 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Language Models for Nineteenth-Century English
May 24, 2021
We present four types of neural language models trained on a large historical dataset of books in English, published between 1760-1900 and comprised of ~5.1 billion tokens. The language model architectures include static (word2vec and fastText) and contextualized models (BERT and Flair). For each architecture, we trained a model instance using the whole dataset. Additionally, we trained separate instances on text published before 1850 for the two static models, and four instances considering different time slices for BERT. Our models have already been used in various downstream tasks where they consistently improved performance. In this paper, we describe how the models have been created and outline their reuse potential.
A Deep Learning Approach to Geographical Candidate Selection through Toponym Matching
Sep 22, 2020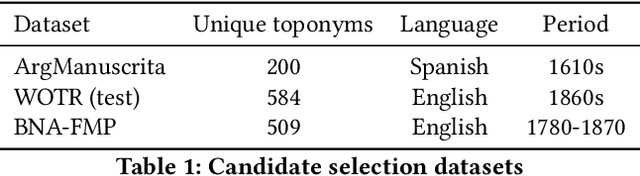
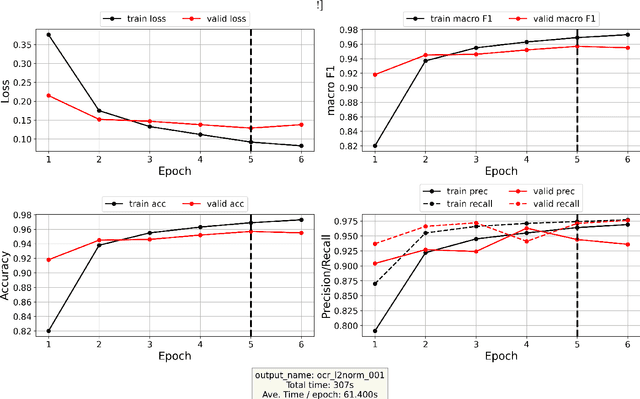
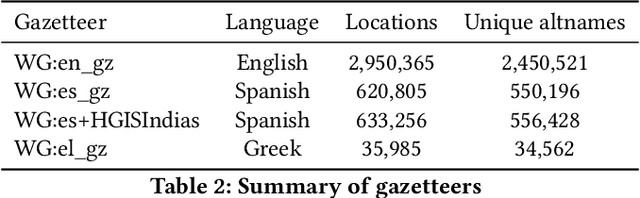
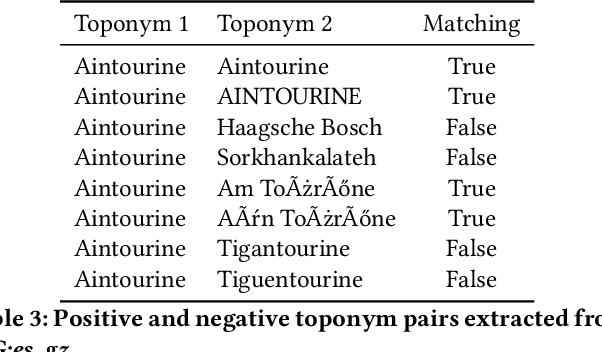
Recognizing toponyms and resolving them to their real-world referents is required for providing advanced semantic access to textual data. This process is often hindered by the high degree of variation in toponyms. Candidate selection is the task of identifying the potential entities that can be referred to by a toponym previously recognized. While it has traditionally received little attention in the research community, it has been shown that candidate selection has a significant impact on downstream tasks (i.e. entity resolution), especially in noisy or non-standard text. In this paper, we introduce a flexible deep learning method for candidate selection through toponym matching, using state-of-the-art neural network architectures. We perform an intrinsic toponym matching evaluation based on several new realistic datasets, which cover various challenging scenarios (cross-lingual and regional variations, as well as OCR errors). We report its performance on candidate selection in the context of the downstream task of toponym resolution, both on existing datasets and on a new manually-annotated resource of nineteenth-century English OCR'd text.
Living Machines: A study of atypical animacy
May 22, 2020


This paper proposes a new approach to animacy detection, the task of determining whether an entity is represented as animate in a text. In particular, this work is focused on atypical animacy and examines the scenario in which typically inanimate objects, specifically machines, are given animate attributes. To address it, we have created the first dataset for atypical animacy detection, based on nineteenth-century sentences in English, with machines represented as either animate or inanimate. Our method builds upon recent innovations in language modeling, specifically BERT contextualized word embeddings, to better capture fine-grained contextual properties of words. We present a fully unsupervised pipeline, which can be easily adapted to different contexts, and report its performance on an established animacy dataset and our newly introduced resource. We show that our method provides a substantially more accurate characterization of atypical animacy, especially when applied to highly complex forms of language use.