 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference of Media Bias and Content Quality Using Natural-Language Processing
Dec 01, 2022Media bias can significantly impact the formation and development of opinions and sentiments in a population. It is thus important to study the emergence and development of partisan media and political polarization. However, it is challenging to quantitatively infer the ideological positions of media outlets. In this paper, we present a quantitative framework to infer both political bias and content quality of media outlets from text, and we illustrate this framework with empirical experiments with real-world data. We apply a bidirectional long short-term memory (LSTM) neural network to a data set of more than 1 million tweets to generate a two-dimensional ideological-bias and content-quality measurement for each tweet. We then infer a ``media-bias chart'' of (bias, quality) coordinates for the media outlets by integrating the (bias, quality) measurements of the tweets of the media outlets. We also apply a variety of baseline machine-learning methods, such as a naive-Bayes method and a support-vector machine (SVM), to infer the bias and quality values for each tweet. All of these baseline approaches are based on a bag-of-words approach. We find that the LSTM-network approach has the best performance of the examined methods. Our results illustrate the importance of leveraging word order into machine-learning methods in text analysis.
Detecting Political Biases of Named Entities and Hashtags on Twitter
Sep 16, 2022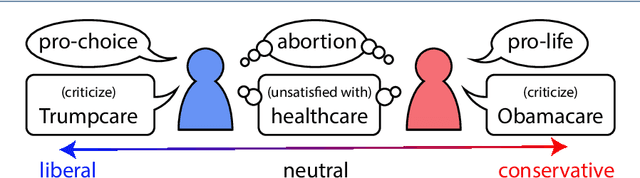

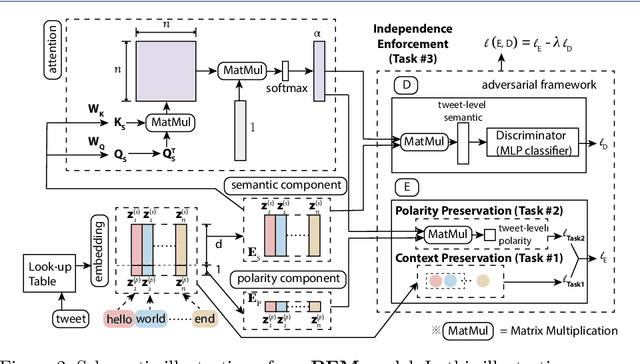
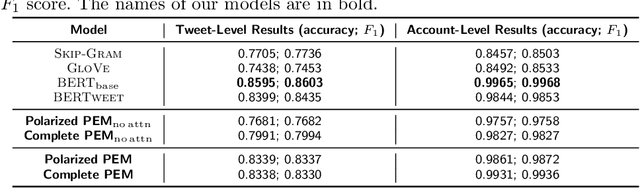
Ideological divisions in the United States have become increasingly prominent in daily communication. Accordingly, there has been much research on political polarization, including many recent efforts that take a computational perspective. By detecting political biases in a corpus of text, one can attempt to describe and discern the polarity of that text. Intuitively, the named entities (i.e., the nouns and phrases that act as nouns) and hashtags in text often carry information about political views. For example, people who use the term "pro-choice" are likely to be liberal, whereas people who use the term "pro-life" are likely to be conservative. In this paper, we seek to reveal political polarities in social-media text data and to quantify these polarities by explicitly assigning a polarity score to entities and hashtags. Although this idea is straightforward, it is difficult to perform such inference in a trustworthy quantitative way. Key challenges include the small number of known labels, the continuous spectrum of political views, and the preservation of both a polarity score and a polarity-neutral semantic meaning in an embedding vector of words. To attempt to overcome these challenges, we propose the Polarity-aware Embedding Multi-task learning (PEM) model. This model consists of (1) a self-supervised context-preservation task, (2) an attention-based tweet-level polarity-inference task, and (3) an adversarial learning task that promotes independence between an embedding's polarity dimension and its semantic dimensions. Our experimental results demonstrate that our PEM model can successfully learn polarity-aware embeddings. We examine a variety of applications and we thereby demonstrate the effectiveness of our PEM model. We also discuss important limitations of our work and stress caution when applying the PEM model to real-world scenarios.
A Non-Expert's Introduction to Data Ethics for Mathematicians
Jan 18, 2022I give a short introduction to data ethics. My focal audience is mathematicians, but I hope that my discussion will also be useful to others. I am not an expert about data ethics, and my article is only a starting point. I encourage readers to examine the resources that I discuss and to continue to reflect carefully on data ethics and on the societal implications of data and data analysis throughout their lives.
An Extension of InfoMap to Absorbing Random Walks
Dec 21, 2021
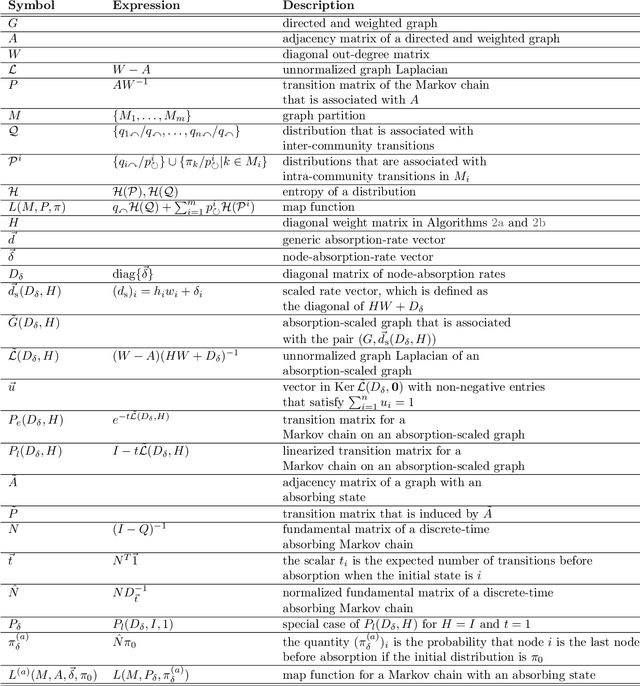
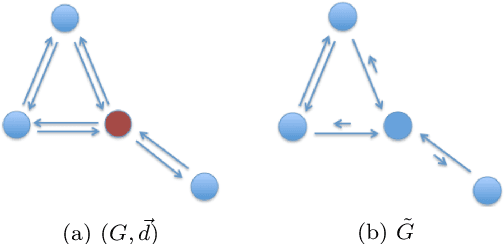
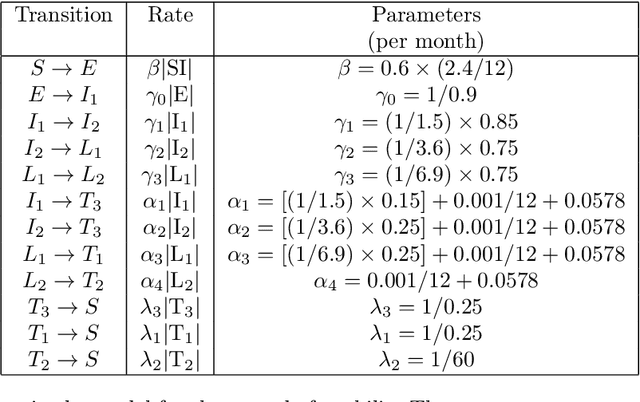
InfoMap is a popular approach for detecting densely connected "communities" of nodes in networks. To detect such communities, it builds on the standard type of Markov chain and ideas from information theory. Motivated by the dynamics of disease spread on networks, whose nodes may have heterogeneous disease-removal rates, we extend InfoMap to absorbing random walks. To do this, we use absorption-scaled graphs, in which the edge weights are scaled according to the absorption rates, along with Markov time sweeping. One of our extensions of InfoMap converges to the standard version of InfoMap in the limit in which the absorption rates approach $0$. We find that the community structure that one detects using our extensions of InfoMap can differ markedly from the community structure that one detects using methods that do not take node-absorption rates into account. Additionally, we demonstrate that the community structure that is induced by local dynamics can have important implications for susceptible-infected-recovered (SIR) dynamics on ring-lattice networks. For example, we find situations in which the outbreak duration is maximized when a moderate number of nodes have large node-absorption rates. We also use our extensions of InfoMap to study community structure in a sexual-contact network. We consider the community structure that corresponds to different absorption rates for homeless individuals in the network and the associated impact on syphilis dynamics on the network. We observe that the final outbreak size can be smaller when treatment rates are lower in the homeless population than in other populations than when they are the same in all populations.
Learning low-rank latent mesoscale structures in networks
Feb 13, 2021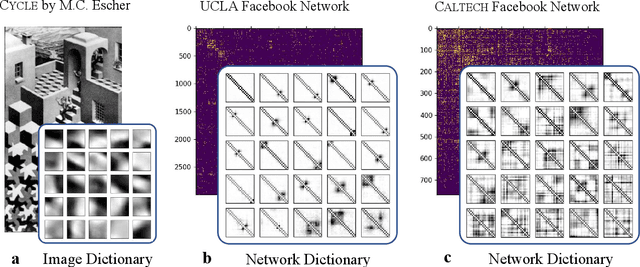
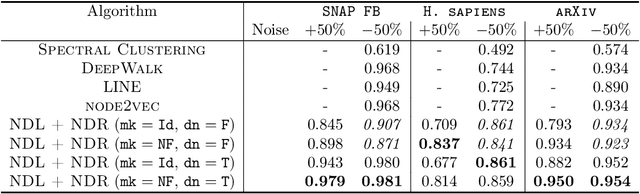

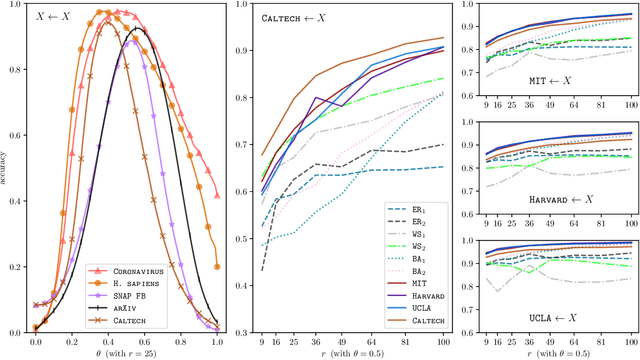
It is common to use networks to encode the architecture of interactions between entities in complex systems in the physical, biological, social, and information sciences. Moreover, to study the large-scale behavior of complex systems, it is important to study mesoscale structures in networks as building blocks that influence such behavior. In this paper, we present a new approach for describing low-rank mesoscale structure in networks, and we illustrate our approach using several synthetic network models and empirical friendship, collaboration, and protein--protein interaction (PPI) networks. We find that these networks possess a relatively small number of `latent motifs' that together can successfully approximate most subnetworks at a fixed mesoscale. We use an algorithm that we call "network dictionary learning" (NDL), which combines a network sampling method and nonnegative matrix factorization, to learn the latent motifs of a given network. The ability to encode a network using a set of latent motifs has a wide range of applications to network-analysis tasks, such as comparison, denoising, and edge inference. Additionally, using our new network denoising and reconstruction (NDR) algorithm, we demonstrate how to denoise a corrupted network by using only the latent motifs that one learns directly from the corrupted networks.
Mixed Logit Models and Network Formation
Jun 30, 2020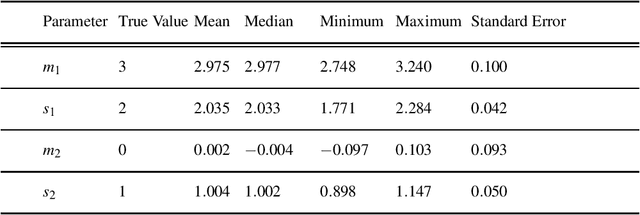
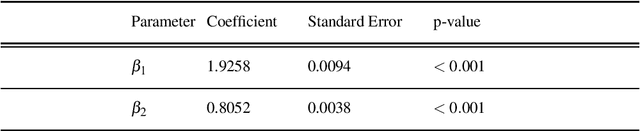
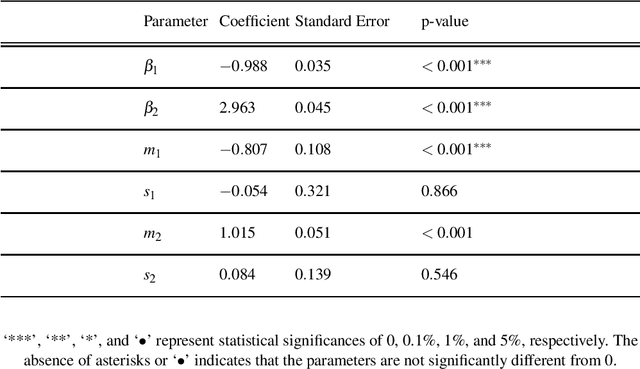
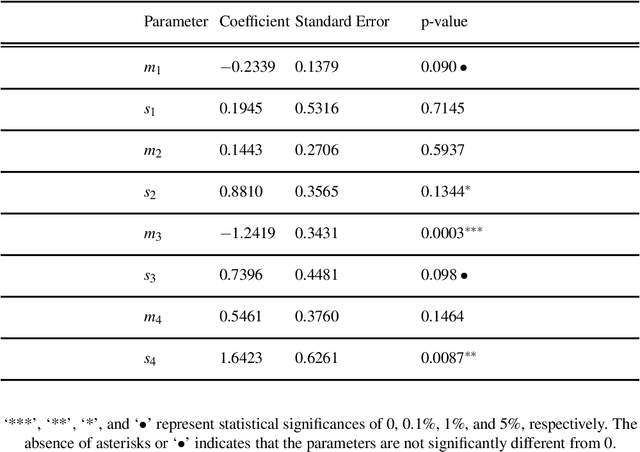
The study of network formation is pervasive in economics, sociology, and many other fields. In this paper, we model network formation as a ``choice'' that is made by nodes in a network to connect to other nodes. We study these ``choices'' using discrete-choice models, in which an agent chooses between two or more discrete alternatives. One framework for studying network formation is the multinomial logit (MNL) model. We highlight limitations of the MNL model on networks that are constructed from empirical data. We employ the ``repeated choice'' (RC) model to study network formation \cite{TrainRevelt97mixedlogit}. We argue that the RC model overcomes important limitations of the MNL model and is well-suited to study network formation. We also illustrate how to use the RC model to accurately study network formation using both synthetic and real-world networks. Using synthetic networks, we also compare the performance of the MNL model and the RC model; we find that the RC model estimates the data-generation process of our synthetic networks more accurately than the MNL model. We provide examples of qualitatively interesting questions -- the presence of homophily in a teen friendship network and the fact that new patents are more likely to cite older, more cited, and similar patents -- for which the RC model allows us to achieve insights.
Edge Correlations in Multilayer Networks
Aug 11, 2019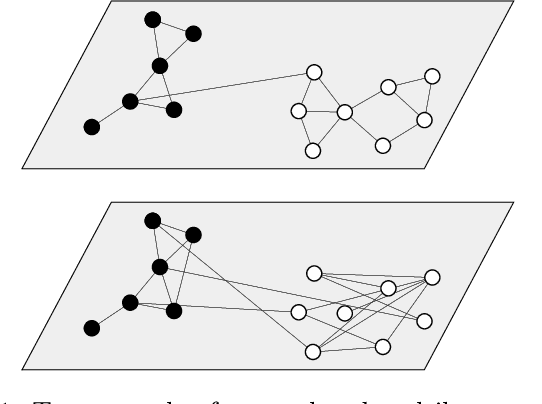
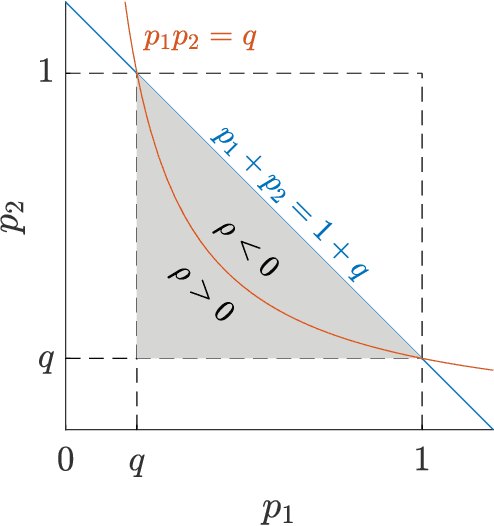
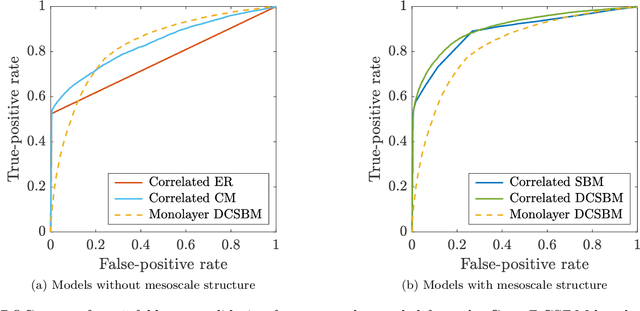
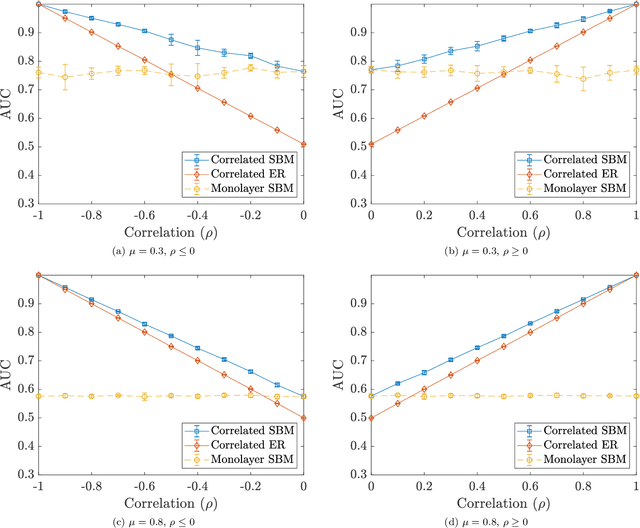
Many recent developments in network analysis have focused on multilayer networks, which one can use to encode time-dependent interactions, multiple types of interactions, and other complications that arise in complex systems. Like their monolayer counterparts, multilayer networks in applications often have mesoscale features, such as community structure. A prominent type of method for inferring such structures is the employment of multilayer stochastic block models (SBMs). A common (but inadequate) assumption of these models is the sampling of edges in different layers independently, conditioned on community labels of the nodes. In this paper, we relax this assumption of independence by incorporating edge correlations into an SBM-like model. We derive maximum-likelihood estimates of the key parameters of our model, and we propose a measure of layer correlation that reflects the similarity between connectivity patterns in different layers. Finally, we explain how to use correlated models for edge prediction in multilayer networks. By taking into account edge correlations, prediction accuracy improves both in synthetic networks and in a temporal network of shoppers who are connected to previously-purchased grocery products.
Pull out all the stops: Textual analysis via punctuation sequences
Dec 31, 2018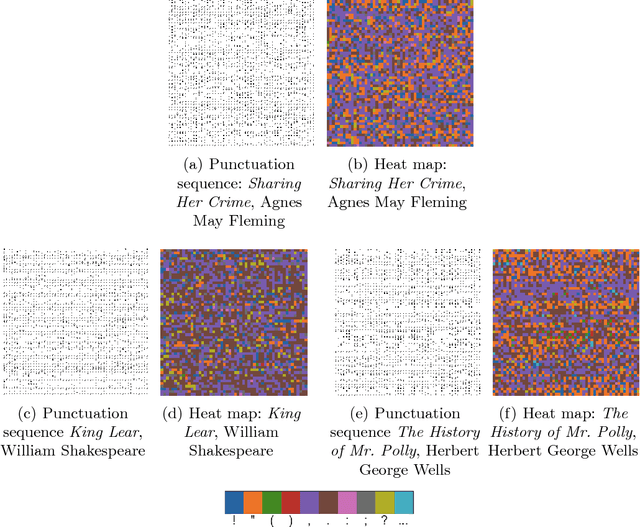
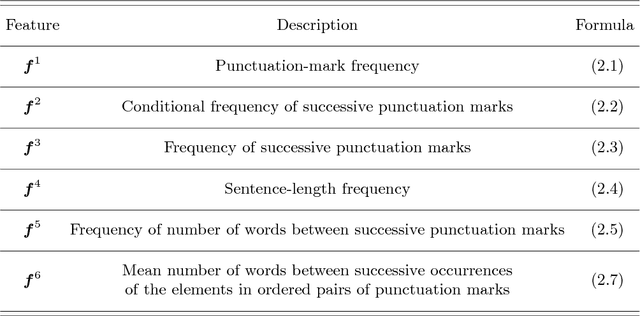
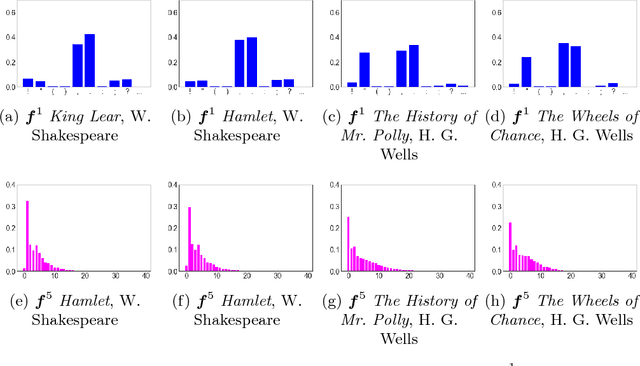
Whether enjoying the lucid prose of a favorite author or slogging through some other writer's cumbersome, heavy-set prattle (full of parentheses, em-dashes, compound adjectives, and Oxford commas), readers will notice stylistic signatures not only in word choice and grammar, but also in punctuation itself. Indeed, visual sequences of punctuation from different authors produce marvelously different (and visually striking) sequences. Punctuation is a largely overlooked stylistic feature in "stylometry'', the quantitative analysis of written text. In this paper, we examine punctuation sequences in a corpus of literary documents and ask the following questions: Are the properties of such sequences a distinctive feature of different authors? Is it possible to distinguish literary genres based on their punctuation sequences? Do the punctuation styles of authors evolve over time? Are we on to something interesting in trying to do stylometry without words, or are we full of sound and fury (signifying nothing)?
Multivariate Spatiotemporal Hawkes Processes and Network Reconstruction
Nov 15, 2018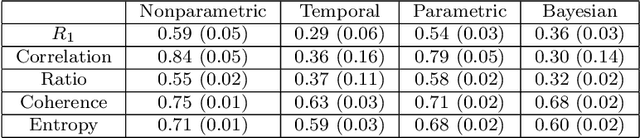
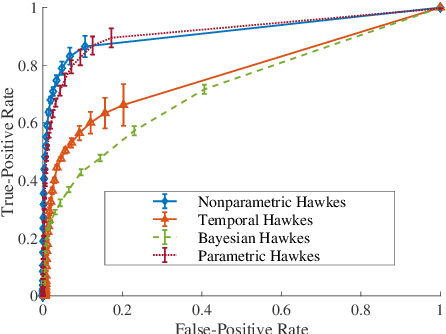
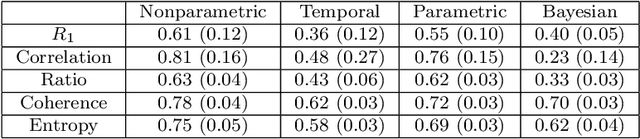
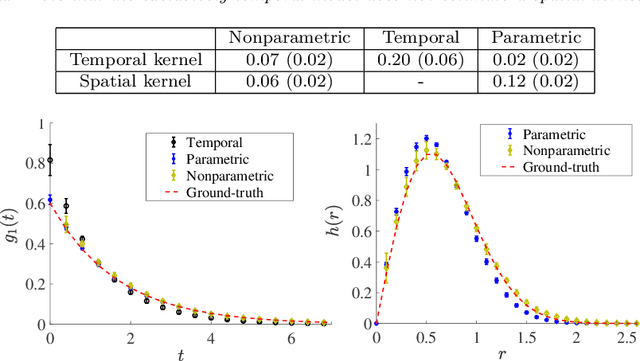
There is often latent network structure in spatial and temporal data and the tools of network analysis can yield fascinating insights into such data. In this paper, we develop a nonparametric method for network reconstruction from spatiotemporal data sets using multivariate Hawkes processes. In contrast to prior work on network reconstruction with point-process models, which has often focused on exclusively temporal information, our approach uses both temporal and spatial information and does not assume a specific parametric form of network dynamics. This leads to an effective way of recovering an underlying network. We illustrate our approach using both synthetic networks and networks constructed from real-world data sets (a location-based social media network, a narrative of crime events, and violent gang crimes). Our results demonstrate that, in comparison to using only temporal data, our spatiotemporal approach yields improved network reconstruction, providing a basis for meaningful subsequent analysis --- such as community structure and motif analysis --- of the reconstructed networks.
Stochastic Block Models are a Discrete Surface Tension
Jun 07, 2018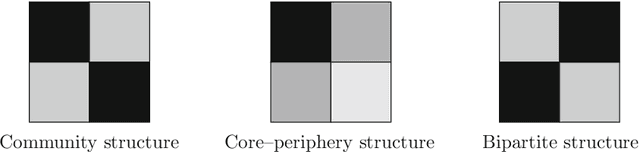
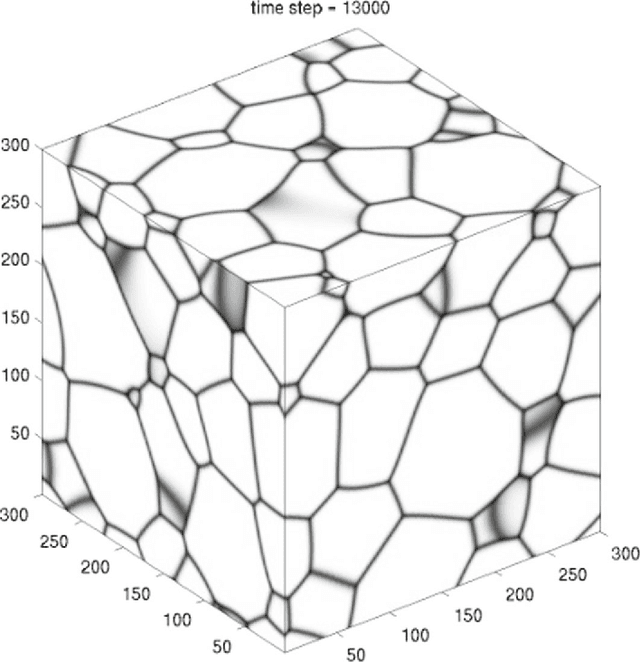
Networks, which represent agents and interactions between them, arise in myriad applications throughout the sciences, engineering, and even the humanities. To understand large-scale structure in a network, a common task is to cluster a network's nodes into sets called "communities" such that there are dense connections within communities but sparse connections between them. A popular and statistically principled method to perform such clustering is to use a family of generative models known as stochastic block models (SBMs). In this paper, we show that maximum likelihood estimation in an SBM is a network analog of a well-known continuum surface-tension problem that arises from an application in metallurgy. To illustrate the utility of this bridge, we implement network analogs of three surface-tension algorithms, with which we successfully recover planted community structure in synthetic networks and which yield fascinating insights on empirical networks from the field of hyperspectral video segmentation.