 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassively Scalable Inverse Reinforcement Learning in Google Maps
May 24, 2023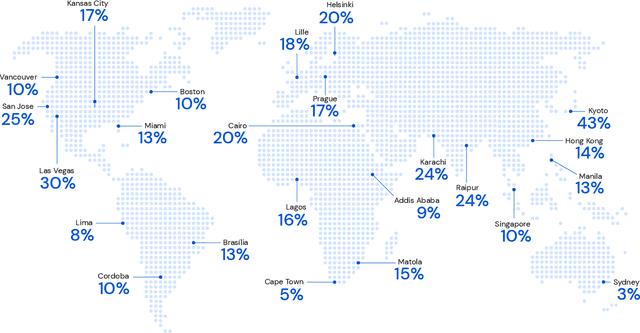
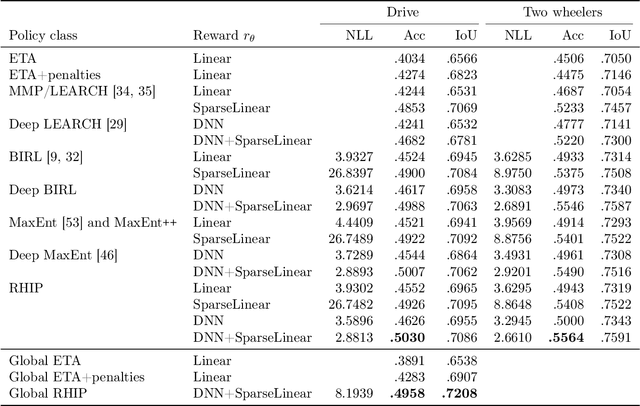
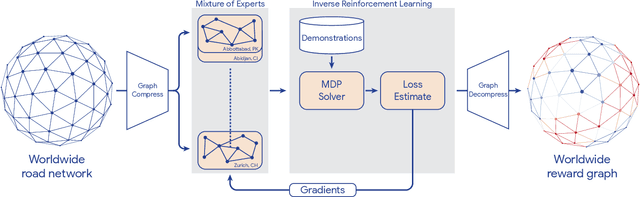

Optimizing for humans' latent preferences is a grand challenge in route recommendation, where globally-scalable solutions remain an open problem. Although past work created increasingly general solutions for the application of inverse reinforcement learning (IRL), these have not been successfully scaled to world-sized MDPs, large datasets, and highly parameterized models; respectively hundreds of millions of states, trajectories, and parameters. In this work, we surpass previous limitations through a series of advancements focused on graph compression, parallelization, and problem initialization based on dominant eigenvectors. We introduce Receding Horizon Inverse Planning (RHIP), which generalizes existing work and enables control of key performance trade-offs via its planning horizon. Our policy achieves a 16-24% improvement in global route quality, and, to our knowledge, represents the largest instance of IRL in a real-world setting to date. Our results show critical benefits to more sustainable modes of transportation (e.g. two-wheelers), where factors beyond journey time (e.g. route safety) play a substantial role. We conclude with ablations of key components, negative results on state-of-the-art eigenvalue solvers, and identify future opportunities to improve scalability via IRL-specific batching strategies.
Neural Nonnegative Matrix Factorization for Hierarchical Multilayer Topic Modeling
Feb 28, 2023We introduce a new method based on nonnegative matrix factorization, Neural NMF, for detecting latent hierarchical structure in data. Datasets with hierarchical structure arise in a wide variety of fields, such as document classification, image processing, and bioinformatics. Neural NMF recursively applies NMF in layers to discover overarching topics encompassing the lower-level features. We derive a backpropagation optimization scheme that allows us to frame hierarchical NMF as a neural network. We test Neural NMF on a synthetic hierarchical dataset, the 20 Newsgroups dataset, and the MyLymeData symptoms dataset. Numerical results demonstrate that Neural NMF outperforms other hierarchical NMF methods on these data sets and offers better learned hierarchical structure and interpretability of topics.
Inference of Media Bias and Content Quality Using Natural-Language Processing
Dec 01, 2022Media bias can significantly impact the formation and development of opinions and sentiments in a population. It is thus important to study the emergence and development of partisan media and political polarization. However, it is challenging to quantitatively infer the ideological positions of media outlets. In this paper, we present a quantitative framework to infer both political bias and content quality of media outlets from text, and we illustrate this framework with empirical experiments with real-world data. We apply a bidirectional long short-term memory (LSTM) neural network to a data set of more than 1 million tweets to generate a two-dimensional ideological-bias and content-quality measurement for each tweet. We then infer a ``media-bias chart'' of (bias, quality) coordinates for the media outlets by integrating the (bias, quality) measurements of the tweets of the media outlets. We also apply a variety of baseline machine-learning methods, such as a naive-Bayes method and a support-vector machine (SVM), to infer the bias and quality values for each tweet. All of these baseline approaches are based on a bag-of-words approach. We find that the LSTM-network approach has the best performance of the examined methods. Our results illustrate the importance of leveraging word order into machine-learning methods in text analysis.
Analysis of Legal Documents via Non-negative Matrix Factorization Methods
Apr 28, 2021The California Innocence Project (CIP), a clinical law school program aiming to free wrongfully convicted prisoners, evaluates thousands of mails containing new requests for assistance and corresponding case files. Processing and interpreting this large amount of information presents a significant challenge for CIP officials, which can be successfully aided by topic modeling techniques.In this paper, we apply Non-negative Matrix Factorization (NMF) method and implement various offshoots of it to the important and previously unstudied data set compiled by CIP. We identify underlying topics of existing case files and classify request files by crime type and case status (decision type). The results uncover the semantic structure of current case files and can provide CIP officials with a general understanding of newly received case files before further examinations. We also provide an exposition of popular variants of NMF with their experimental results and discuss the benefits and drawbacks of each variant through the real-world application.
Bias of Homotopic Gradient Descent for the Hinge Loss
Jul 26, 2019
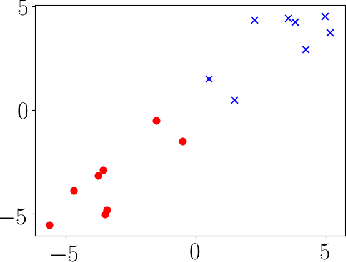
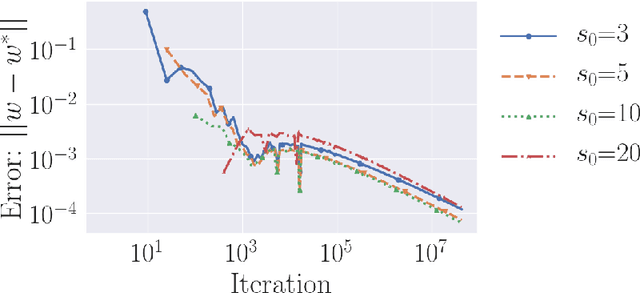
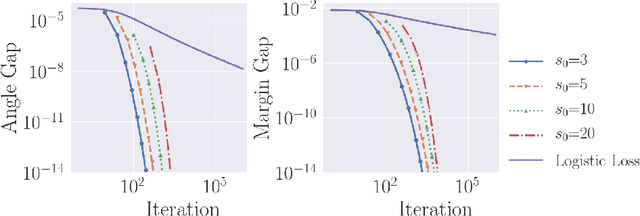
Gradient descent is a simple and widely used optimization method for machine learning. For homogeneous linear classifiers applied to separable data, gradient descent has been shown to converge to the maximal margin (or equivalently, the minimal norm) solution for various smooth loss functions. The previous theory does not, however, apply to non-smooth functions such as the hinge loss which is widely used in practice. Here, we study the convergence of a homotopic variant of gradient descent applied to the hinge loss and provide explicit convergence rates to the max-margin solution for linearly separable data.
Model Agnostic Supervised Local Explanations
Oct 27, 2018
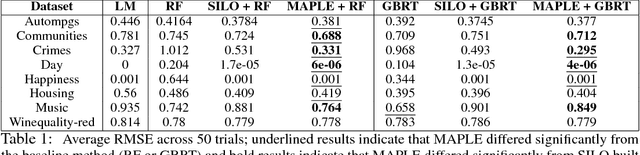

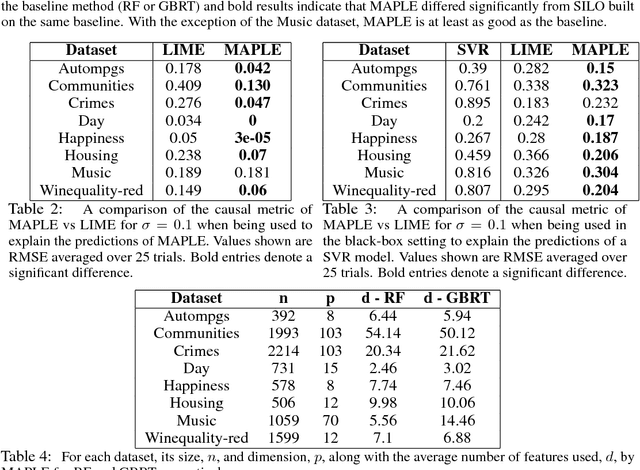
Model interpretability is an increasingly important component of practical machine learning. Some of the most common forms of interpretability systems are example-based, local, and global explanations. One of the main challenges in interpretability is designing explanation systems that can capture aspects of each of these explanation types, in order to develop a more thorough understanding of the model. We address this challenge in a novel model called MAPLE that uses local linear modeling techniques along with a dual interpretation of random forests (both as a supervised neighborhood approach and as a feature selection method). MAPLE has two fundamental advantages over existing interpretability systems. First, while it is effective as a black-box explanation system, MAPLE itself is a highly accurate predictive model that provides faithful self explanations, and thus sidesteps the typical accuracy-interpretability trade-off. Specifically, we demonstrate, on several UCI datasets, that MAPLE is at least as accurate as random forests and that it produces more faithful local explanations than LIME, a popular interpretability system. Second, MAPLE provides both example-based and local explanations and can detect global patterns, which allows it to diagnose limitations in its local explanations.
An iterative method for classification of binary data
Sep 09, 2018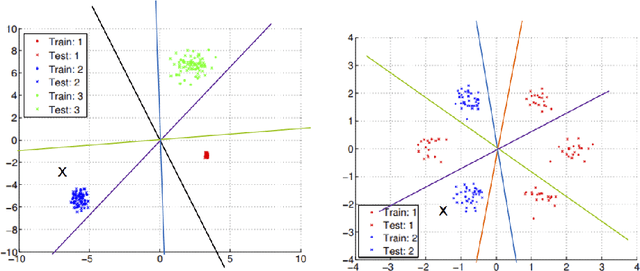

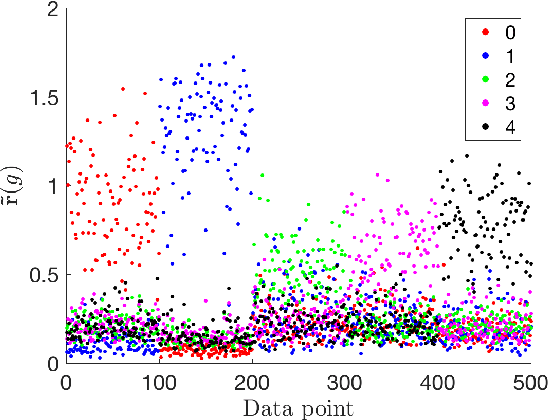
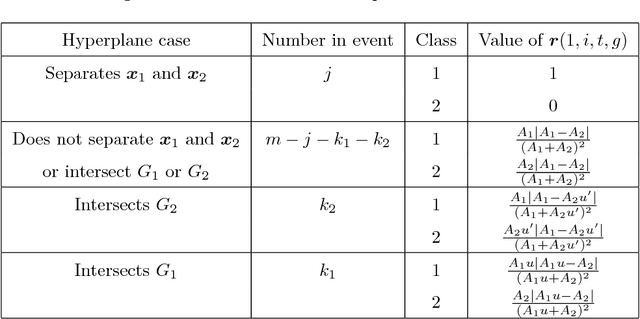
In today's data driven world, storing, processing, and gleaning insights from large-scale data are major challenges. Data compression is often required in order to store large amounts of high-dimensional data, and thus, efficient inference methods for analyzing compressed data are necessary. Building on a recently designed simple framework for classification using binary data, we demonstrate that one can improve classification accuracy of this approach through iterative applications whose output serves as input to the next application. As a side consequence, we show that the original framework can be used as a data preprocessing step to improve the performance of other methods, such as support vector machines. For several simple settings, we showcase the ability to obtain theoretical guarantees for the accuracy of the iterative classification method. The simplicity of the underlying classification framework makes it amenable to theoretical analysis and studying this approach will hopefully serve as a step toward developing theory for more sophisticated deep learning technologies.
Hierarchical Classification using Binary Data
Jul 23, 2018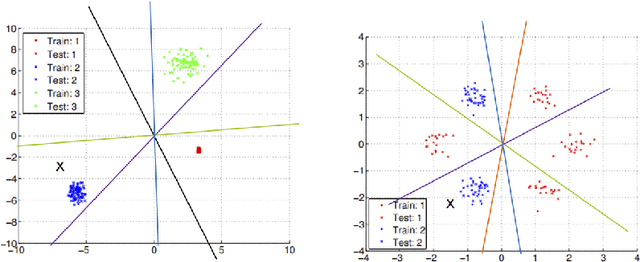

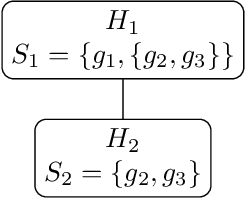
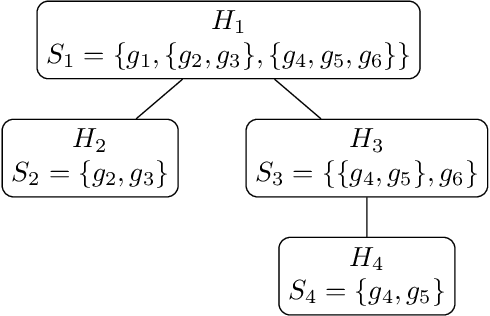
In classification problems, especially those that categorize data into a large number of classes, the classes often naturally follow a hierarchical structure. That is, some classes are likely to share similar structures and features. Those characteristics can be captured by considering a hierarchical relationship among the class labels. Here, we extend a recent simple classification approach on binary data in order to efficiently classify hierarchical data. In certain settings, specifically, when some classes are significantly easier to identify than others, we showcase computational and accuracy advantages.
Matrix Completion for Structured Observations
Jan 29, 2018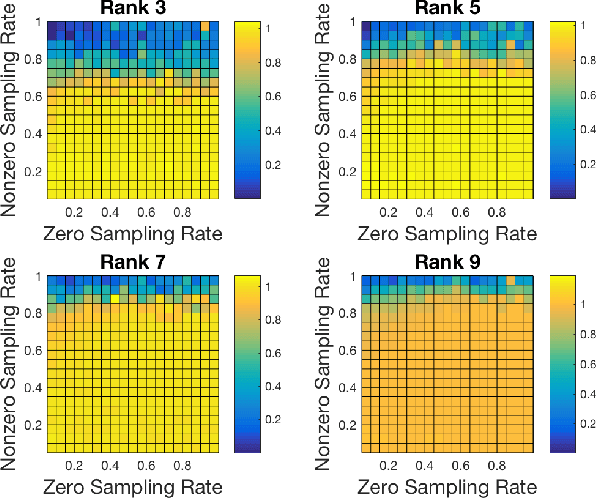
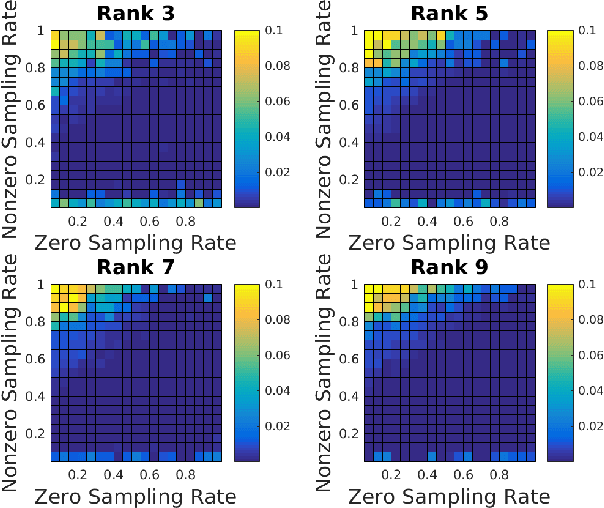
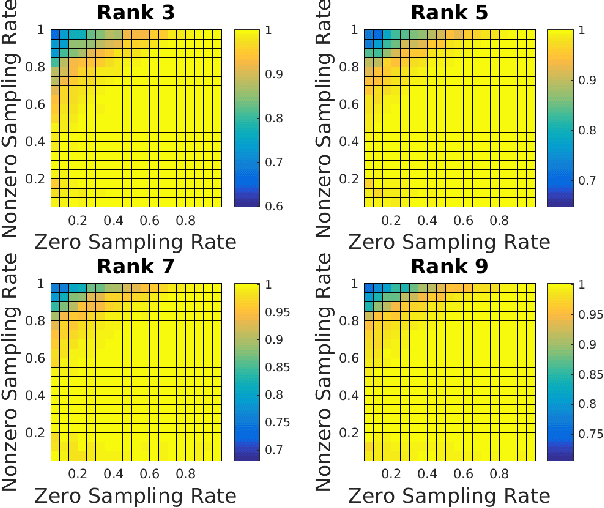
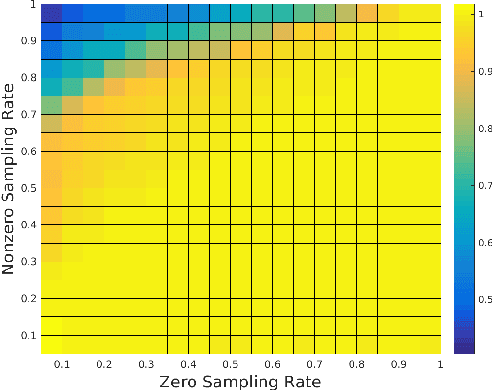
The need to predict or fill-in missing data, often referred to as matrix completion, is a common challenge in today's data-driven world. Previous strategies typically assume that no structural difference between observed and missing entries exists. Unfortunately, this assumption is woefully unrealistic in many applications. For example, in the classic Netflix challenge, in which one hopes to predict user-movie ratings for unseen films, the fact that the viewer has not watched a given movie may indicate a lack of interest in that movie, thus suggesting a lower rating than otherwise expected. We propose adjusting the standard nuclear norm minimization strategy for matrix completion to account for such structural differences between observed and unobserved entries by regularizing the values of the unobserved entries. We show that the proposed method outperforms nuclear norm minimization in certain settings.