 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDDA-Coordinata: An Annotated Dataset of Historical Geographic Coordinates
Feb 27, 2026This paper introduces a dataset of enriched geographic coordinates retrieved from Diderot and d'Alembert's eighteenth-century Encyclopedie. Automatically recovering geographic coordinates from historical texts is a complex task, as they are expressed in a variety of ways and with varying levels of precision. To improve retrieval of coordinates from similar digitized early modern texts, we have created a gold standard dataset, trained models, published the resulting inferred and normalized coordinate data, and experimented applying these models to new texts. From 74,000 total articles in each of the digitized versions of the Encyclopedie from ARTFL and ENCCRE, we examined 15,278 geographical entries, manually identifying 4,798 containing coordinates, and 10,480 with descriptive but non-numerical references. Leveraging our gold standard annotations, we trained transformer-based models to retrieve and normalize coordinates. The pipeline presented here combines a classifier to identify coordinate-bearing entries and a second model for retrieval, tested across encoder-decoder and decoder architectures. Cross-validation yielded an 86% EM score. On an out-of-domain eighteenth-century Trevoux dictionary (also in French), our fine-tuned model had a 61% EM score, while for the nineteenth-century, 7th edition of the Encyclopaedia Britannica in English, the EM was 77%. These findings highlight the gold standard dataset's usefulness as training data, and our two-step method's cross-lingual, cross-domain generalizability.
MapReader: A Computer Vision Pipeline for the Semantic Exploration of Maps at Scale
Nov 30, 2021



We present MapReader, a free, open-source software library written in Python for analyzing large map collections (scanned or born-digital). This library transforms the way historians can use maps by turning extensive, homogeneous map sets into searchable primary sources. MapReader allows users with little or no computer vision expertise to i) retrieve maps via web-servers; ii) preprocess and divide them into patches; iii) annotate patches; iv) train, fine-tune, and evaluate deep neural network models; and v) create structured data about map content. We demonstrate how MapReader enables historians to interpret a collection of $\approx$16K nineteenth-century Ordnance Survey map sheets ($\approx$30.5M patches), foregrounding the challenge of translating visual markers into machine-readable data. We present a case study focusing on British rail infrastructure and buildings as depicted on these maps. We also show how the outputs from the MapReader pipeline can be linked to other, external datasets, which we use to evaluate as well as enrich and interpret the results. We release $\approx$62K manually annotated patches used here for training and evaluating the models.
A Deep Learning Approach to Geographical Candidate Selection through Toponym Matching
Sep 22, 2020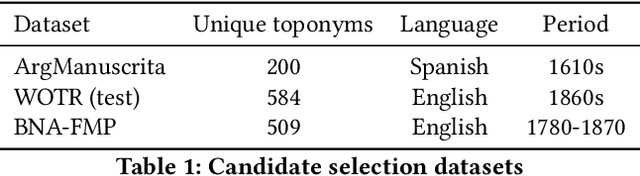
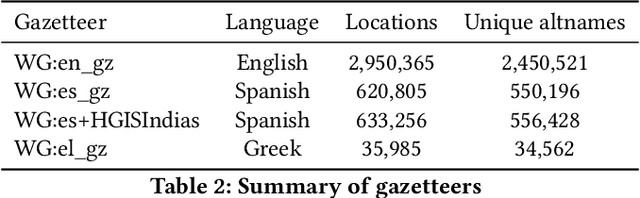
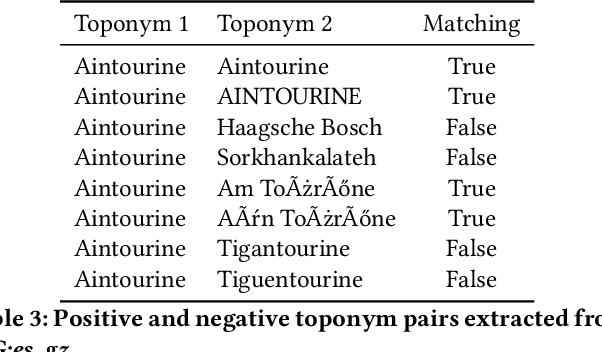
Recognizing toponyms and resolving them to their real-world referents is required for providing advanced semantic access to textual data. This process is often hindered by the high degree of variation in toponyms. Candidate selection is the task of identifying the potential entities that can be referred to by a toponym previously recognized. While it has traditionally received little attention in the research community, it has been shown that candidate selection has a significant impact on downstream tasks (i.e. entity resolution), especially in noisy or non-standard text. In this paper, we introduce a flexible deep learning method for candidate selection through toponym matching, using state-of-the-art neural network architectures. We perform an intrinsic toponym matching evaluation based on several new realistic datasets, which cover various challenging scenarios (cross-lingual and regional variations, as well as OCR errors). We report its performance on candidate selection in the context of the downstream task of toponym resolution, both on existing datasets and on a new manually-annotated resource of nineteenth-century English OCR'd text.
Living Machines: A study of atypical animacy
May 22, 2020


This paper proposes a new approach to animacy detection, the task of determining whether an entity is represented as animate in a text. In particular, this work is focused on atypical animacy and examines the scenario in which typically inanimate objects, specifically machines, are given animate attributes. To address it, we have created the first dataset for atypical animacy detection, based on nineteenth-century sentences in English, with machines represented as either animate or inanimate. Our method builds upon recent innovations in language modeling, specifically BERT contextualized word embeddings, to better capture fine-grained contextual properties of words. We present a fully unsupervised pipeline, which can be easily adapted to different contexts, and report its performance on an established animacy dataset and our newly introduced resource. We show that our method provides a substantially more accurate characterization of atypical animacy, especially when applied to highly complex forms of language use.