 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic benchmarking framework for LLM-based conversational data capture
Feb 04, 2025

The rapid evolution of large language models (LLMs) has transformed conversational agents, enabling complex human-machine interactions. However, evaluation frameworks often focus on single tasks, failing to capture the dynamic nature of multi-turn dialogues. This paper introduces a dynamic benchmarking framework to assess LLM-based conversational agents through interactions with synthetic users. The framework integrates generative agent simulation to evaluate performance on key dimensions: information extraction, context awareness, and adaptive engagement. By simulating various aspects of user behavior, our work provides a scalable, automated, and flexible benchmarking approach. Experimental evaluation - within a loan application use case - demonstrates the framework's effectiveness under one-shot and few-shot extraction conditions. Results show that adaptive strategies improve data extraction accuracy, especially when handling ambiguous responses. Future work will extend its applicability to broader domains and incorporate additional metrics (e.g., conversational coherence, user engagement). This study contributes a structured, scalable approach to evaluating LLM-based conversational agents, facilitating real-world deployment.
How to Data in Datathons
Sep 19, 2023

The rise of datathons, also known as data or data science hackathons, has provided a platform to collaborate, learn, and innovate in a short timeframe. Despite their significant potential benefits, organizations often struggle to effectively work with data due to a lack of clear guidelines and best practices for potential issues that might arise. Drawing on our own experiences and insights from organizing >80 datathon challenges with >60 partnership organizations since 2016, we provide guidelines and recommendations that serve as a resource for organizers to navigate the data-related complexities of datathons. We apply our proposed framework to 10 case studies.
Local2Global: A distributed approach for scaling representation learning on graphs
Jan 12, 2022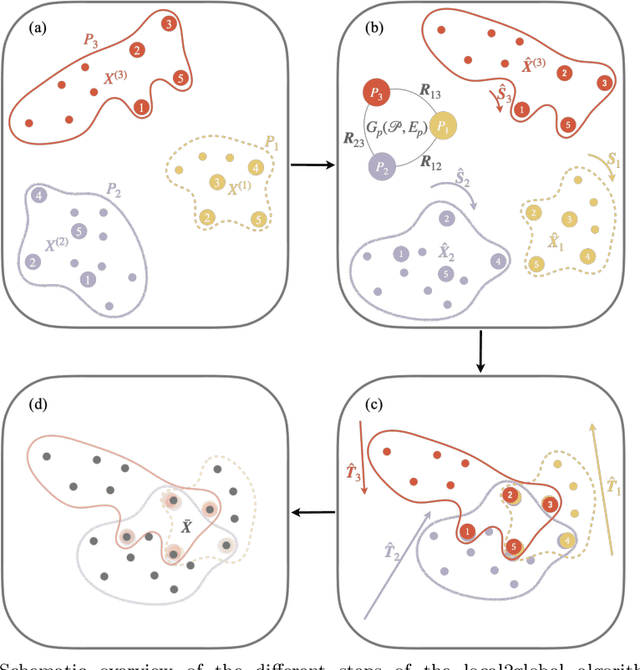

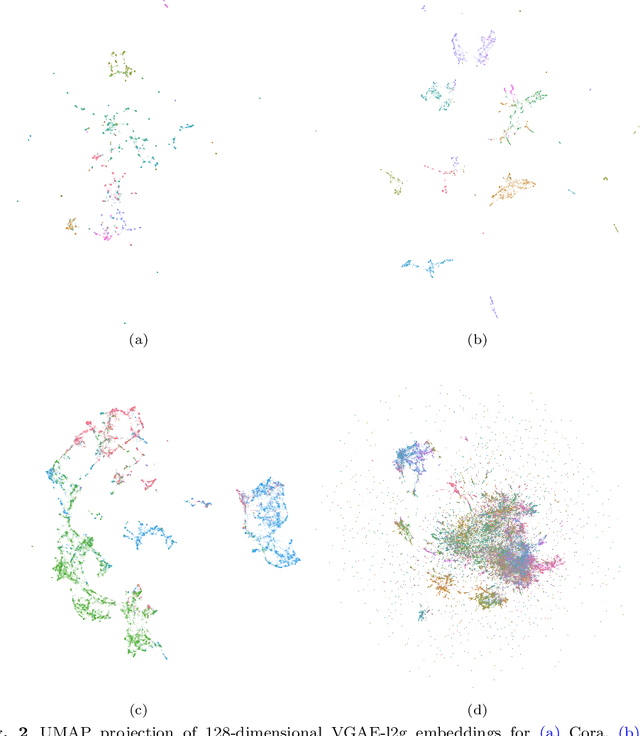
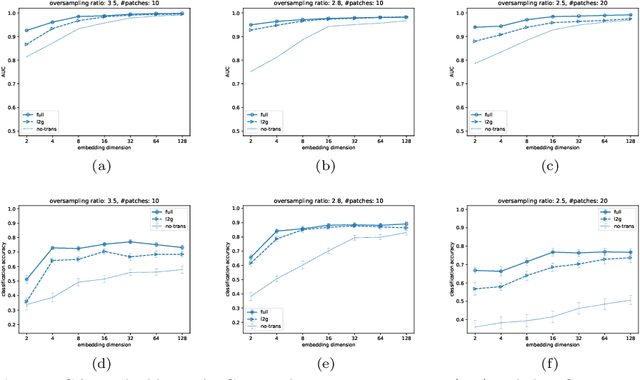
We propose a decentralised "local2global"' approach to graph representation learning, that one can a-priori use to scale any embedding technique. Our local2global approach proceeds by first dividing the input graph into overlapping subgraphs (or "patches") and training local representations for each patch independently. In a second step, we combine the local representations into a globally consistent representation by estimating the set of rigid motions that best align the local representations using information from the patch overlaps, via group synchronization. A key distinguishing feature of local2global relative to existing work is that patches are trained independently without the need for the often costly parameter synchronization during distributed training. This allows local2global to scale to large-scale industrial applications, where the input graph may not even fit into memory and may be stored in a distributed manner. We apply local2global on data sets of different sizes and show that our approach achieves a good trade-off between scale and accuracy on edge reconstruction and semi-supervised classification. We also consider the downstream task of anomaly detection and show how one can use local2global to highlight anomalies in cybersecurity networks.
Local2Global: Scaling global representation learning on graphs via local training
Jul 26, 2021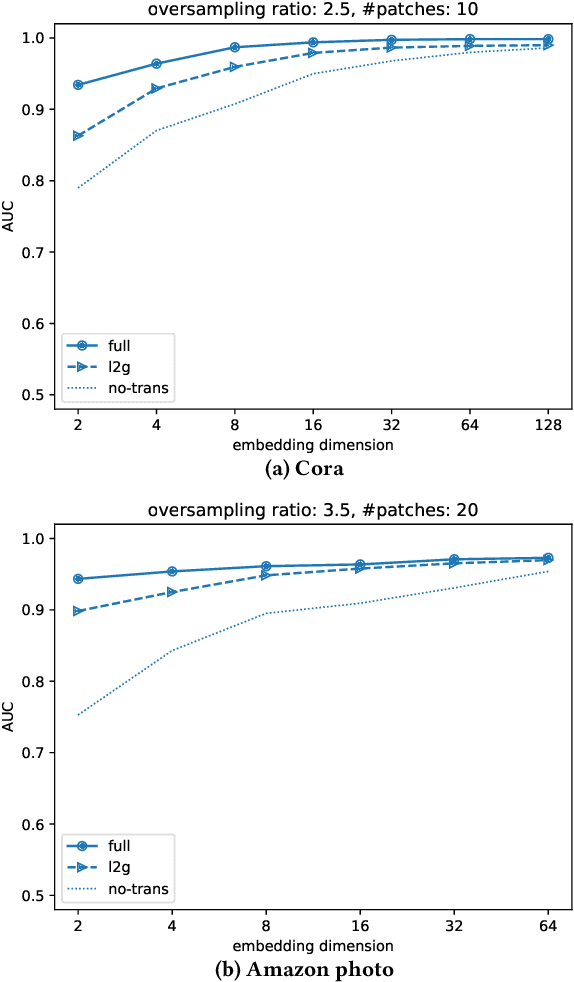
We propose a decentralised "local2global" approach to graph representation learning, that one can a-priori use to scale any embedding technique. Our local2global approach proceeds by first dividing the input graph into overlapping subgraphs (or "patches") and training local representations for each patch independently. In a second step, we combine the local representations into a globally consistent representation by estimating the set of rigid motions that best align the local representations using information from the patch overlaps, via group synchronization. A key distinguishing feature of local2global relative to existing work is that patches are trained independently without the need for the often costly parameter synchronisation during distributed training. This allows local2global to scale to large-scale industrial applications, where the input graph may not even fit into memory and may be stored in a distributed manner. Preliminary results on medium-scale data sets (up to $\sim$7K nodes and $\sim$200K edges) are promising, with a graph reconstruction performance for local2global that is comparable to that of globally trained embeddings. A thorough evaluation of local2global on large scale data and applications to downstream tasks, such as node classification and link prediction, constitutes ongoing work.
DUKweb: Diachronic word representations from the UK Web Archive corpus
Jul 02, 2021



Lexical semantic change (detecting shifts in the meaning and usage of words) is an important task for social and cultural studies as well as for Natural Language Processing applications. Diachronic word embeddings (time-sensitive vector representations of words that preserve their meaning) have become the standard resource for this task. However, given the significant computational resources needed for their generation, very few resources exist that make diachronic word embeddings available to the scientific community. In this paper we present DUKweb, a set of large-scale resources designed for the diachronic analysis of contemporary English. DUKweb was created from the JISC UK Web Domain Dataset (1996-2013), a very large archive which collects resources from the Internet Archive that were hosted on domains ending in `.uk'. DUKweb consists of a series word co-occurrence matrices and two types of word embeddings for each year in the JISC UK Web Domain dataset. We show the reuse potential of DUKweb and its quality standards via a case study on word meaning change detection.
Pull out all the stops: Textual analysis via punctuation sequences
Dec 31, 2018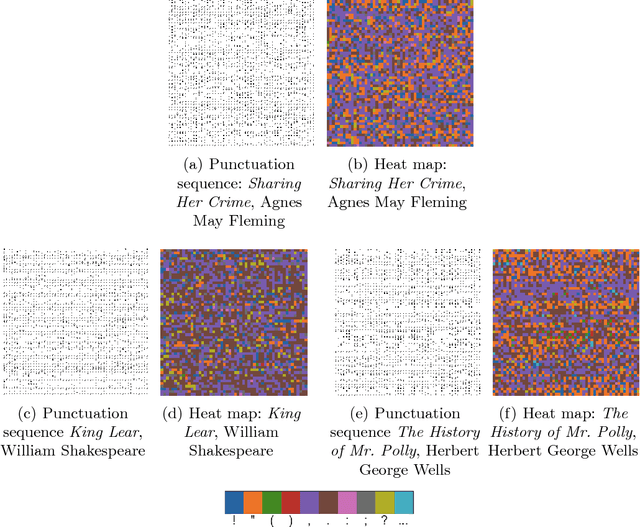
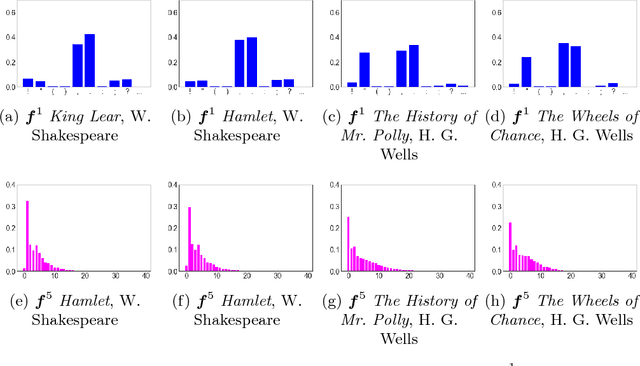
Whether enjoying the lucid prose of a favorite author or slogging through some other writer's cumbersome, heavy-set prattle (full of parentheses, em-dashes, compound adjectives, and Oxford commas), readers will notice stylistic signatures not only in word choice and grammar, but also in punctuation itself. Indeed, visual sequences of punctuation from different authors produce marvelously different (and visually striking) sequences. Punctuation is a largely overlooked stylistic feature in "stylometry'', the quantitative analysis of written text. In this paper, we examine punctuation sequences in a corpus of literary documents and ask the following questions: Are the properties of such sequences a distinctive feature of different authors? Is it possible to distinguish literary genres based on their punctuation sequences? Do the punctuation styles of authors evolve over time? Are we on to something interesting in trying to do stylometry without words, or are we full of sound and fury (signifying nothing)?