 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNamed Entity Recognition of Historical Text via Large Language Model
Aug 25, 2025Large language models have demonstrated remarkable versatility across a wide range of natural language processing tasks and domains. One such task is Named Entity Recognition (NER), which involves identifying and classifying proper names in text, such as people, organizations, locations, dates, and other specific entities. NER plays a crucial role in extracting information from unstructured textual data, enabling downstream applications such as information retrieval from unstructured text. Traditionally, NER is addressed using supervised machine learning approaches, which require large amounts of annotated training data. However, historical texts present a unique challenge, as the annotated datasets are often scarce or nonexistent, due to the high cost and expertise required for manual labeling. In addition, the variability and noise inherent in historical language, such as inconsistent spelling and archaic vocabulary, further complicate the development of reliable NER systems for these sources. In this study, we explore the feasibility of applying LLMs to NER in historical documents using zero-shot and few-shot prompting strategies, which require little to no task-specific training data. Our experiments, conducted on the HIPE-2022 (Identifying Historical People, Places and other Entities) dataset, show that LLMs can achieve reasonably strong performance on NER tasks in this setting. While their performance falls short of fully supervised models trained on domain-specific annotations, the results are nevertheless promising. These findings suggest that LLMs offer a viable and efficient alternative for information extraction in low-resource or historically significant corpora, where traditional supervised methods are infeasible.
Partial Annotation Learning for Biomedical Entity Recognition
May 22, 2023Motivation: Named Entity Recognition (NER) is a key task to support biomedical research. In Biomedical Named Entity Recognition (BioNER), obtaining high-quality expert annotated data is laborious and expensive, leading to the development of automatic approaches such as distant supervision. However, manually and automatically generated data often suffer from the unlabeled entity problem, whereby many entity annotations are missing, degrading the performance of full annotation NER models. Results: To address this problem, we systematically study the effectiveness of partial annotation learning methods for biomedical entity recognition over different simulated scenarios of missing entity annotations. Furthermore, we propose a TS-PubMedBERT-Partial-CRF partial annotation learning model. We harmonize 15 biomedical NER corpora encompassing five entity types to serve as a gold standard and compare against two commonly used partial annotation learning models, BiLSTM-Partial-CRF and EER-PubMedBERT, and the state-of-the-art full annotation learning BioNER model PubMedBERT tagger. Results show that partial annotation learning-based methods can effectively learn from biomedical corpora with missing entity annotations. Our proposed model outperforms alternatives and, specifically, the PubMedBERT tagger by 38% in F1-score under high missing entity rates. The recall of entity mentions in our model is also competitive with the upper bound on the fully annotated dataset.
An Assessment of the Impact of OCR Noise on Language Models
Jan 26, 2022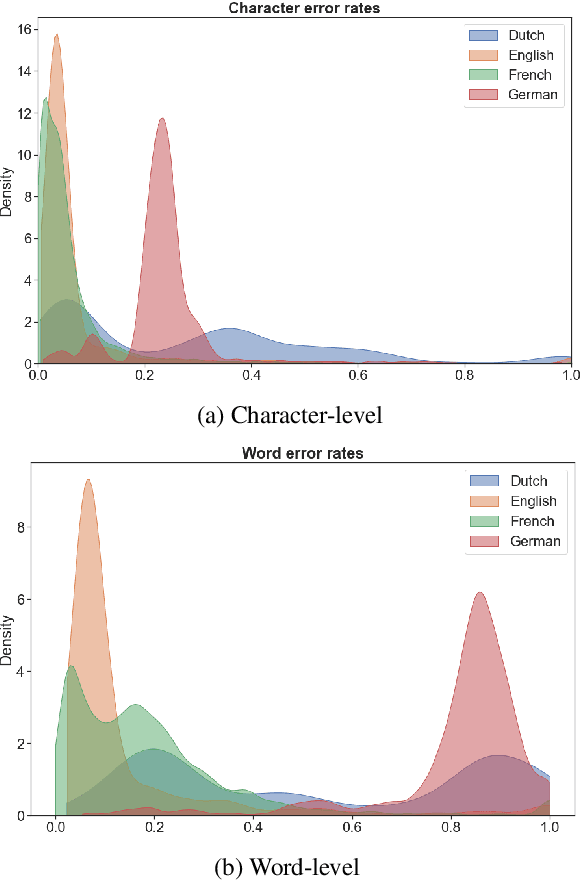
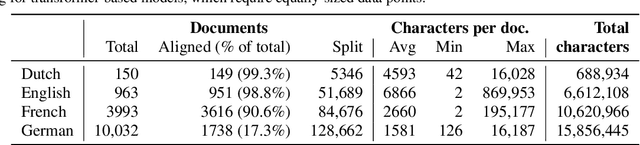
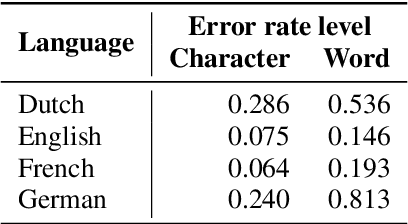
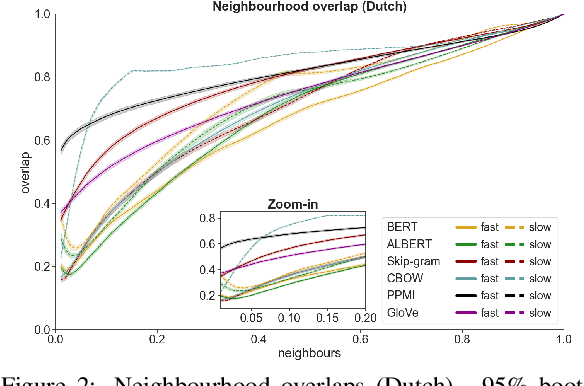
Neural language models are the backbone of modern-day natural language processing applications. Their use on textual heritage collections which have undergone Optical Character Recognition (OCR) is therefore also increasing. Nevertheless, our understanding of the impact OCR noise could have on language models is still limited. We perform an assessment of the impact OCR noise has on a variety of language models, using data in Dutch, English, French and German. We find that OCR noise poses a significant obstacle to language modelling, with language models increasingly diverging from their noiseless targets as OCR quality lowers. In the presence of small corpora, simpler models including PPMI and Word2Vec consistently outperform transformer-based models in this respect.
Local2Global: A distributed approach for scaling representation learning on graphs
Jan 12, 2022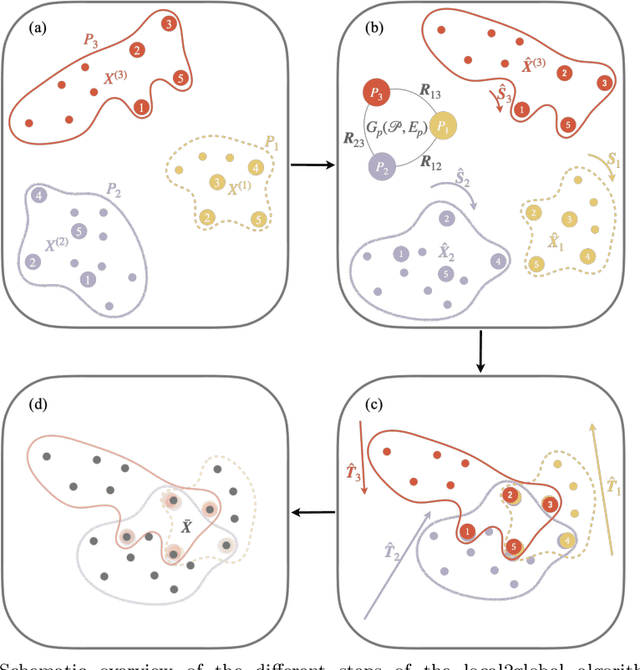

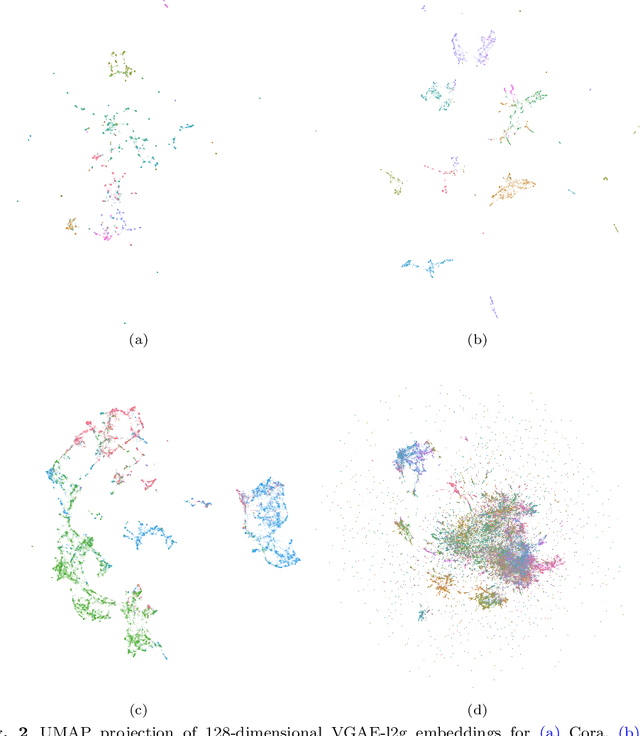
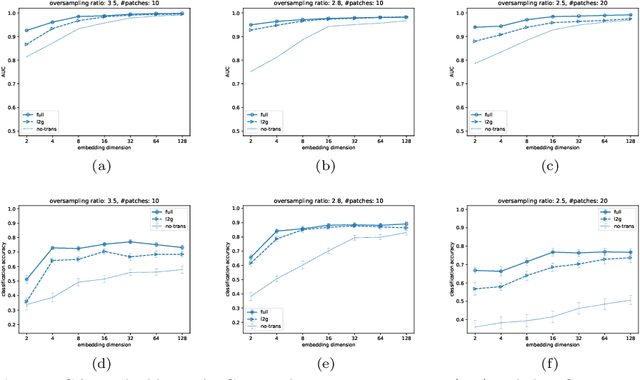
We propose a decentralised "local2global"' approach to graph representation learning, that one can a-priori use to scale any embedding technique. Our local2global approach proceeds by first dividing the input graph into overlapping subgraphs (or "patches") and training local representations for each patch independently. In a second step, we combine the local representations into a globally consistent representation by estimating the set of rigid motions that best align the local representations using information from the patch overlaps, via group synchronization. A key distinguishing feature of local2global relative to existing work is that patches are trained independently without the need for the often costly parameter synchronization during distributed training. This allows local2global to scale to large-scale industrial applications, where the input graph may not even fit into memory and may be stored in a distributed manner. We apply local2global on data sets of different sizes and show that our approach achieves a good trade-off between scale and accuracy on edge reconstruction and semi-supervised classification. We also consider the downstream task of anomaly detection and show how one can use local2global to highlight anomalies in cybersecurity networks.
Local2Global: Scaling global representation learning on graphs via local training
Jul 26, 2021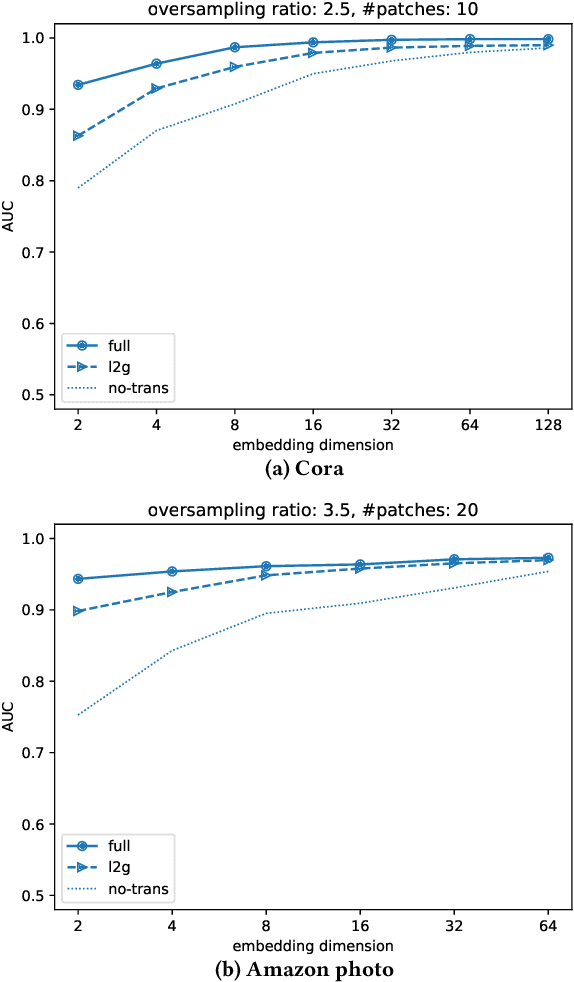
We propose a decentralised "local2global" approach to graph representation learning, that one can a-priori use to scale any embedding technique. Our local2global approach proceeds by first dividing the input graph into overlapping subgraphs (or "patches") and training local representations for each patch independently. In a second step, we combine the local representations into a globally consistent representation by estimating the set of rigid motions that best align the local representations using information from the patch overlaps, via group synchronization. A key distinguishing feature of local2global relative to existing work is that patches are trained independently without the need for the often costly parameter synchronisation during distributed training. This allows local2global to scale to large-scale industrial applications, where the input graph may not even fit into memory and may be stored in a distributed manner. Preliminary results on medium-scale data sets (up to $\sim$7K nodes and $\sim$200K edges) are promising, with a graph reconstruction performance for local2global that is comparable to that of globally trained embeddings. A thorough evaluation of local2global on large scale data and applications to downstream tasks, such as node classification and link prediction, constitutes ongoing work.
Neural Language Models for Nineteenth-Century English
May 24, 2021
We present four types of neural language models trained on a large historical dataset of books in English, published between 1760-1900 and comprised of ~5.1 billion tokens. The language model architectures include static (word2vec and fastText) and contextualized models (BERT and Flair). For each architecture, we trained a model instance using the whole dataset. Additionally, we trained separate instances on text published before 1850 for the two static models, and four instances considering different time slices for BERT. Our models have already been used in various downstream tasks where they consistently improved performance. In this paper, we describe how the models have been created and outline their reuse potential.