed that the method achieved satisfactory results. More studies are needed to confirm the reliability of this approach in the future.