 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlanceSeg: Real-time microaneurysm lesion segmentation with gaze-map-guided foundation model for early detection of diabetic retinopathy
Nov 14, 2023



Early-stage diabetic retinopathy (DR) presents challenges in clinical diagnosis due to inconspicuous and minute microangioma lesions, resulting in limited research in this area. Additionally, the potential of emerging foundation models, such as the segment anything model (SAM), in medical scenarios remains rarely explored. In this work, we propose a human-in-the-loop, label-free early DR diagnosis framework called GlanceSeg, based on SAM. GlanceSeg enables real-time segmentation of microangioma lesions as ophthalmologists review fundus images. Our human-in-the-loop framework integrates the ophthalmologist's gaze map, allowing for rough localization of minute lesions in fundus images. Subsequently, a saliency map is generated based on the located region of interest, which provides prompt points to assist the foundation model in efficiently segmenting microangioma lesions. Finally, a domain knowledge filter refines the segmentation of minute lesions. We conducted experiments on two newly-built public datasets, i.e., IDRiD and Retinal-Lesions, and validated the feasibility and superiority of GlanceSeg through visualized illustrations and quantitative measures. Additionally, we demonstrated that GlanceSeg improves annotation efficiency for clinicians and enhances segmentation performance through fine-tuning using annotations. This study highlights the potential of GlanceSeg-based annotations for self-model optimization, leading to enduring performance advancements through continual learning.
Label-noise-tolerant medical image classification via self-attention and self-supervised learning
Jun 16, 2023Deep neural networks (DNNs) have been widely applied in medical image classification and achieve remarkable classification performance. These achievements heavily depend on large-scale accurately annotated training data. However, label noise is inevitably introduced in the medical image annotation, as the labeling process heavily relies on the expertise and experience of annotators. Meanwhile, DNNs suffer from overfitting noisy labels, degrading the performance of models. Therefore, in this work, we innovatively devise noise-robust training approach to mitigate the adverse effects of noisy labels in medical image classification. Specifically, we incorporate contrastive learning and intra-group attention mixup strategies into the vanilla supervised learning. The contrastive learning for feature extractor helps to enhance visual representation of DNNs. The intra-group attention mixup module constructs groups and assigns self-attention weights for group-wise samples, and subsequently interpolates massive noisy-suppressed samples through weighted mixup operation. We conduct comparative experiments on both synthetic and real-world noisy medical datasets under various noise levels. Rigorous experiments validate that our noise-robust method with contrastive learning and attention mixup can effectively handle with label noise, and is superior to state-of-the-art methods. An ablation study also shows that both components contribute to boost model performance. The proposed method demonstrates its capability of curb label noise and has certain potential toward real-world clinic applications.
Eye tracking guided deep multiple instance learning with dual cross-attention for fundus disease detection
Apr 25, 2023



Deep neural networks (DNNs) have promoted the development of computer aided diagnosis (CAD) systems for fundus diseases, helping ophthalmologists reduce missed diagnosis and misdiagnosis rate. However, the majority of CAD systems are data-driven but lack of medical prior knowledge which can be performance-friendly. In this regard, we innovatively proposed a human-in-the-loop (HITL) CAD system by leveraging ophthalmologists' eye-tracking information, which is more efficient and accurate. Concretely, the HITL CAD system was implemented on the multiple instance learning (MIL), where eye-tracking gaze maps were beneficial to cherry-pick diagnosis-related instances. Furthermore, the dual-cross-attention MIL (DCAMIL) network was utilized to curb the adverse effects of noisy instances. Meanwhile, both sequence augmentation module and domain adversarial module were introduced to enrich and standardize instances in the training bag, respectively, thereby enhancing the robustness of our method. We conduct comparative experiments on our newly constructed datasets (namely, AMD-Gaze and DR-Gaze), respectively for the AMD and early DR detection. Rigorous experiments demonstrate the feasibility of our HITL CAD system and the superiority of the proposed DCAMIL, fully exploring the ophthalmologists' eye-tracking information. These investigations indicate that physicians' gaze maps, as medical prior knowledge, is potential to contribute to the CAD systems of clinical diseases.
Neural Nonnegative Matrix Factorization for Hierarchical Multilayer Topic Modeling
Feb 28, 2023We introduce a new method based on nonnegative matrix factorization, Neural NMF, for detecting latent hierarchical structure in data. Datasets with hierarchical structure arise in a wide variety of fields, such as document classification, image processing, and bioinformatics. Neural NMF recursively applies NMF in layers to discover overarching topics encompassing the lower-level features. We derive a backpropagation optimization scheme that allows us to frame hierarchical NMF as a neural network. We test Neural NMF on a synthetic hierarchical dataset, the 20 Newsgroups dataset, and the MyLymeData symptoms dataset. Numerical results demonstrate that Neural NMF outperforms other hierarchical NMF methods on these data sets and offers better learned hierarchical structure and interpretability of topics.
A Label Management Mechanism for Retinal Fundus Image Classification of Diabetic Retinopathy
Jun 23, 2021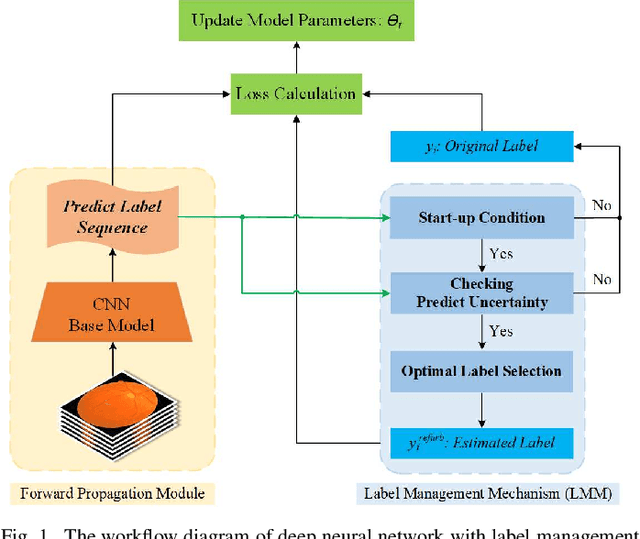
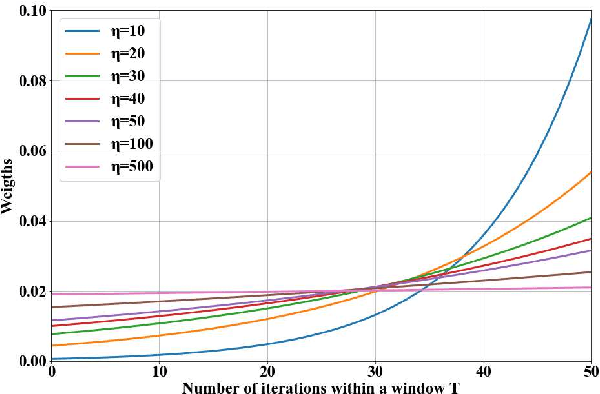
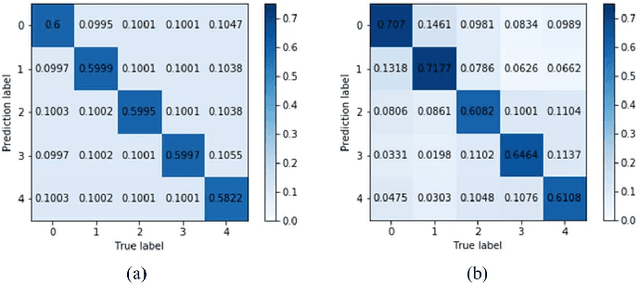
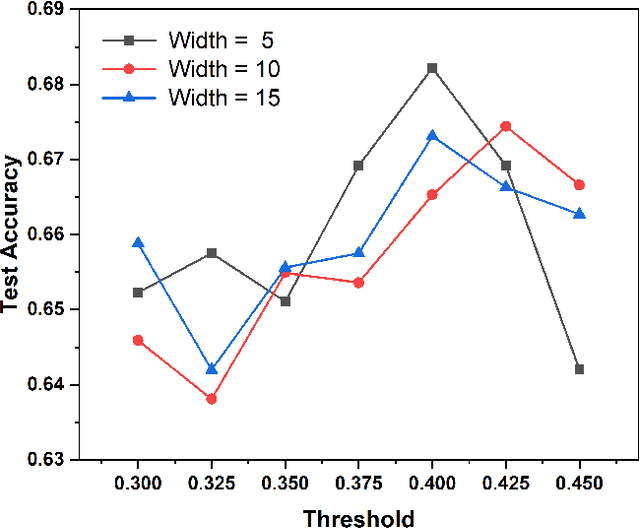
Diabetic retinopathy (DR) remains the most prevalent cause of vision impairment and irreversible blindness in the working-age adults. Due to the renaissance of deep learning (DL), DL-based DR diagnosis has become a promising tool for the early screening and severity grading of DR. However, training deep neural networks (DNNs) requires an enormous amount of carefully labeled data. Noisy label data may be introduced when labeling plenty of data, degrading the performance of models. In this work, we propose a novel label management mechanism (LMM) for the DNN to overcome overfitting on the noisy data. LMM utilizes maximum posteriori probability (MAP) in the Bayesian statistic and time-weighted technique to selectively correct the labels of unclean data, which gradually purify the training data and improve classification performance. Comprehensive experiments on both synthetic noise data (Messidor \& our collected DR dataset) and real-world noise data (ANIMAL-10N) demonstrated that LMM could boost performance of models and is superior to three state-of-the-art methods.